









在windows上面需要用到解析html的库,刚好找到了这个,虽然网上很多人都说不错,但是从10年起就不再更新了。
不过还好,我的目标也很明确,能替代我之前的采取正则表达式的方式匹配html就行了。
下来下载到,使用git下载:
git clone git://git.code.sf.net/p/htmlcxx/code htmlcxx-code
ok,拿到了源代码。用vs打开htmlcxx.vcproj(解压出来的目录中一共有两个一个是htmlcxx.vcproj,另外一个是htmlcxxapp.vcproj,另外一个是一个测试项目,不过这里不分析他,而根据我自己的用途,写另外一个更有针对性的demo)。
执行编译出来之后
出现:
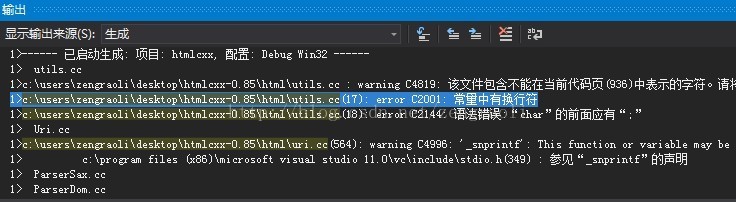
双击找到错误的地方,把
const char *signature = "";修改成:
const char *signature = "\xEF\xBB\xBF";看到编译成功

在上一级目录中找到输出的lib,和目录中的html文件夹一起考到我们新建的工程AnalysisHtml中
设置代码生成为:

main的代码如下:
// AnalysisHtml.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <string.h>
#include <iostream>
#include "html/ParserDom.h"
#include "html/utils.h"
using namespace std;
using namespace htmlcxx;
void UseHtmlCxxAnalysisHtmlStringTestCase()
{
//解析一段Html代码
string html ="<html><body>测试文字</body></html>";
// string html ="<html><body>测试文字</html>";
// string html ="<html><body>测试文字</body</html>";
// string html ="<html>测试文字</body></html>";
HTML::ParserDom parser;
tree<HTML::Node> dom = parser.parseTree(html);
//输出整棵DOM树
cout<< dom << endl;
//输出树中所有的超链接节点
tree<HTML::Node>::iterator it = dom.begin();
tree<HTML::Node>::iterator end = dom.end();
for(; it != end; ++it)
{
// _stricmp()函数,在linux下用strcasecmp()函数替换
if (_stricmp(it->tagName().c_str(), "A") == 0)
{
it->parseAttributes();
cout <<it->attribute("href").second << endl;
}
}
//输出所有的文本节点
it = dom.begin();
end = dom.end();
for(; it != end; ++it)
{
if ((!it->isTag()) && (!it->isComment()))
{
cout << it->text();
}
}
cout << endl;
}
int _tmain(int argc, _TCHAR* argv[])
{
UseHtmlCxxAnalysisHtmlStringTestCase();
return 0;
}
执行这段程序之后,效果如下:
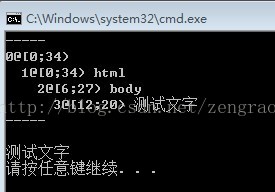
可以看到两个各个标签被解析出来了,还分了层次;
测试时,使用了还有另外三个html作为测试,都是不完整的html标签,还是能得到一个不错的效果
最后说一下,为什么不用libxm2用htmlcxx
我也试用了一下libxm2(当然网上说libxm2也很好很好云云),不过用起来,还要和zlib、iconv的版本一致才行,否则会出现各种问题,因此就放弃不用了。














 1820
1820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









