










概述
本文描述了kafka broker API层的实现原理。
API层主要用来处理kafka客户端发送过来的请求,或者把请求发送给对应的处理子系统,并把处理结果返回给客户端。
也可以查看这篇文章来了解API层的功能。
API层的启动和初始化
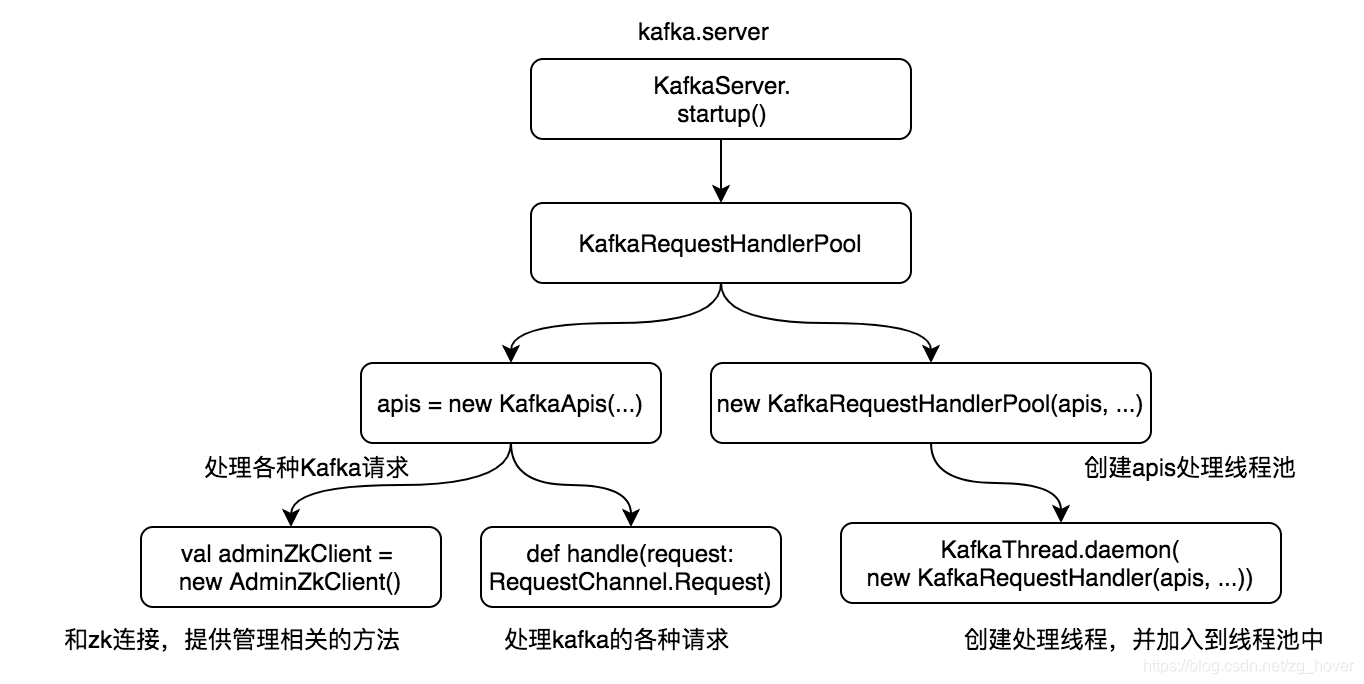
上图是kafka API层的启动和初始化过程,可以看到,API层是通过一个线程池来实现的,该线程池也可以通过修改server.properties文件中的配置参数:
num.io.threads
来指定线程池的线程个数。默认的线程个数是8。
API层请求数据流
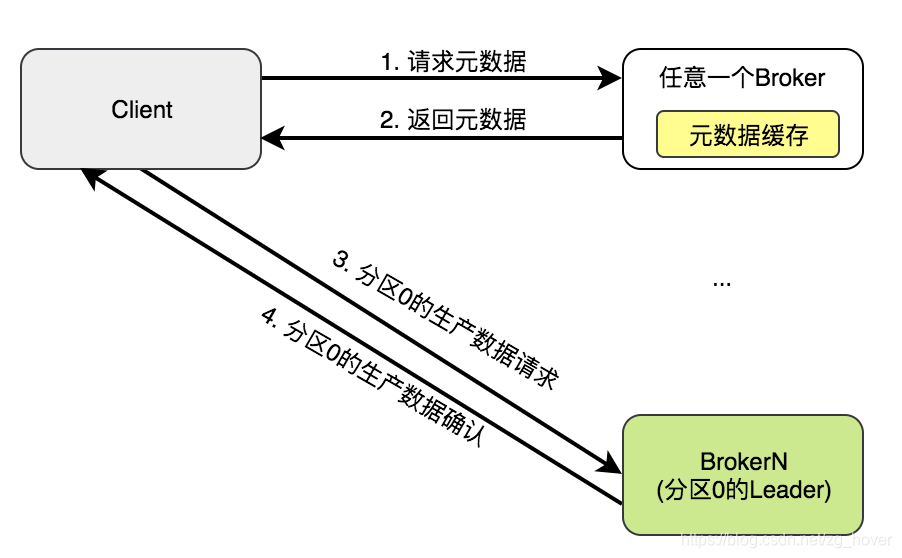
不管客户端是发起的:生产指令还是消费指令,都会先向Broker获取元数据信息,从而得知要操作分区的Leader所在的Broker。由于元数据会及时的在各个Borker之间进行同步,所以客户端可以向任意一个Broker发起请求,而得到最新的元数据信息。
元数据信息中包括了broker集群,topic和分区信息。客户端会缓存元数据的信息,当下一次发起请求时,将直接发送给分区的Leader,若此时分区的Leader发生了变化,则会接收到错误,此时,客户端会更新自己的元数据信息到最新版本。
获取到元数据之后,就可以直接和分区的Leader建立连接,发起指令。如下图所示:
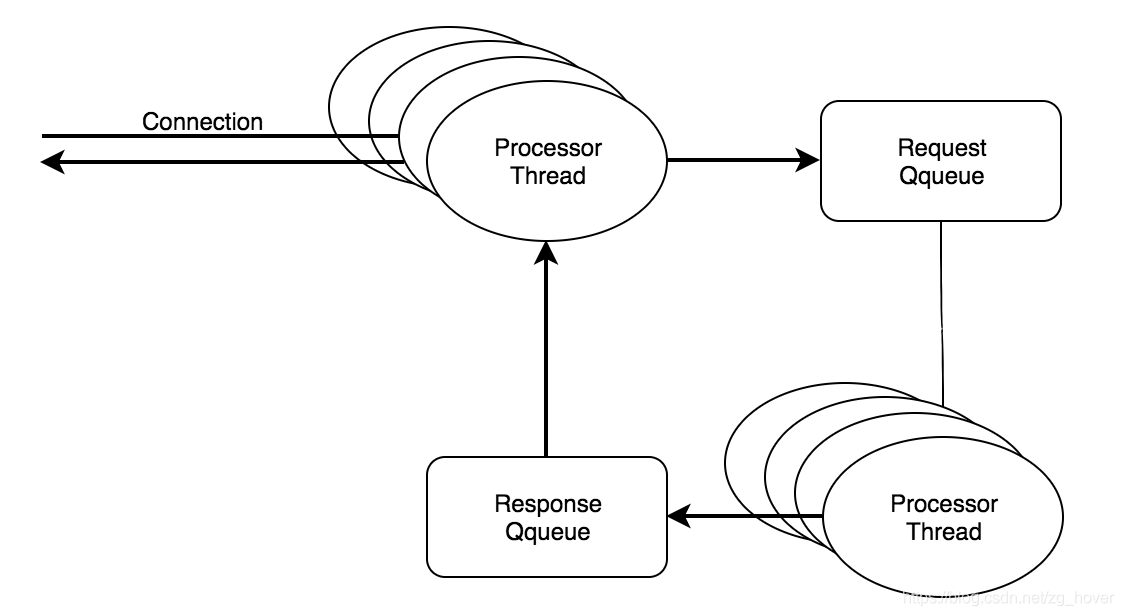
API层请求处理总体架构
总结
本文介绍了API层处理消息的总体框架,而具体的消息处理和客户端的类型密切相关,客户端可能是生产者,也可能是消费者。
接下来的文章会先分析生产者,然后讲解生产者的消息处理原理,再分析消费者,然后讲解消费者相关的消息处理原理。基于生产者和消费者原理分基础上再来分析broker的消息处理机制。














 2890
2890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









