源码分析-深入浅出Spark原理
 关注
关注
 分享
分享
文章平均质量分 84
使用通俗容易理解的语言来讲解Spark的实现原理,并试图把一个一个的功能点分析透。
一 铭
公众号:大数据架构师修行之路
展开
-
SparkSQL实现原理-DataSet缓存的实现
本文介绍了SparkSQL中Dataset缓存的具体实现原理。可见,对于Dataset的缓存只是生成了一个逻辑计划,当执行action算子实际计算数据才会计算并缓存数据。原创 2022-09-02 07:22:44 · 769 阅读 · 0 评论 -
Spark任务调度概述
Spark任务调度概述本文讲述了Spark任务调度的实现框架,概要分析了Spark从Job提交到Task创建并提交给Worker的整个过程。并对Spark任务调度相关的概念进行了介绍。任务调度总体流程从设计层面来说,Spark把任务的执行过程划分成多个阶段,每个阶段由一个处理对象来进行处理,并把处理完成的结果传递个下一个处理对象进行处理。这个过程如下图1所示:原创 2021-01-06 06:32:47 · 384 阅读 · 0 评论 -
Spark sql实战--如何比较两个dataframe是否相等
说明Spark并没有提供比较两个dataframe是否相等的函数,所以,需要通过现有的函数来完成任务。但不同方式的性能有很大不同。这里提供4种方式来比较两个Dataframe是否相等,可以根据不同的场景来选择使用。实现方案对于小的dataframe,可以直接collect回来,然后比较。(1)先检查表结构是否相等;(2)确保df1,df2,df3没有重复行 ,使用intersect,并查看其count数是否和df的count数相等使用subtract函数可以通过subtract函数原创 2021-01-05 14:16:24 · 4760 阅读 · 0 评论 -
Spark内存数据存储(MemoryStore)的实现原理
在Spark中根据存储级别可以把块数据保存到磁盘或内存中,同时还可以选择按序列化或非序列化的形式保存。MemoryStore类实现了一个简单的基于块数据的内存数据库,用来管理需要写入到内存中的块数据。可以按序列化或非序列化的形式存放块数据,存放这两种块数据的数据结构是不同的,但都必须实现MemoryEntry这个接口。也就是说:MemoryStore管理的是以MemoryEntry为父接口的内存对象。MemoryStore如何管理这些MemoryEntry对象呢?在当前版本,MemoryStore通过一原创 2021-01-04 07:32:07 · 685 阅读 · 0 评论 -
Spark2原理分析--BlockManager存储管理框架概述
BlockManager存储管理框架概述我们知道Spark的RDD有多种存储级别,每种存储级别会决定RDD存储的位置(内存还是磁盘)和存储的形式(是否序列化)和存储的行为(是否需要副本)。那么,但RDD需要存储的时候,Spark是如何实现的呢?Spark构建了一套自己的数据存储管理体系。通过这套存储体系Spark实现了内存,磁盘的数据存储,同时可以把数据保存在本地,或通过数据传输服务保存到远端。需要获取数据时,也可从内存或磁盘中获取,同时可以从本地或远端获取数据。这套存储体系是通过BlockMange原创 2021-01-02 09:42:47 · 328 阅读 · 1 评论 -
Spark原理分析--统一内存管理的实现
本文从源码角度分析spark统一内存管理的实现原理。统一内存管理对象的创建统一内存管理对象在SparkEnv中进行创建和管理,这样内存管理就在Driver和Executor端中都可以使用。在SparkEnv的create函数中,创建内存管理对象的实现代码如下: val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false) val memoryManager: MemoryManager =原创 2021-01-02 09:35:50 · 273 阅读 · 0 评论 -
Spark2原理分析--统一内存管理概述
Spark统一内存管理概述本文介绍Spark统一内存管理的基本概念和基本原理。通过本文可以了解Spark统一内存管理的内存管理方式,基本理解内存管理的实现方式。堆外内存和堆内内存堆外内存(off-heap memory)为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的操作系统内存中开辟空间,存储经过序列化的二进制数据。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说原创 2021-01-02 09:33:48 · 267 阅读 · 0 评论 -
不同模式下Spark应用的执行流程
不同执行模式下Spark各个阶段的执行步骤不相同,本文分析不同模式下Spark应用的执行流程。Yarn-Client模式的执行流程Yarn的组成Yarn是hadoop自带的资源管理框架,它的设计思想是:YARN的基本思想是将资源管理和作业调度/监视的功能拆分为单独的守护程序。这个想法是拥有一个全局ResourceManager(RM)和每个应用程序ApplicationMaster(AM)。应用程序可以是单个作业,也可以是作业的DAG。ResourceManager和NodeManager组成数据计原创 2020-09-13 18:01:32 · 358 阅读 · 0 评论 -
如何理解Spark应用执行的阶段
本节介绍了Spark应用的执行过程,通过本节的学习应该对Spark应用的执行过程有一个总体的理解。接下来会根据具体的运行模式来详细分析每个阶段的执行步骤。原创 2020-08-03 09:10:34 · 774 阅读 · 0 评论 -
Spark的基本概念
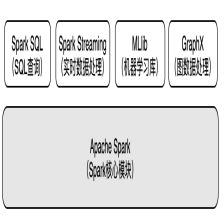
Spark的基本概念基本组成Spark是一个分布式系统,也是集多个功能模块于一身的统一平台。它基于一个内核模块衍生出机器学习,实时流计算,OLAP,和图数据处理等模块,如图1-1-1所示。本书主要介绍Spark内核模块的实现原理。 图1-1-1 spark功能模块从图1-1-1中可以看出Spark内核模块是基础层,它是所有上层功能模块的基础。所有上层的功能模块都使用Spark内核模块提供的接口来实现其功原创 2020-08-03 09:06:29 · 445 阅读 · 0 评论 -
深入浅出RDD Persist和Cache
深入说明RDD的persist和cache的实现和应用。并结合RDD的计算和一个具体的例子来说明persist和cache的使用场景。原创 2020-05-23 14:40:30 · 412 阅读 · 0 评论 -
spark2原理分析-广播变量(Broadcast Variables)的实现原理
概述本文介绍spark中Broadcast Variables的实现原理。基本概念在spark中广播变量属于共享变量的一种,spark对共享变量的介绍如下:通常,当在远程集群节点上执行传递给Spark操作(例如map或reduce)的函数时,它将在函数中使用的所有变量的单独副本上工作。这些变量将复制到每台计算机,而且远程机器上的变量的更新不会同步给驱动程序(driver)端。这种情况下,...原创 2019-08-19 08:03:09 · 2916 阅读 · 1 评论 -
spark2 sql原理分析--逻辑计划转换成物理计划的实现分析(SparkPlanner)
概述本文介绍介绍SparkPlanner的实现原理。SparkPlanner将优化后的逻辑执行计划转换为物理执行计划的计划器(Planner)。SparkPlanner是一个具体的Catalyst Query Planner,它使用执行计划策略( execution planning strategies)将逻辑计划转换为一个或多个物理计划,并支持额外的策略(ExperimentalMeth...原创 2020-02-22 20:22:59 · 1416 阅读 · 0 评论 -
spark2 sql原理分析--如何调试Query Execution
概述本文讲述如何调试 Query Execution(qe),qe会完成整个spark sql的全部执行计划的处理过程,直到生成rdd代码。为了更好的理解从逻辑计划到物理计划,最后生成的rdd代码,需要能够对该模块进行调试。理解spark sql的执行过程数据准备按以下csv数据格式准备数据。[hover@vm-192-168-4-141 ~]$ hadoop fs -cat /usr...原创 2020-01-20 08:22:54 · 1323 阅读 · 0 评论 -
spark2 sql原理分析—执行计划的生成和处理(QueryExecution实现概要)
概述本文分析Dataset中的执行计划的处理过程。执行计划的处理包括以下几个过程:分析逻辑执行计划->优化逻辑执行计划->生成一个或多个物理执行计划->优化物理执行计划->生成可执行代码。这个过程都是在dataset的成员:QueryExecution中完成。所以本篇,就是介绍QueryExecution的实现过程。由于QueryExecution的实现过程很多,本文...原创 2020-01-20 08:20:39 · 2042 阅读 · 0 评论 -
spark2原理分析-shuffleWriter:SortShuffleWriter实现分析
概述本文分析shuffleWriter的实现类:SortShuffleWriter的详细实现。ShuffleWriter抽象类/** * Obtained inside a map task to write out records to the shuffle system. */private[spark] abstract class ShuffleWriter[K, V] {...原创 2019-11-15 19:30:03 · 335 阅读 · 0 评论 -
spark2原理分析-shuffleWriter之BypassMergeShuffleWriter实现分析
概述本文分析shuffleWriter的实现类:BypassMergeSortShuffleWriter的详细实现原理。BypassMergeSortShuffleWriter介绍BypassMergeSortShuffleWriter的启用条件shuffl过程中进行write时,会根据不同的情况选择不同的shuffleWriter实现类。从前面的几篇文章《spark2原理分析—shuff...原创 2019-11-15 19:23:45 · 399 阅读 · 0 评论 -
spark2原理分析-BlockManagerMaster实现原理
概述本文讲说明spark中BlockManager的基本原理。BlockManager的基本概念BlockManager运行在spark的每个节点上(包括driver和executors),它提供了一个保存和获取本地或远端数据块到内存、磁盘、或off-heap中的统一接口。BlockManage的实现分析数据块管理的总体架构spark数据块管理的总体架构如下图所示:从该架构图可见,...原创 2019-08-17 21:07:19 · 860 阅读 · 0 评论 -
spark2原理分析-BlockManager总体架构设计
概述本文介绍spark的存储体系,通过本文的学习可以对spark的BlockManager体系有一个总体的把握。BlockManger的总体架构BlockManager运行在spark的每个节点上(包括driver和executors),它提供了一个保存和获取本地或远端数据块到内存、磁盘、或off-heap中的统一接口。从该架构图可见,在spark的每个任务执行器中都有一个blockma...原创 2019-08-17 21:05:07 · 311 阅读 · 0 评论 -
spark2 Dataset实现原理分析-Dataframe原理介绍和Dataset的对比
概述本文讲述Spark Dataframe的原理要点。Dataframe原理要点Spark SQL引入了一个名为DataFrame的表格函数数据抽象。设计它的目的在于:简化Spark应用程序的开发。这样就可以在Spark基础架构上处理大量结构化表格数据。DataFrame是一种数据抽象或特定于域的语言(domain-specific language ),用于处理结构化和半结构化数...原创 2019-06-15 14:05:42 · 1205 阅读 · 0 评论 -
Spark2 Dataset实现原理分析-Dataset实现原理概要
概述本文讲述spark sql中的dataset的组成部分,并对其创建过程进行分析。Dataset要点我们可以总结出dataset的一些要点,如下:和关系型数据表一样,Dataset是强类型的。数据集的行的集合,被称为Dataframe。和RDD一样,Dataset的操作分为两类:转换(transformations)和行动(action)。和RDD一样,Dataset是lazy的...原创 2019-06-07 22:03:34 · 892 阅读 · 0 评论 -
spark2原理分析-shuffle框架之ShuffleReader实现分析
概述本文讲述shuffleReader的具体实现。从这篇文章中,我们已经知道shuffleReader是一个抽象类,该抽象类只有一个read函数,用来在shuffle阶段从本地或远程获取数据。该抽象类的实现类是:BlockStoreShuffleReader。本文主要讲述该实现类的具体实现。shuffle reader实现要点shuffle过程可以从两个地方来读取数据块,一个是本地的bl...原创 2019-05-25 21:34:31 · 673 阅读 · 0 评论 -
spark2原理分析—shuffle框架的实现概要分析
概述本文分析spark2的shuffle过程的实现。shuffle过程介绍shuffle总体流程spark2的shuffle过程可以分为shuffle write和shuffle read。shuffle write把map阶段计算完成的数据写入到本地。而shuffle read是从不同的计算节点获取shuffle write的就按出来的数据,这样就会发生网络的数据传输和磁盘的i/o。为...原创 2019-05-19 20:41:21 · 1779 阅读 · 0 评论 -
spark2原理分析-SparkEnv的初始化
概述本文讲述spark执行环境:SparkEnv的概念和实现原理。spark执行环境(SparkEnv)的基本概念spark执行环境的实现类是:SparkEnv,该类包括所有spark运行实例(master和worker)需要的运行环境工具类,包块:序列化,block manager,map output tracker,RpcEnv等等。spark的运行实例通过SparkEnv的全局变量...原创 2019-05-19 10:14:03 · 493 阅读 · 0 评论 -
spark2原理分析-Task调度对象Pool原理分析
概述本文分析Task调度器的Pool调度对象的实现原理。通过文章spark2原理分析-Task调度对象实现接口(Schedulable)原理分析我们知道,任务调度器(TaskScheduler)中的调度对象分为两类:Pool和TaskSetManager。而这两类调度对象都实现了接口Schedulable。这篇文章着重讲解其中的一类调度对象Pool的实现原理。在Pool调度对象中实现了两种...原创 2018-12-01 07:44:14 · 411 阅读 · 0 评论 -
spark2原理分析-Task调度对象实现接口(Schedulable)原理分析
概述本文分析任务调度器TaskScheduler中的调度实体的实现合约的原理。TaskScheduler中的调度对象在TaskScheduler中调度对象是实现了合约(即:接口)Schedulable的类的对象。Schedulable是是可调度实体的合约,可以在这里查看该接口的实现代码。在spark2中有两个类实现了调度实体接口:Schedulable。也就是说有两种调度实体:Poo...原创 2018-11-30 11:44:03 · 319 阅读 · 0 评论 -
Spark2原理分析-DAGScheduler(Stage调度器)的基本概念
概述本文介绍Saprk中DAGScheduler的基本概念。该对象实现了一个面向Stage的高层调度器。它为每个Job计算一个Stage的DAG图,并跟踪这些RDD和Stage的输出,并找到一个最小的代价的DAG图来运行该Job。DAGScheduler介绍在文章《spark2原理分析-Stage的实现原理》中,介绍了Stage的基本概念和Stage的提交实现原理。本文主要介绍 DAGSch...原创 2018-11-11 07:03:09 · 715 阅读 · 0 评论 -
spark2原理分析-TaskScheduler(task调度器)概览
概述本文介绍TaskScheduler的基本概念和总体框架。TaskScheduler负责提交Spark应用的任务(task)去执行。根据前面的分析,我们已经知道job的提交过程,如下图所示:在前面的文章中对stage的调度进行了介绍,现在我们介绍task的调度器:TaskScheduler。任务(Task)调度概述在Spark中,不同的部署模式和运行任务调度器也不相同,如下:...原创 2018-11-24 21:57:45 · 732 阅读 · 0 评论 -
Spark2原理分析-DAGScheduler(Stage调度器)的实现原理
概述本文介绍DAGScheduler的实现原理。通过文章《Spark2原理分析-DAGScheduler(Stage调度器)的基本概念》我们学习了DAGScheduler的基本概念,并了解了它的功能。这篇文章,介绍DAGScheduler的具体实现。为避免篇幅过长,本文先介绍DAGScheduler的一些关键框架,和成员变量和函数。并介绍一些关键函数的实现。具体的各个框架的详细实现,放到后面的...原创 2018-11-23 14:59:42 · 541 阅读 · 0 评论 -
spark2原理分析-Stage的实现原理
概述本文介绍Spark任务执行框架中Stage的原理,并分析其实现机制。Stage的基本概念一个Stage是一个并行任务(Task实体)集,它们执行相同的计算逻辑,并作为Spark任务执行的一部分,所有的任务都具有相同的shuffle依赖。调度器运行的每个任务DAG,在shuffle的边界处(发生shuffling时)被分解成多个stage,然后DAGScheduler以拓扑顺序运行这些阶...原创 2018-11-09 13:55:35 · 657 阅读 · 0 评论 -
spark2原理分析-Job对象的实现原理
概述本节介绍Spark Job实体的实现原理。Job的基本概念在《spark2原理分析-Job执行框架概述》一文中介绍了Job的执行框架的基本概念,本节详细介绍其中的Job实体的实现原理。上面的文章已经介绍过了,Job是由于执行Action操作函数产生的。Job是提交给 DAGScheduler(Job调度器)来计算action操作结果的顶层工作单元(计算单元)。在Spark代码实现层面...原创 2018-10-31 19:35:03 · 661 阅读 · 0 评论 -
spark2原理分析-Job执行框架概述
概述本文描述了Spark2的job的设计原理,并对其实现进行了分析。spark的Job介绍从前面的文章中我们知道:一般来说Spark RDD的转换函数(transformation)不会执行任何动作,而当Spark在执行RDD的action函数时,Spark调度程序(scheduler)会构建执行图(graph)并发起一个Spark作业(Job)。Job由很多的Stage构成,这些Stag...原创 2018-10-31 10:17:47 · 606 阅读 · 0 评论 -
RDD的分区原理
概述本文介绍了Spark分区的实现原理,并对其源码进行了分析。分区器(Partitioner)的基本概念关于Spark分区的基本概念和介绍,可以参考我的这篇文章:Spark2.0-RDD分区原理分析。这里我们再回顾一下Spark分区的概念:从概念上讲,分区器(Partitioner)定义了如何分布记录,从而定义每个任务将处理哪些记录。从实现层面来说,Partitioner是一个带有以下两...原创 2018-10-29 19:38:17 · 871 阅读 · 0 评论 -
spark2原理分析-RDD的shuffle简介
概述本文介绍RDD的Shuffle原理,并分析shuffle过程的实现。RDD Shuffle简介spark的某些操作会触发被称为shuffle的事件。shuffle是Spark重新分配数据的机制,它可以对数据进行分组,该操作可以跨不同分区。该操作通常会在不同的执行器(executor)和主机之间复制数据,这使shuffle成为复杂且非常消耗资源的操作。Shuffle背景为了理解shuf...原创 2018-10-28 17:26:58 · 903 阅读 · 0 评论 -
spark2原理分析-RDD的依赖(Dependencies)原理分析
概述本文讲述了RDD依赖的原理,并对其实现进行了分析。Dependency的基本概念Dependency表示一个或两个RDD的依赖关系。依赖(Dependency)类是用于对两个或多个RDD之间的依赖关系建模的基础(抽象)类。Dependency有一个方法rdd来访问依赖的RDD。当你使用transformation函数来构建RDD的血缘(lineage)时,Dependency代表了...原创 2018-10-28 10:24:16 · 997 阅读 · 0 评论 -
spark2原理分析-RDD的checkepointing原理分析
概述本文介绍RDD的checkpoint的作用和原理,并对checkpointing的实现进行分析。RDD checkpoint的基本概念RDD可能经过任意多个transformations操作,导致RDD血缘(lineage)任意的增长,Spark提供了一种将整个RDD进行持久化保存的方法。这样,当节点发生故障而无法运行时,Spark不需要从头开始重新计算丢失的RDD片段,而是使用一种类似...原创 2018-10-19 10:03:09 · 412 阅读 · 0 评论 -
spark2.0原理分析--RDD血缘(RDD Lineage)
本文介绍了RDD的血缘基本概念和形成。血缘是由于RDD的转换操作形成的多个RDD的依赖关系。RDD的血缘不依赖数据的计算。每个RDD都有一个依赖的父RDD的引用的列表,通过这个列表来找到依赖的父RDD,多个RDD的依赖形成了一个DAG图(有向无环图)。这就是RDD的血缘(RDD Lineage)。原创 2017-06-13 07:23:53 · 5755 阅读 · 0 评论 -
spark2原理分析-RDD的Transformations原理分析
概述本文介绍RDD的Transformations函数的原理和作用。还会介绍transformations函数的分类,和不同类型的转换产生的效果。RDD的Transformations操作transformations简介在RDD中定义了两类函数:action和transformations。transformations通过在一些RDD中执行一些数据操作来产生一个或更多新的RDD。这些t...原创 2018-10-16 18:04:52 · 593 阅读 · 0 评论 -
spark2原理分析-RDD的caching和persistence原理分析
概述本文分析RDD的caching和persistence的原理。并对其代码实现进行分析。persist and cache基本概念Spark的一个重要特性是:能够跨操作把数据保存到内存中,这个过程称为persist,或称为caching。当persist一个RDD时,每个spark节点都会把它计算的任何分区保存到内存中,当在基于这些数据进行其他操作时进行复用。这样使得将来进行的操作更快(...原创 2018-10-21 14:39:37 · 714 阅读 · 0 评论 -
spark2原理分析-RDD基本原理分析
概述RDD是spark的基础,本文描述了RDD的基本概念,和RDD的性质。RDD基本原理(Resilient Distributed Dataset) 弹性分布式数据集,又称RDD,是spark中数据的基本抽象,它是spark的核心。最早的rdd的设计思想可以参考论文:可伸缩性分布式数据集(Resilient Distributed Datasets: A Fault-Tolerant Ab...原创 2018-10-14 16:36:32 · 405 阅读 · 0 评论