







1.背景
公司希望使用MongoDB作为后端业务数据库,使用Hadoop平台作为数据平台。最开始是先把数据从MongoDB导出来,然后传到HDFS,然后用Hive/MR处理。我感觉这也太麻烦了,现在不可能没有人想到这个问题,于是就搜了一下,结果真找到一个MongoDB Connector for Hadoop
2.MongoDB简介–摘自邹贵金的《mongodb》一书
NoSQL数据库与传统的关系型数据库相比,它具有操作简单、完全免费、源码公开、随时下载等特点,并可以用于各种商业目的。这使NoSQL产品广泛应用于各种大型门户网站和专业网站,大大降低了运营成本。
2010年,随着互联网Web2.0网站的兴起,NoSQL在国内掀起一阵热潮,其中风头最劲的莫过于MongoDB了。越来越多的业界公司已经将MongoDB投入实际的生产环境,很多创业团队也将MongoDB作为自己的首选数据库,创造出非常之多的移动互联网应用。
MongoDB的文档模型自由灵活,可以让你在开发过程中畅顺无比。对于大数据量、高并发、弱事务的互联网应用,MongoDB可以应对自如。MongoDB内置的水平扩展机制提供了从百万到十亿级别的数据量处理能力,完全可以满足Web2.0和移动互联网的数据存储需求,其开箱即用的特性也大大降低了中小型网站的运维成本。
3.Hadoop HA集群搭建与Hive安装
Hadoop HA高可用集群搭建(2.7.2)
Hive安装及使用演示
4.正式开始
Installation
Obtain the MongoDB Hadoop Connector. You can either build it or download the jars. For Hive, you'll need the "core" jar and the "hive" jar.
Get a JAR for the MongoDB Java Driver. The connector requires at least version 3.0.0 of the driver "uber" jar (called "mongo-java-driver.jar").
In your Hive script, use ADD JAR commands to include these JARs (core, hive, and the Java driver), e.g., ADD JAR /path-to/mongo-hadoop-hive-<version>.jar;.
- 1
- 2
- 3
- 4
Requirements
Supported Hadoop and Hive versions
As of August 2013, only Hive versions <= 0.10 are stable. Mongo-Hadoop currently supports Hive versions >= 0.9. Some classes and functions are deprecated in Hive 0.11, but they’re still functional.
Hadoop versions greater than 0.20.x are supported. CDH4 is supported, but CDH3 with its native Hive 0.7 is not. However, CDH3 is compatible with newer versions of Hive. Installing a non-native version with CDH3 can be used with Mongo-Hadoop.
1.版本一定要按它要求的来,jar包去http://mvnrepository.com/下载就可以了,使用Hive只需要三个:
mongo-hadoop-core-1.5.1.jar
mongo-hadoop-hive-1.5.1.jar
mongo-java-driver-3.2.1.jar
2.将jar包拷到 HADOOPHOME/lib与HADOOPHOME/lib与{HIVE_HOME}/lib下,然后启动Hive,加入jar包
[hadoop@DEV21 ~]$ hive
Logging initialized using configuration in jar:file:/home/hadoop/opt/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive> add jar /home/hadoop/opt/hive/lib/mongo-hadoop-core-1.5.1.jar;#三个都加,我这就不写了。- 1
- 2
- 3
- 4
3.Hive Usage有两种连接方式:
其一MongoDB-based 直接连接hidden节点,使用 com.mongodb.hadoop.hive.MongoStorageHandler做数据Serde
其二BSON-based 将数据dump成bson文件,上传到HDFS系统,使用 com.mongodb.hadoop.hive.BSONSerDe
- 1
- 2
- 3
MongoDB-based方式
hive> CREATE TABLE eventlog
> (
> id string,
> userid string,
> type string,
> objid string,
> time string,
> source string
> )
> STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler'
> WITH SERDEPROPERTIES('mongo.columns.mapping'='{"id":"_id"}')
> TBLPROPERTIES('mongo.uri'='mongodb://username:password@ip:port/xxx.xxxxxx');
hive> select * from eventlog limit 10;
OK
5757c2783d6b243330ec6b25 NULL shb NULL 2016-06-08 15:00:07 NULL
5757c27a3d6b243330ec6b26 NULL shb NULL 2016-06-08 15:00:10 NULL
5757c27e3d6b243330ec6b27 NULL shb NULL 2016-06-08 15:00:14 NULL
5757c2813d6b243330ec6b28 NULL shb NULL 2016-06-08 15:00:17 NULL
5757ee443d6b242900aead78 NULL shb NULL 2016-06-08 18:06:59 NULL
5757ee543d6b242900aead79 NULL smb NULL 2016-06-08 18:07:16 NULL
5757ee553d6b242900aead7a NULL cmcs NULL 2016-06-08 18:07:17 NULL
5757ee593d6b242900aead7b NULL vspd NULL 2016-06-08 18:07:21 NULL
575b73b2de64cc26942c965c NULL shb NULL 2016-06-11 10:13:06 NULL
575b73b5de64cc26942c965d NULL shb NULL 2016-06-11 10:13:09 NULL
Time taken: 0.101 seconds, Fetched: 10 row(s)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
这时HDFS里是没有存任何数据的,只有与表名一样的文件夹
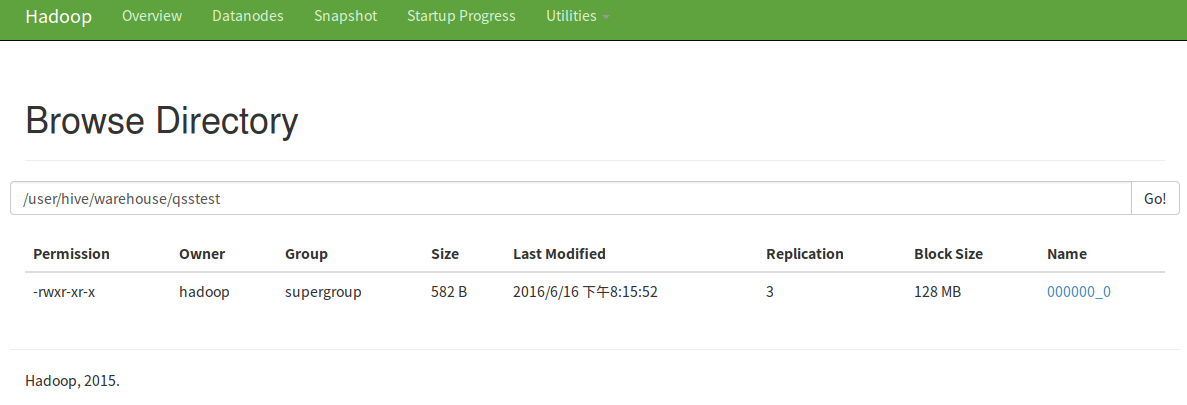
当你处理的时候,它是直接处理mongo里最新的数据。当然,如果你想存到HDFS里也可以,用CTAS语句就可以。 hive> create table qsstest as select * from eventlog limit 10;
还可以下载下来呢
PS:mongo的用户要有读写权限,jar包别忘了拷进去!
另一种方式我感觉有点没必要,没试,但我找到一篇博客详细写了。
下面转自:MongoDB与Hadoop技术栈的整合应用
BSON-based方式
BSON-based需要先将数据dump出来,但这个时候的dump与export不一样,不需要关心具体的数据内容,不需要指定fields list.
mongodump --host=datatask01:29017 --db=test --collection=ldc_test --out=/tmp
hdfs dfs -mkdir /dev_test/dli/bson_demo/
hdfs dfs -put /tmp/test/ldc_test.bson /dev_test/dli/bson_demo/
- 创建映射表
create external table temp.ldc_test_bson
(
id string,
fav_id array<int>,
info struct<github:string, location:string>
)
ROW FORMAT SERDE "com.mongodb.hadoop.hive.BSONSerDe"
WITH SERDEPROPERTIES('mongo.columns.mapping'='{"id":"id","fav_id":"fav_id","info.github":"info.github","info.location":"info.location"}')
STORED AS INPUTFORMAT "com.mongodb.hadoop.mapred.BSONFileInputFormat"
OUTPUTFORMAT "com.mongodb.hadoop.hive.output.HiveBSONFileOutputFormat"
location '/dev_test/dli/bson_demo/';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
OK,我们先来看下query的结果
0: jdbc:hive2://hd-cosmos-01:10000/default> select * from temp.ldc_test_mongo;
+--------------------+------------------------+-----------------------------------------------------------------+--+
| ldc_test_mongo.id | ldc_test_mongo.fav_id | ldc_test_mongo.info |
+--------------------+------------------------+-----------------------------------------------------------------+--+
| @Tony_老七 | [3,33,333,3333,33333] | {"github":"https://github.com/tonylee0329","location":"SH/CN"} |
+--------------------+------------------------+-----------------------------------------------------------------+--+
1 row selected (0.345 seconds)- 1
- 2
- 3
- 4
- 5
- 6
- 7
这样数据就存储在一个table,使用中如果需要打开数组,可以这样
SELECT id, fid
FROM temp.ldc_test_mongo LATERAL VIEW explode(fav_id) favids AS fid;
-- 访问struct结构数据
select id, info.github from temp.ldc_test_mongo- 1
- 2
- 3
- 4
//根据不同的数据类型进行反序列操作,复杂类型在内容做element的循环,最终调用的都是对原子类型的操作.
public Object deserializeField(final Object value, final TypeInfo valueTypeInfo, final String ext) {
if (value != null) {
switch (valueTypeInfo.getCategory()) {
case LIST:
return deserializeList(value, (ListTypeInfo) valueTypeInfo, ext);
case MAP:
return deserializeMap(value, (MapTypeInfo) valueTypeInfo, ext);
case PRIMITIVE:
return deserializePrimitive(value, (PrimitiveTypeInfo) valueTypeInfo);
case STRUCT:
// Supports both struct and map, but should use struct
return deserializeStruct(value, (StructTypeInfo) valueTypeInfo, ext);
case UNION:
// Mongo also has no union
LOG.warn("BSONSerDe does not support unions.");
return null;
default:
// Must be an unknown (a Mongo specific type)
return deserializeMongoType(value);
}
}
return null;
}
// 转为java的原子类型存储.
private Object deserializePrimitive(final Object value, final PrimitiveTypeInfo valueTypeInfo) {
switch (valueTypeInfo.getPrimitiveCategory()) {
case BINARY:
return value;
case BOOLEAN:
return value;
case DOUBLE:
return ((Number) value).doubleValue();
case FLOAT:
return ((Number) value).floatValue();
case INT:
return ((Number) value).intValue();
case LONG:
return ((Number) value).longValue();
case SHORT:
return ((Number) value).shortValue();
case STRING:
return value.toString();
case TIMESTAMP:
if (value instanceof Date) {
return new Timestamp(((Date) value).getTime());
} else if (value instanceof BSONTimestamp) {
return new Timestamp(((BSONTimestamp) value).getTime() * 1000L);
} else if (value instanceof String) {
return Timestamp.valueOf((String) value);
} else {
return value;
}
default:
return deserializeMongoType(value);
}
}













 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









