



 文章详细解释了Java中常量池的位置变化,以及字符串对象的不同创建方式(常量池与堆内存),特别强调了字符串拼接时的编译期优化。
文章详细解释了Java中常量池的位置变化,以及字符串对象的不同创建方式(常量池与堆内存),特别强调了字符串拼接时的编译期优化。
1、常量池的位置
jdk 1.7之前常量池是存放在永久代(hotspot虚拟机对方发区的实现)中
jdk 1.7常量池从永久代中移到了堆内存中,属于堆内存的一部分。
Jdk 8 移除了永久代并由元空间(metaspace)代替,存放在本地内存(native space)中。并没有对常量池再做变动。即常量池一直在堆中。
2.String创建方式:
String s1 = "123";
String s2 = new String("123");
String s3 = "123";
System.out.println(s1 == s2); // false
System.out.println(s3==s1); //true
char[] s = {'1', '2', '2', 'w'};
String s4 = new String(s);
String s5 = new String(s);
System.out.println(s5 == s4); //false
这两种创建方式是不同的,一种是以双引号方式写出的字符串对象,数据会存储在字符串常量池中,且相同内容的字符串仅存储一份,所以多个对象指向常量池同一个地址,显示为true。
而通过new关键字创建的字符串对象,每new一次就会产生新的对象放入堆内存中。
 而如果用new关键字创建了一个包含双引号的对象,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用
而如果用new关键字创建了一个包含双引号的对象,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用
如下:
String s6 = new String("hanzi");
该段代码一共产生了两个对象,一个在常量池中,一个建立在堆内存中并将地址返回给栈内存中的s6。字符串常量"hanzi"在编译期就已经确定放入常量池,而 Java 堆上的"hanzi"是在运行期初始化阶段才确定。
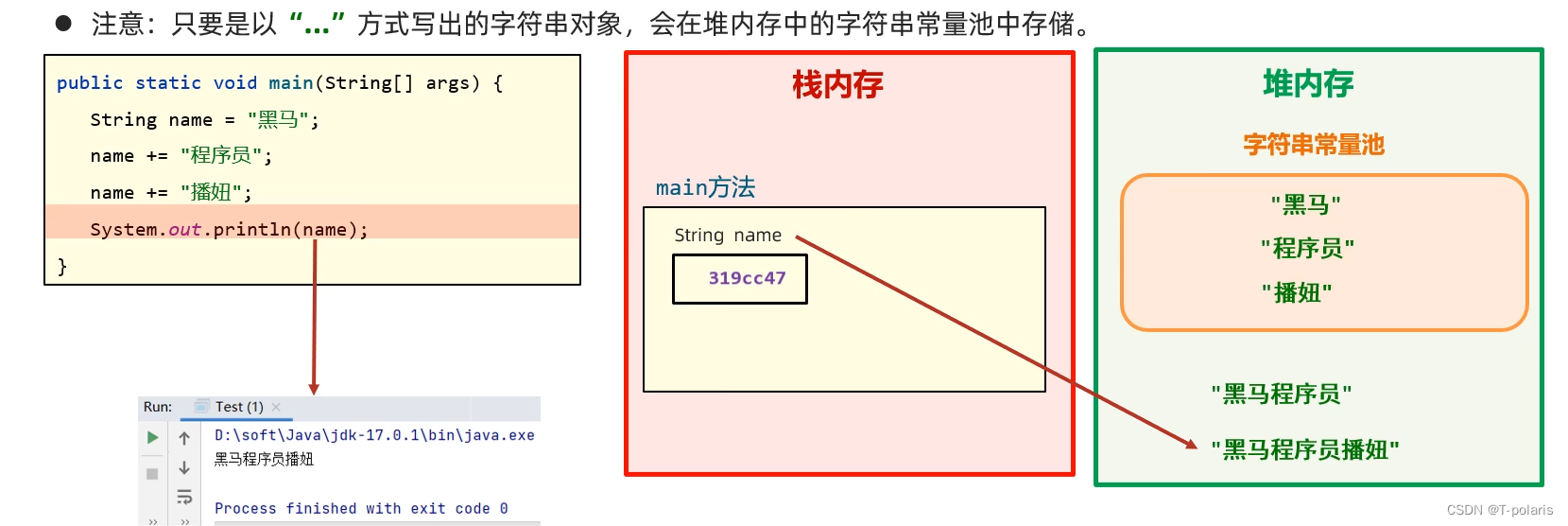
3.注意:
在字符串拼接和运算期间产生的对象会直接放进堆内存中,
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing";//常量池中的对象
String str4 = str1 + str2; //在堆上创建的新的对象
String str5 = "string";//常量池中的对象
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false
str3与str5比较相同是因为java存在编译优化机制,程序在编译期间会直接将“str”+“ing"转化为“string”,以提高程序的执行能力,由于常量池中存在"string",所以两地址相同,等号成立。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









