






作者简介
作者:杨国栋
原腾讯科技工程师
《Apache Pulsar原理与实践》作者
杭州电子科技大学硕士
Apache Pulsar社区开源爱好者
现国内互联网消息队列领域研发
PowerData技术丛书编委会负责人
序言:操作系统、数据库、中间件是基础软件的三驾马车,而消息队列属于最经典的中间件之一,迄今已有 30 多年的历史。本文会从消息队列的发展历史说起,并逐渐提及Kafka、Pulsar等消息队列技术。最后会在文章结尾,尝试向后展望。
Kafka始于2010的LinkedIn,不仅支持了原本公司的业务,还通过开源社区服务到了更加广大的技术人群。 在Kafka发展的过程中,业内不断涌现了RocketMQ、Pulsar等消息队列。而Pulsar站在前人的肩膀上,借鉴若干开源项目优秀架构,也在当前时期对外展现着强劲的生命力。
本文不仅将视角锁定于某一项消息队列,而是尝试超越单一时间维度,从不同的角度审视消息队列相关技术的发展。
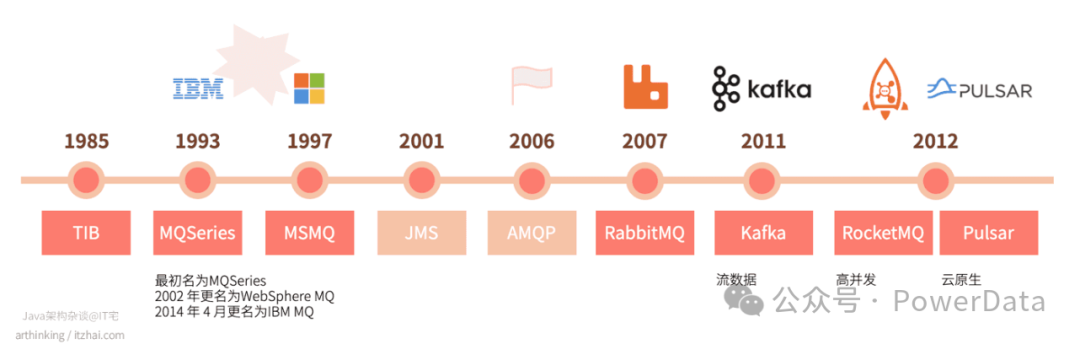
《旧唐书·魏徵传》:“夫以铜为镜,可以正衣冠;以史为镜,可以知兴替;以人为镜,可以明得失。” 消息队列的发展离不开IT 技术演化的趋势。在其30年的发展历程中,消息队列的发展主要经历了以下几个阶段:
远古时代,天地混沌
在上世纪 80 年代,为了解决不同软件系统间的通信难题,首款基于发布/订阅模式的消息队列——The Information Bus 应运而生。1985 年,Vivek 从 Teknekron Corp 获得种子资金,Teknekron Software Systems Inc. (TSS) 诞生了,专注于 TIB 商业化。TIB 主要服务于金融行业,解决证券交易软件之间的数据交换问题。20 世纪 80 年代美国金融交易行业门厅若市,因此 TIB 被广泛使用大获成功。到了 90 年代,则是国际商业软件巨头的时代,IBM、Oracle、Microsoft 纷纷推出了自己的 MQ,其中最具代表性的是 IBM MQ,价格昂贵,面向高端企业,主要是大型金融、电信等企业。这类商业 MQ 一般采用高端硬件,软硬件一体机交付,MQ 本身的软件架构是单机架构。
值得一提的是,IBM MQ目前还是最盈利的商业化MQ。每年全球仍有近 10 亿美金的营收, 占市场份额近三分之一。
而在中国互联网圈子的我们,可能对IBM MQ等服务较为陌生。这一切与2008年阿里提出去IOE化有关。阿里主张通过用开源软件及在其基础上开发的系统,替换掉IBM小型机、Oracle数据库、EMC存储设备。
虽然我们不能断言是阿里终结了一个时代,但它的确是那个时代最有代表性的例子。也代表了当时国内技术演化的方向。
初步开源,惊鸿初现
随着国际互联网的业务飞速发展,2000年后,初代开源消息队列崛起,并诞生了 JMS(Java Message Service)、AMQP(Advanced Message Queuing Protocol) 两大标准,分别定义了消息队列的标准接口和协议。ActiveMQ和RabbitMQ分别作为JMS和AMQP这两种标准的具体实现典范,引领了早期开源消息队列技术的创新潮流。
JMS 之于 MQ 类似于 JDBC 之于数据库,它试图通过提供公共 Java API 的方式,隐藏各类MQ 产品的实际接口,从而跨越壁垒解决互通问题。从技术上讲,Java 应用程序只需针对 JMS API 编程,选择合适的 MQ 驱动即可,JMS 会打理好其他部分。JMS 确实一定程度上解决了 MQ 之间互通的问题,但当应用通讯底层适配不同的 MQ 时需要代码去胶合众多不同 MQ 接口,这使 JMS 应用程序非常脆弱,可用性下降。市场急需一个原生支持 JMS 协议的 MQ 。基于这样的背景,2003 年 ActiveMQ 诞生 。
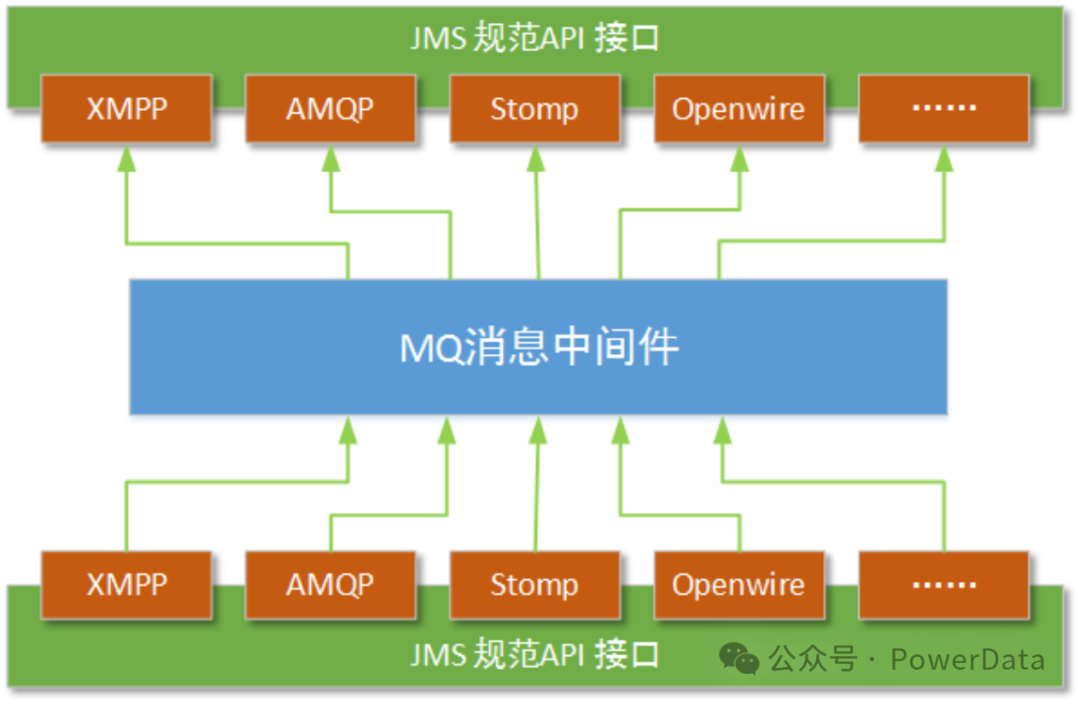
JMS 只针对于 Java 应用,其他语言无法使用 JMS ,在此背景下,真正的救世主 AMQP (Advanced Message Queuing Protocol)在 2003 年时被 John O'Hara 提出,并由摩根大通牵头联合 Cisco, IONA,Red Hat, iMatix 等成立了 AMQP 工作组,用于解决金融领域不同平台之间的消息传递交互问题。AMQP 是一种协议,更准确的说是一种 Binary Wire-Level Protocol(链接协议)。这是其与 JMS 的本质差别,AMQP 不从 API 层进行限定,而是直接定义网络交换的数据格式。这使得实现了 AMQP 的 Provider 天然就是跨平台的。我们可以使用 Java 的 AMQP Provider,同时使用一个 Python 的 Producer 加一个 Ruby 的 Consumer。从这一点看,AMQP 可以用 HTTP 来进行类比,不关心实现的语言,只要大家都按照相应的数据格式去发送报文请求,不同语言的 Client 均可以和不同语言的 Server 链接。AMQP 的 Scope 要比 JMS 更广阔。
显然市场上需要一个完全实现 AMQP 协议的消息队列产品。2007 年由 Alexis 和 Matthias 联合创办的公司 Rabbit Technologies 成立 ,同年该公司推出了第一个完全实现 AMQP 协议的消息队列产品 RabbitMQ。RabbitMQ 用 Erlang 语言开发,在当时其性能非常好,且能达到微秒级延时。
尽管AMQP的功能强大且适用于复杂的集成场景,但其协议相对复杂,对于资源有限的设备来说可能过于沉重。于是MQTT 作为一种轻量级的发布/订阅模式的消息传输协议,由 IBM 在 1999 年推出。它专为资源有限的设备和低带宽、高延迟或不稳定的网络而设计,非常适合需要小代码占用的应用场景(例如,机器之间通信或物联网)。
MQTT 基于发布/订阅模式,在这种模式下,生产者(也称为发布者)创建信息,消费者(也称为订阅者)接收信息。发布者和订阅者之间的交互由 Broker 管理。Broker 负责将消息从发布者分发给订阅者。
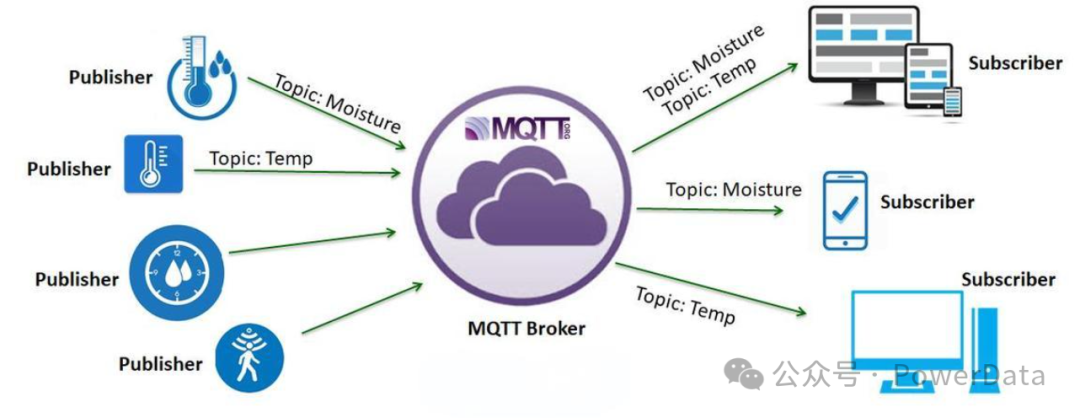
MQTT 的简单之处在于其协议命令很少。它只有几个命令,因此很容易在各种设备和系统中实现。此外,它的服务质量等级可以保障消息传输的可靠性,避免消息在传输过程中丢失。
消息队列在开源背景下、降低了使用门槛,拓宽了应用场景,逐渐成为企业架构的标配。但无论是ActiveMQ还是RabbitMQ,其主要面向传统企业级应用和小流量场景,横向扩展能力比较弱。
开源成熟,双柱擎天
10年后移动互联网的发展导致传统消息队列无法承受爆炸增长的访问流量和数据传输,企业急需一个高吞吐、分布式、支持横向扩展的消息队列解决上述问题。在这个阶段中Kafka与RocketMQ展现出他们的优势。
LinkedIn 作为一个全球性的社交网有着庞大的用户数,其产品优化与广告投放的业务开展,需要将各类数据与日志汇聚到大数据平台进行分析。这其中,海量数据的传输成为一个关键问题。LinkedIn 最初方案是采用 ActiveMQ进行。然而ActiveMQ 虽然有完整的消息机制、灵活的配置方式以及安全的消息交付保证,但是无法满足LinkedIn 传输海量数据的场景。
在此背景下,2009 年底 LinkedIn 计划自研了新一代的消息产品 Kafka,其高吞吐、持久化、分布式的特性完美解决了海量数据传输的痛点。Kafka 于 2010 年底被开源,2011 年 7 月被 LinkedIn 捐献到了 Apache 基金会,2012 年 10 月 23 日从 Apache 毕业成为顶级开源项目,并很快被 Twitter、Netflix、Uber 等硅谷互联网公司大量应用于大数据分析场景。
Kafka 的诞生还将消息中间件从消息领域延伸到流领域,从分布式应用的异步解耦场景延伸到大数据领域的流存储和流计算场景。流计算或者说实时计算的故事,从这里开始。
除了大数据,在那个时代还有一条快速发展的技术发展曲线:微服务。“微服务” 最早由 Peter Rodgers 博士在 2005 年度的云计算博览会(Web Services Edge 2005)上提出,当时的说法是“Micro-Web-Service”,指的是一种专注于单一职责的、语言无关的、细粒度 Web 服务(Granular Web Services)。微服务的概念当时只是对 SOA 架构的修补在将近十年的时间里面,并没有受到太多的追捧。
移动互联网时代的到来导致各类应用用户激增,应用软件不得不做架构性的重构,以保证更流畅的用户体验。微服务架构迎来了它的发展高速期。同时,如何保障成百上千的微服务的异步通信,也成为问题的关键。
Kafka作为当时消息队列的佼佼者,其虽然有较的吞吐量与持久化能力,但无法支撑大规模微服务的场景。主要有三个核心问题:其一是消息特性,Kafka 对于事务消息、延时消息当时尚未完善。RabbitMQ和ActiveMQ特性支持完善,但是其拓展性和性能达不到要求。其二是单条消息的质量问题。不同于大数据场景对单条消息的丢失容忍,在微服务交易场景,如果有任何一条消息丢失,就意味着订单数据的丢失,业务无法容忍,而 Kafka 为了提高消息的吞吐量,采用了批量消息发送的方式,消息丢失时有发生。最后是 Kafka 创建多个 Topic 时非常不稳定,严重影响整个系统的吞吐量。这与 Kafka 系统模型的设计和持久化有很大关系。
鉴于以上情况,阿里自主研发了一款可以满足大规模微服务场景的消息队列产品:RocketMQ。RocketMQ 可以简单理解为 Kafka 和 RabbitMQ 的合体版。RocketMQ 实现了事务消息、延时消息、死信队列等消息特性。为了保证高吞吐量,RocketMQ 整体上采用的 Kafka 的存储模型,也采用了顺序读写的方案。但是为了提高消息的质量,RocketMQ并没有采用消息批量发送和接收的方式,而是单条发、单条收。另外为了解决 Kafka 模型在大量 Topic 场景下性能不稳定的问题,RocketMQ改进了 Kafka 的数据存储机制。
RocketMQ不再沿用Partition与存储文件一一映射的模式,而是以Broker维度进行数据存储,将同一个 Broker 所有的 Partition(RocketMQ中称之为 Message Queue)数据存储到一个日志文件中。这样虽然读取时会稍显复杂,但是可以解决多 Topic 导致的读写性能与稳定性问题。
由于解决了消息队列应用在大规模微服务场景的问题,RocketMQ在开源后受到互联网公司的广泛关注。
在当时,开源消息队列典型代表有 Kafka、RocketMQ。他们各自在大数据与微服务场景下,发挥着价值。同时国内各大互联网公司也在消息队列领域持续投入。
TubeMQ是腾讯大数据在2013年开始研发的分布式消息中间件系统(MQ),专注服务大数据场景下海量数据的高性能存储和传输。经过近7年上万亿的海量数据沉淀,较之于众多的开源MQ组件,TubeMQ在海量实践(稳定性+性能)和低成本方面有一定的优势。
DDMQ 是滴滴出行架构部基于 Apache RocketMQ构建的消息队列产品。作为分布式消息中间件,DDMQ 为滴滴出行各个业务线提供了低延迟、高并发、高可用、高可靠的消息服务。DDMQ 提供了包括实时消息、延迟消息和事务消息在内的多种消息类型以满足不同的业务需求。用户通过统一的 Web 控制台和傻瓜式的 SDK 即可轻松接入 DDMQ 生产和消费消息,体验功能丰富、稳定的消息服务。
除此之外,还有字节跳动的BMQ、京东的JMQ、去哪儿网的QMQ 、小米的Talos等消息队列。有的仅仅在内部使用,也有的厚积薄发准备随时面向市场,对外输出其先进能力,也有的已经被内部逐渐淘汰。
无论开源还是商业化,消息队列的发展都离不开从业者们的不断尝试与付出,借此篇文章对他们表示感谢。
跨步向云,原生伊始
云计算的故事也是IT发展浪潮中,重要的一环。
云计算本身是科学术语,是一种分布式计算,指的是通过网络将大量的数据计算处理程序分解成无数个小程序,通过多部服务器组成的系统进行处理和分析这些小程序得到结果并返回给用户。包含:基础设施即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS)等技术。从现在的视角审视之前的云产品,我们可以将其视作 “非云原生的云计算”。
早期“上云”操作,仅是将私有数据中心中的应用,“搬”到云上。应用无需重写,只需要重新部署(云平台提供的计算、存储、网络等完全兼容应用迁移之前的计算环境)。从应用层面看主要有以下改变:
-
-
物理机部署 → 虚拟机部署
本地化存储 → 兼容的块存储或者文件存储
传统负载均衡 → SLB(Server Load Balance,服务器负载均衡)
MySQL → 云上数据库
-
云原生(Cloud Native)的概念,最早由Pivotal于2015年提出,是基于云计算发展而来,使公司可在公有云、私有云和混合云等新型动态环境中构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。云原生化可以使得应用可以更加合理的利用云计算的优势,是释放云计算价值的最短路径。
消息队列作为基础中间件与云计算、云原生一同发展。早在2004 年 AWS 推出了第一个云计算基础设施服务:简单队列服务。而在云原生时代,Pulsar应运而生。
Pulsar 诞生于 2012 年,最初是 Yahoo 内部为了整合其他消息系统,构建统一逻辑、支撑大集群和跨区域的消息平台。当时的其他消息系统(包括 Kafka),都不能满足 Yahoo 的需求,比如大集群多租户、稳定可靠的 IO 服务质量、百万级 Topic、跨地域复制等·。

Apache Pulsar 作为 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、跨区域复制、具有强一致性、高吞吐、低延迟及高可扩展性等流数据存储特性。这一些的特性都在述说着:Pulsar 站在前人的肩膀上,随着时代的洪流,站上了风口。
在很多场景下,云原生消息队列Pulsar因为其存储与计算分离的特性,使得Pulsar可以分别对存储与计算类进行扩容,更加好的利用云计算弹性优势。
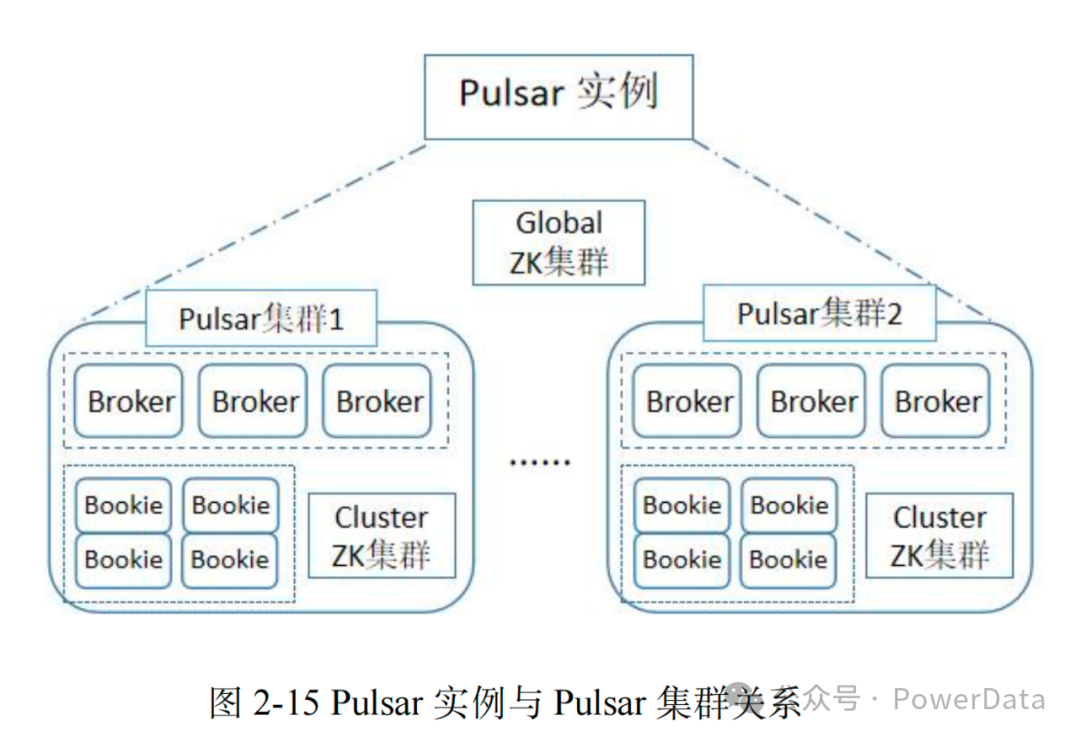
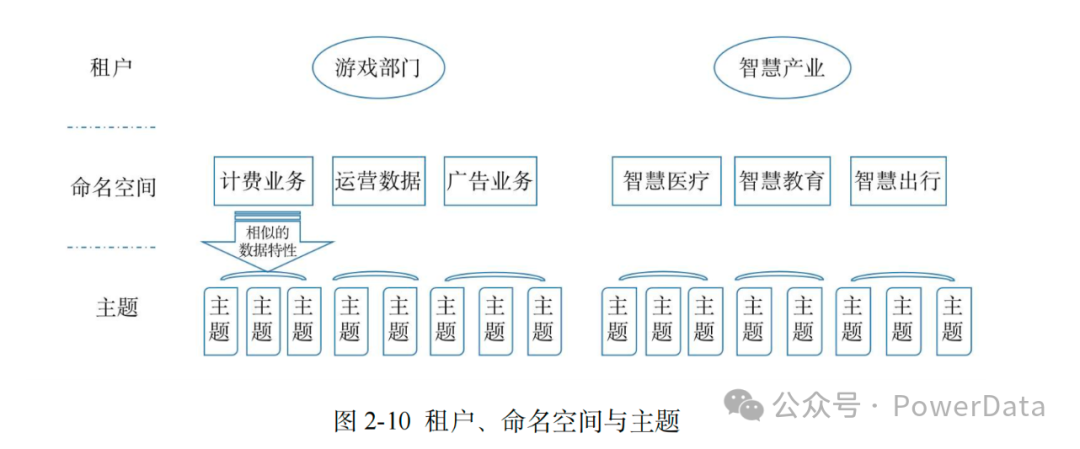
原生多租户的设计使得更加契合云计算场景。
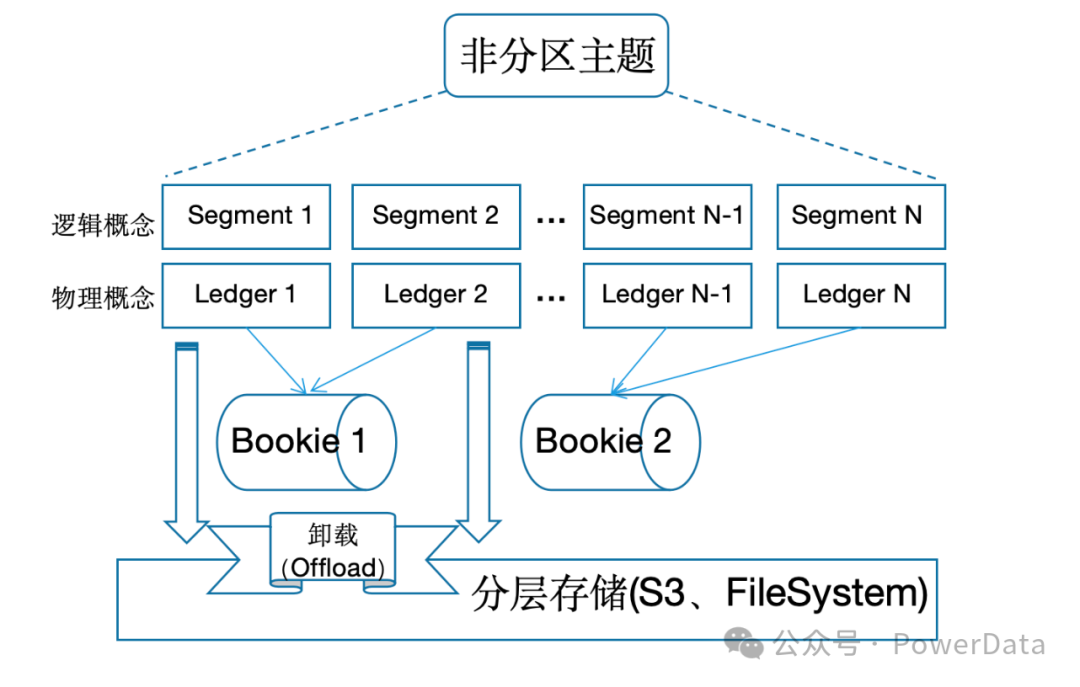
分层存储等功能的引入,使得消息队列可以利用便宜的池化存储降低数据保存成本。
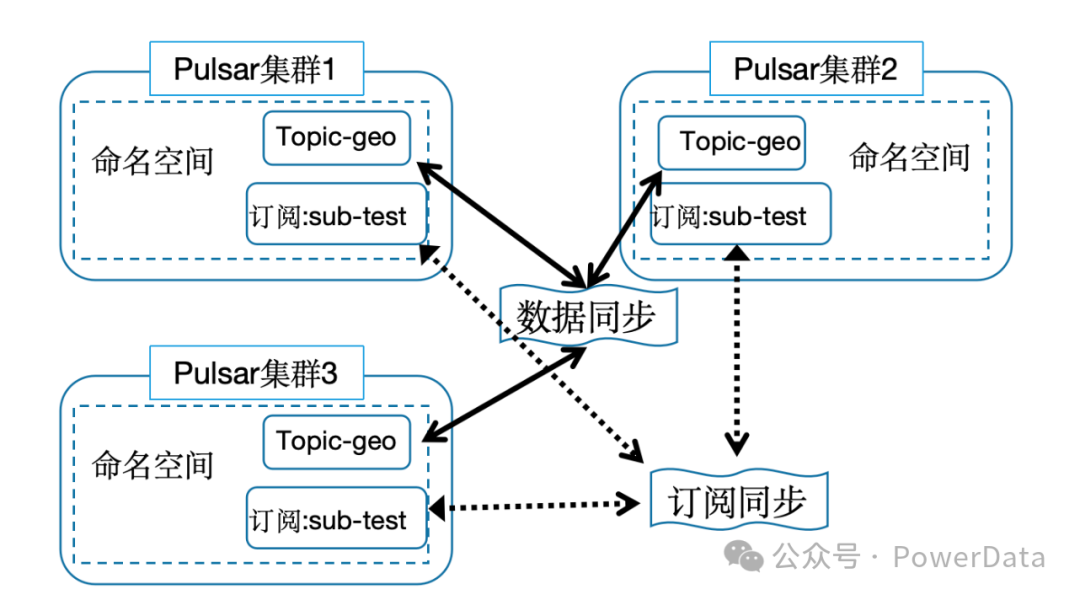
原生支持跨地域复制( Geo-replication),单个实例原生支持多个集群(跨集群复制)功能。
更难的是,在当前消息队列多使用私有化协议的背景下(Pulsar最开始也只支持自身的协议)。Pulsar还支持了多协议的处理器,可以原生支持AMQP/Kafka等多种协议。让基于其他协议的消息队列用户,可以轻松迁移至Pulsar。
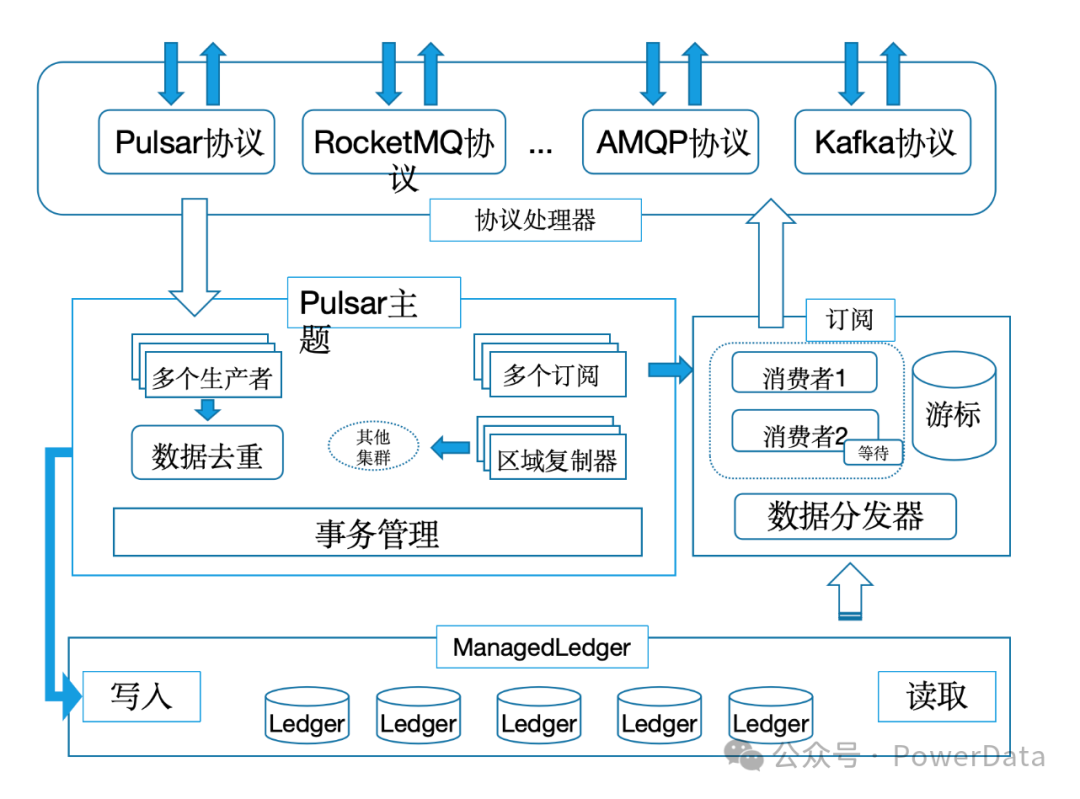
Pulsar还支持多个Consumer共享一个Partition的消费模式,更好的支持了消费的灵活度,这在早期的Kafka和RocketMQ中都不支持。除此之外Pulsar的非持久化Topic功能,使得部分对消息可用性远远高于消息持久性的场景里,能非常灵活的选择非持久化消息场景。
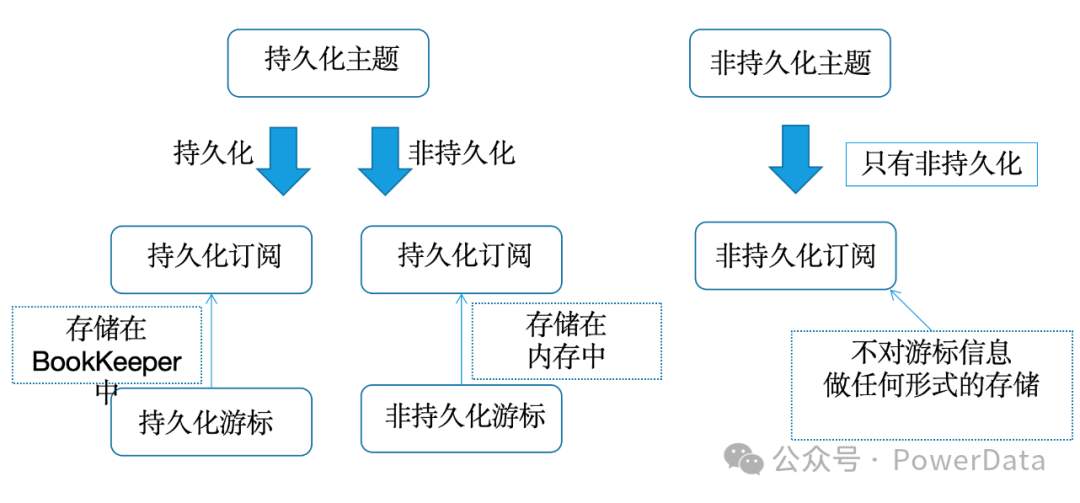
笔者接触Pulsar时,其还是 2.4.x的版本,随着社区的发展和其商业化公司的推动,Pulsar的功能在后续版本中不断完善。Apache Pulsar的设计本身无疑是先进的、具有前瞻性的,若干个Pulsar社区最早Release的功能,后续也逐步在Kafka和RocketMQ中上线。即使是没有使用Pulsar的同学们,Pulsar在下面这些特性方面,都值得我们去学习借鉴。 包括:
-
-
云原生架构设计
存储与计算分离
消息与数据流结合
分层存储
多协议支持
延迟消息、数据集成、sql支持、事务消息。
-
下文选自腾讯中间件团队对外分享的Pulsar生产案例:腾讯中间件团队的用户使用 Kafka 集群来承载业务,由于业务的特定场景,集群的整体流量相对不大,但是需要使用的 Topic 较多。由于 Kafka 自身架构的限定,用户不能在一套集群中创建较多Topic,所以需要部署多套 Kafka 集群来满足业务的使用,导致成本较大。
Pulsar 本身除了具备 Pub-Sub 的传统 MQ 功能外,其底层架构计算存储分离,在存储层分层分片,可以很容易地把 BookKeeper 中的数据 offload 到廉价存储上。Pulsar Functions 是 Serverless 的轻量化计算框架,为用户提供了 Topic 之间中转的能力。在开源之前,Pulsar 已在 Yahoo 经历 5 年的打磨,并且可以轻松扩缩容,支撑多 Topic 场景。为了降低使用成本,同时满足多 Topic 的业务场景,腾讯将Kafka切换为了 Pulsar。替换后,Pulsar可以承载 60W 左右的 Topic。详细的介绍在参考文献中,大家可以自己去查阅。
当然,每一项技术都有其发展原因、适用场景和其局限性。RabbitMQ、Kafka、RocketMQ 等等如此,Pulsar亦是如此。在业界的一些技术分享中,大家普遍会认为消息队列后面会往云原生、容器化、Serverless、Service Mesh 等等方向发展。架构和技术的发展并不是一蹴而就,都是随着需求和外部环境逐渐演化而来。Kafka不是消息队列的最终答案,Pulsar同样也不是。但是他们都是顺应时代需要和设计要求,应运而生的产品。
生命不息,前路不止
随着云原生技术的发展,Serverless、ServiceMess 等应用模式在消息队列领域也在快速发展。区别于IDC时代,云原生时代消息队列也会有其新的机遇。 本文也会列出几家国内的消息队列创业公司,通过他们来一窥消息队列的发展趋势。
首先不得不提的是,Pulsar相关的商业化公司:StreamNative和谙流科技,分别负责Pulsar的国际化市场以及国内市场。
StreamNative 是一家开源基础软件公司,由 Apache 软件基金会顶级项目 Apache Pulsar 创始团队组建而成,围绕 Pulsar 打造下一代云原生批流融合数据平台,专注于开源生态和社区构建,致力于前沿技术领域的创新,创始团队成员曾就职于 Yahoo、Twitter、EMC 等公司。
谙流科技是Apache Pulsar 核心团队打造而成,专门为中国市场提供金融级、云原生和符合信创标准的消息传输和流计算的产品和服务。
其次是Serverless,最早于 2012 年由 Iron 公司提出 ,如同云计算一样,Serverless 形态的产品其实早已经存在。Serverless使得开发者无需关心服务器运维与扩展问题,仅关注业务代码逻辑的实现,由云服务商根据实际请求和事件自动调度计算资源并按需计费。
在 Serverless 时代构建软件系统,消息系统无疑会成为最核心的基础组件。主要有以下先决条件:
● 异步处理:Serverless服务通常作为事件驱动响应者,当有新的数据或事件产生时,消息队列可以作为触发器,将这些事件传递给相应的函数进行处理,从而支持异步编程模式。
● 解耦合:消息系统提供了不同服务之间的松耦合通信机制,使得各个Serverless函数可以在不直接依赖彼此的情况下独立扩展和更新,增强了系统的稳定性和可维护性。
● 流量削峰:通过消息队列作为缓冲,能够有效应流量激增,避免直接冲击Serverless服务,保证服务稳定。
● 事件驱动架构支持:Serverless架构天然适合事件驱动架构,而消息队列正是实现事件驱动的基础组件,通过跨多个服务和功能协调工作流,支持复杂的业务场景。
● 持久化与可靠传输:消息系统能够确保消息的持久化存储和至少一次的交付,这对于Serverless架构中可能出现的瞬态实例非常重要,确保了即使函数实例因闲置而被销毁时,也不会丢失数据。
Vanus(vanus.ai) 是一个开源的无服务器事件流平台,基于 Kubertenes 设计,具备完全的弹性能力,可以根据事件流量动态扩展或缩减集群。Vanus 将存储和计算资源分离,支持 CloudEvents 标准。同时其通过内置函数的方式提供了通用、灵活的过滤和转换能力,可以帮助开发者无代码做事件处理。而且其无缝集成了 Serverless,可以将事件投递给 AWS Lambda、Knative 等云函数与 FaaS 平台。
最后是消息队列在云原生 + 对象存储的探索。在云计算时代,软件定义了硬件,并提供了高可用、高可靠的服务保障。在数仓领域,Snowflake 第一个将数仓完全构建在云服务的对象存储之上,带来了巨大的成本优势和每个用户独占计算资源的多租户隔离效果。而消息队列是一个典型的分布式存储系统,但是市面上还没有一款消息队列构建在云上。AutoMQ 公司为 Kafka 设计了全新架构,完全构建在云厂商的对象存储之上,无需自行实现复杂的分布式多副本复制协议,架构更简洁,成本更低。
结语
三十功名尘与土,八千里路云和月。岳武穆言之,功名不过如尘土,而精忠报国才值得用一生去为之奋斗。在技术领域,我们享受着时代的红利,享受的新技术迭代带来的机遇,也同样需要,尝试以微末之力反馈技术领域。
Pulsar 作为云原生时代消息队列的探路者,集百家之所长,融百家之所思,扬百家之所名,荟灵思之萃,展创新之潮。其优势已经在前文进行了初步探讨,因为受限于文章篇幅,无法纵情展开,部分介绍摘抄自作者的书籍《Apache Pulsar原理解析与应用实践》。后续会更新一系列文章,对当前文章涉及到的内容进行广度与深度扩展。
无论是Kafka、RocketMQ、Pulsar都是集社区力量,集百家之长的优秀开源项目。他们的关系既包含竞争,也相互促进,各有擅长之处,也有不足之处。接下来的一系列文章,作者会尝试从下面两个角度继续探讨这几款消息队列的不同,继续探讨消息队列他们的故事。
这几款消息队列的架构相同与不同之处,以及其擅长的地方。
在社区发展过程中,有哪些技术与其设计理念是相互参考,相互促进的。
COMING SOON!
参考文献
-
Grid® Report for Message Queue (MQ) | Spring 2023
云原生消息流系统 Apache Pulsar 在腾讯云的大规模生产实践
一文了解字节跳动消息队列演进之路
Apache RocketMQ,构建云原生统一消息引擎
消息队列的过去、现在和未来
深入拆解消息队列 47 讲
一文了解字节跳动消息队列演进之路
支持几十种业务场景,字节跳动大规模 Sidecar 运维管理实践
联系我们
“Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。GitHub 地址:http://github.com/apache/pulsar/
”

诚挚邀请您加入 Apache Pulsar 社区,与全球开发者一起学习、分享和成长,共同塑造云原生消息流平台的未来,一起打造更加开放和高效的开源技术生态!

推荐阅读
干货文章
 Apache Pulsar 为滴滴大数据运维带来了哪些收益?
Apache Pulsar 为滴滴大数据运维带来了哪些收益?
 技术探究 | 开篇 | 深度探讨:Apache Pulsar 在事件驱动型业务中的应用
技术探究 | 开篇 | 深度探讨:Apache Pulsar 在事件驱动型业务中的应用

消息队列20年:腾讯专家沉淀的 MQ 设计精要















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









