







NLTK(Natural Language Toolkit)是一个Python模块,提供了多种语料库(Corpora)和词典(Lexicon)资源,如WordNet等,以及一系列基本的自然语言处理工具,包括:分句,标记解析(Tokenization)、词干提取(Stemming)、词性标注(POS Tagging)和句法分析(Syntactic Parsing)等,是对英文文本数据进行处理的常用工具。
为了使用NLTK,需要对其进行安装,可以使用pip包管理工具安装,具体方法为:
pip install nltk
1.1 .常用语料库和词典资源
为了使用NLTK提供的语料库和词典资源,首先需要进行下载。具体方法为:进入Python的控制台(在操作系统控制台下,执行python命令),然后执行以下两行命令:
import nltk
nltk.download()
如果失败了,就采用在:
xnltk_data: 原仓库地址为 https://github.com/nltk/nltk_data.git 因为网络原因,复制到此 (gitee.com)
将下载好的zip文件夹解压,同时重命名里面的package文件夹为nltk_data(一定不要忘记这步骤).
然后将nltk_data。放到以下任意路径下都行:
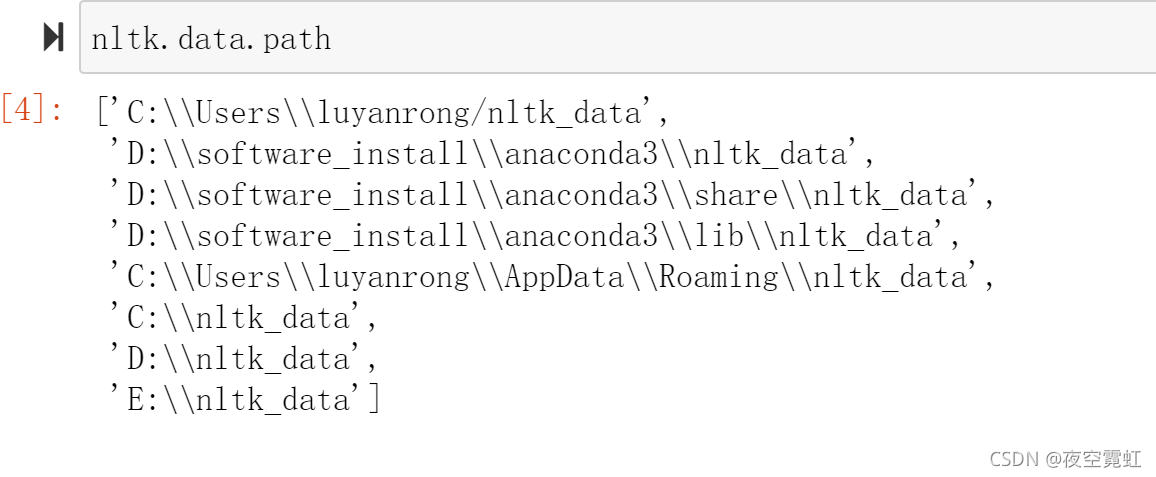
1.停用词
在进行自然语言处理时,有一些词对于表达语言的含义并不重要,如英文中的冠词“a”,"the",介词“of”,"to"等。因此,在对语言进行更深入的处理之前,可以将它们删除,从而加快处理的速度,减小模型的规模。这些词又被称为“停用词”(Stop words)。NLTK提供了多种语言的停用词词表,可以通过下面语句引入停用词词表。
from nltk.corpus import stopwords
stopwords.words('english')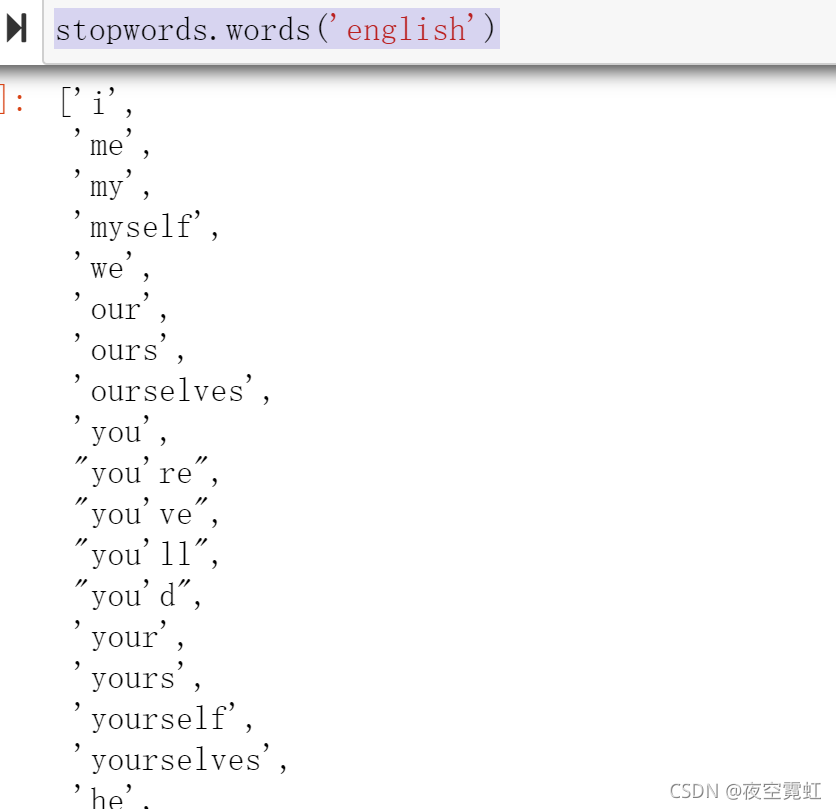
2.常用语料库
NLTK提供了多种语料库(文本数据集),如图书、电影评论和聊天记录等,它们可以被分为两类,即未标注语料库(又称生语料库或生文本,Raw text)和人工标注语料库(Annotated corpus).
(1) 未标注语料库
可以使用两种方式访问之前下载的语料库,第一种是直接访问语料库的原始文本文件(目录为下载数据时选择的存储目录);另一种是调用NLTK提供的相应功能。如通过以下方式,可以获得古腾堡(Gutenberg)语料库(目录为:nltk_data/corpora/gutenberg)中简·奥斯汀(Jane Austen)所著的小说Emma原文。
from nltk.corpus import gutenberg
gutenberg.raw("austen-emma.txt") 
(2) 人工标注语料库
人工标注的关于某项任务的结果。如在句子极性语料库(sentence_polarity)中,包含了10662条来自电影领域的用户评论句子以及相应的极性信息(褒义或贬义)。通过以下命令,可以获得该语料库,其中,褒贬各5331句(经过了小写转换、简单的标记解析等预处理后)
sentence_polarity提供了基本的数据访问方法:
sentence_polarity.categories()返回褒贬义类别列表:['neg','pos']
sentence_polarity.words()返回语料库中全部单词的列表:如果调用时提供类别参数(categories="pos"或“neg”),则会返回相应类别的全部单词列表
sentence_polarity.sents()返回语料库中全部句子的列表,调用时同样可以提供类别参数
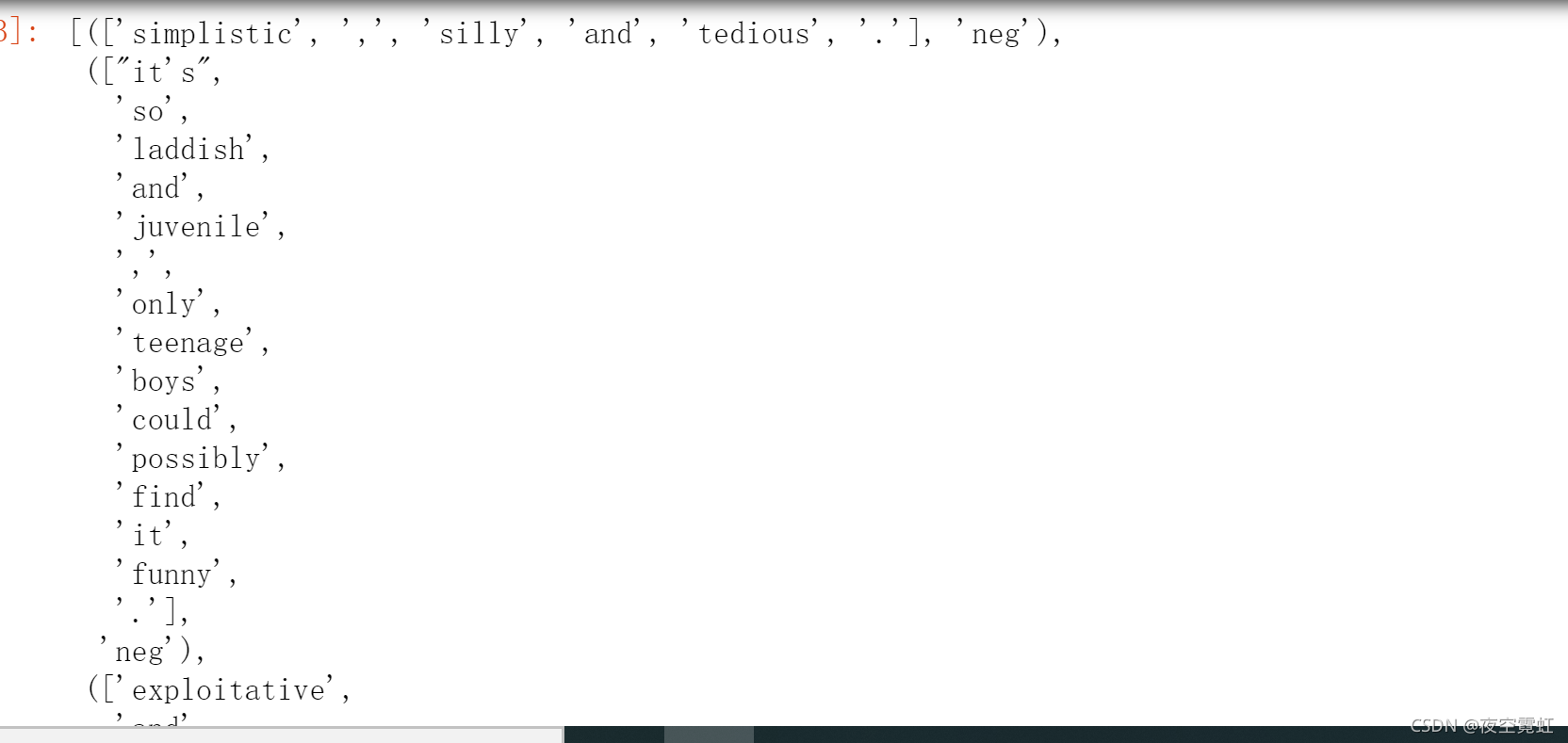
可以使用以上方法的组合,构造出一个大列表,其中每个元素为一个句子的单词列表,其中每个元素为一个句子的单词的列表即其对应的褒贬类别构成的元组:
[(sentence,category)
for category in sentence_polarity.categories()
for sentence in sentence_polarity.sents(categories=category)
]运行结果:
3.常用词典
(1)WordNet
WordNet是普林斯顿大学构建的英文语义词典(也称作辞典,Thesaurus),其主要特色是定义了同义词集合(Synset),每个同义词集合由具有相同意义的词义组成。此外,WordNet为每一个同义词集合提供了简短的释义(Gloss),同时,不同同义词集合还具有一定的语义关系。下面演示WordNet的简单使用示例:
from nltk.corpus import wordnet
syns = wordnet.synsets("bank") # 返回“bank”的全部18个词义的synset
syns[0].name() # 返回“bank”第1个词义的名称,其中“n”表示名词(Noun)
(2)SentiWordNet
SentiWordNet(Sentiment WordNet)是基于WordNet标注的词语(更准确地说是同义词集合)情感倾向性词典,它为WordNet中每个同义词集合人工标注了三个情感值,依次是褒义、贬义和中性。通过该词典,可以实现一个简单的情感分析系统。仍然通过一个例子演示SentiWordNet的使用方法:
from nltk.corpus import sentiwordnet
sentiwordnet.senti_synset('good.a.01')
sentiwordnet.senti_synset('good.a.01').neg_score()
sentiwordnet.senti_synset('good.a.01').pos_score() 
1.2 常用自然语言处理工具集
NLTK提供了多种常用的自然语言处理基础工具,如分句、标记解析和词性标注等,下面简要介绍这些工具的使用方法。
1.分句
通常一个句子能够表达完整的语义信息,因此在进行更深入的自然语言处理之前,往往需要将较长的文档切分成若干句子,这一过程被称为分句。一般来讲,一个句子结尾具有明显的标志,如句号、问号和感叹号等,因此可以使用简单的规则进行分句。然而,往往存在大量的例外情况,如在英文中,句号除了可以作为句尾标志,还可以作为单词的一部分(如Mr.)。NLTK提供的分句功能可以较好地解决此问题。下面演示如何使用该功能:
from nltk.tokenize import sent_tokenize
from nltk.corpus import gutenberg
text = gutenberg.raw("austen-emma.txt")
sentences = sent_tokenize(text) # 对Emma小说全文进行分句
sentences[100] # 显示其中一个句子
(注:这里执行的时候报错了,分句这一句代码。发现\nltk_data\tokenizers中的punkt是个压缩文件,需要解压下,就不报错了)
2.标记解析
一个句子是由若干标记(Token)按顺序构成的,其中标记既可以是一个词,也可以是标点符号等,这些标记是自然语言处理最基本的输入单元,将句子分割为标记的过程叫作标记解析(Tokenization)。英文中的单词之间通常使用空格进行分割,不过标点符号通常和前面的单词连在一起,因此标记解析的一项主要工作是将标点符号和前面的单词进行拆分。
和分句一样,也无法使用简单的规则进行标记解析,仍以符号“.”为例,它即可作为句号,也可以作为标记的一部分,如不能简单地将“Mr."分成两个标记。同样,NLTK提供了标记解析功能,也称作标记解析器(Tokenizer)。下面演示如何使用该功能:
from nltk.tokenize import word_tokenize
word_tokenize(sentences[100])
3.词性标注
词性是词语所承担的语法功能类似,如名词、动词和形容词等,因此词性也被称为词类。很多词语往往具有多种词性,如“fire”,既可以作为名词(“火”),也可以作动词(“开火”)。词性标注就是根据词语所处的上下文,确定其具体的词性。
如在“They sat by the fire.”中,“fire”是名词,而在“They fire a gun.”中,“fire”就是动词。NLTK提供了词性标注器(POS Tagger),下面演示其使用方法。
from nltk import pos_tag
pos_tag(word_tokenize("They sat by the fire"))
pos_tag(word_tokenize("They fire by a gun."))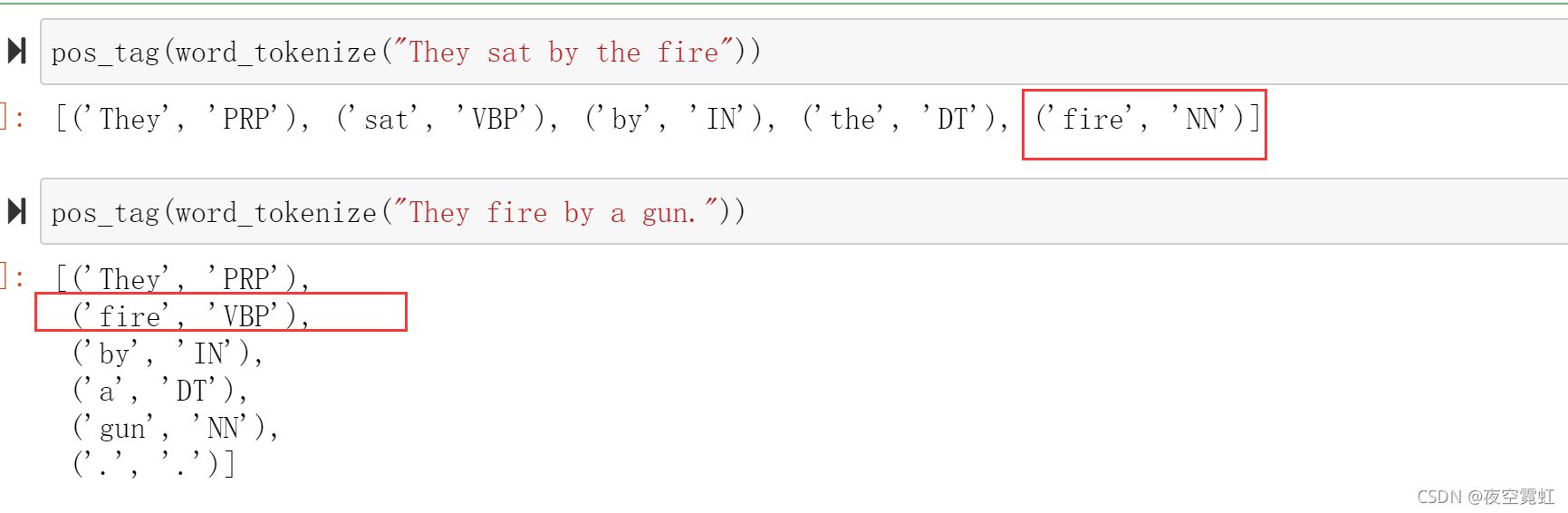
4.其他工具
除了上面介绍的,NLTK还提供了其他丰富的自然语言处理工具,包括命名实体识别、组块分析(Chunking)和句法分析等。
另外,除了NLTK。还有很多其他优秀的自然语言处理基础工具集可供使用,如斯坦福大学使用Java开发的CoreNLP、基于Python/Cython开发的spaCy等,它们的使用方法本书不再进行详细的介绍,感兴趣的读者可以自行查阅相关的参考资料。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









