






Weex是最近很火很NB的一个技术产品,因为本篇介绍的是怎样使用Weex的最佳实践,所以就不罗里吧嗦的夸它怎么怎么好了,感兴趣的可以访问Weex HomePage,或加入旺旺群:1330170019。
利器
俗话说,欲要善其事,必先利其器。对于开发Weex,本人并不推荐裸奔。适合的工具,能让你的工作事半功倍。
快速尝鲜
我们在内网环境搭建了一个在线版的编辑器和预览工具,如果你希望快速尝鲜和试错,可以直接访问http://weex.alibaba-inc.com/playground,并按如下操作即可:
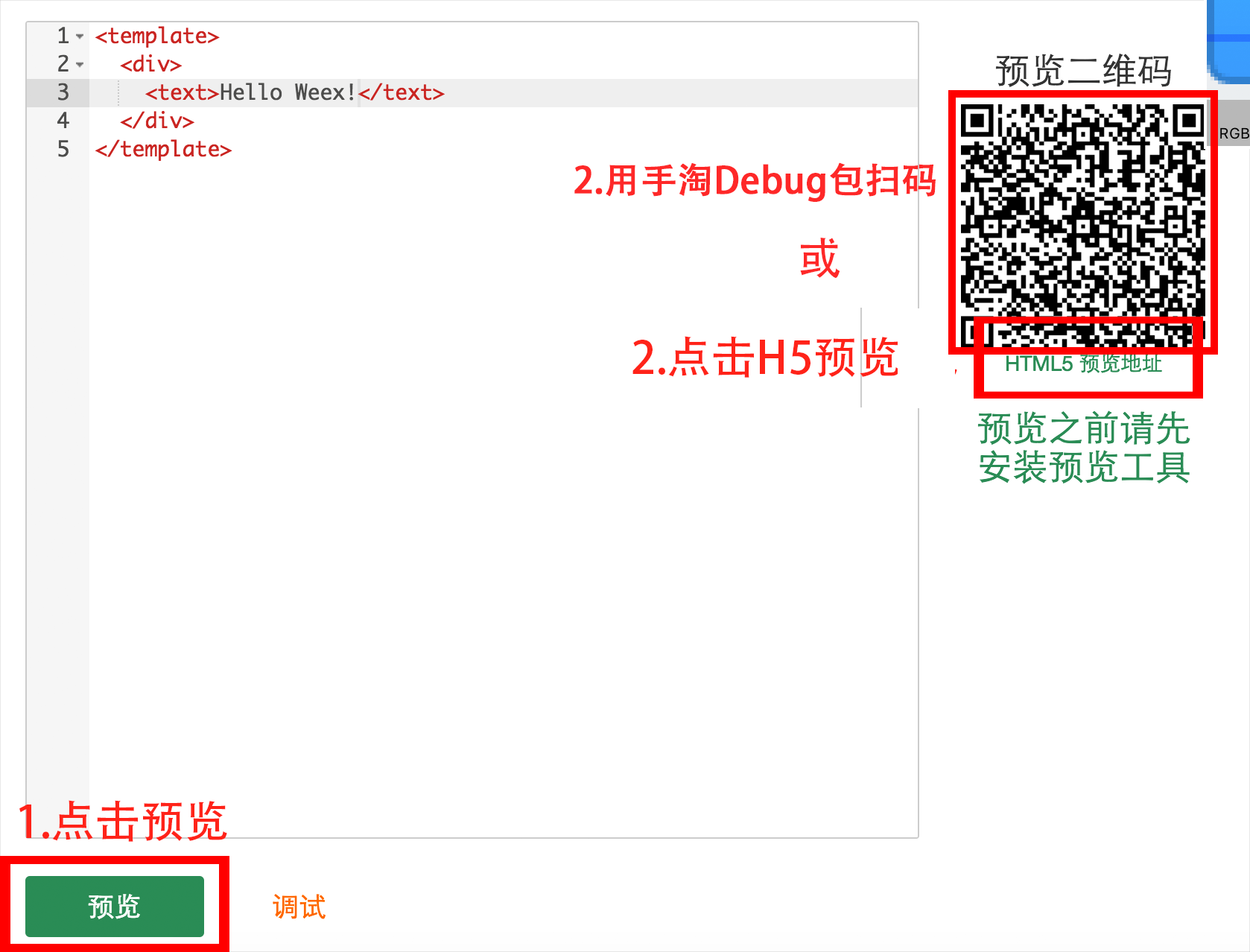
准备开发环境
在进行本地开发之前,你需要准备一台能顺利的运行Bash命令的电脑,比如Mac Book Pro。而对于钟情于Windows的同学来说,Weex的一系列工具并没有对Windows环境做特殊的适配,所以考虑Windows上的开发体验,强烈建议下载一个cmder来运行各种命令。
说完了命令行工具,简单强调下软件环境:Nodejs >= 4.0。
开发单独页面
Weex的一个优势就是能快速开发并上线一个可以运行于三端的页面,为此效率就很重要。所以,本人要推荐Weex的开发利器weex-toolkit。它可以通过npm安装到你本机的全局环境中(npm i weex-toolkit -g),从此你的开发环境下就多了一个神奇的命令weex。
首先,可以用神奇的weex命令创建一个示例文件:
weex create helloworld然后随便编辑点什么,比如:
<template>
<div class="wxc-hellworld">
<text>Hello Weex</text>
</div>
</template>紧接着,再运行那个神奇的命令:
weex helloworld.we猛地会出现一个硕大的二维码,面对这个二维码可千万不要懵圈,请和我一起下载另一个神器Weex Playground。
当用这个神奇的扫码功能扫描这个二维码,就能展示Hello Weex的界面。并且,这个二维码支持Live Reload。任何对helloworld.we的改动都会立即更新Playground里所展示的界面。
搭建完整工程
不过,对于我们这些苦逼的前端攻城师来说,现在任何一个活动都没法用一个简单页面来搞定了,更不用说复杂的产品。所以,一个大而美的工程才能填补心中的阴影。
如果你是一位斑马平台的簇拥者,建议你直接访问斑马平台的帮助文档来完成这件事情:Weex for Zebra。
而接下来,我想要详细阐述的是不依赖特定平台的Weex工程搭建。
脚手架
Adam,亚当,一切之源。用了它,再也不用担心第一次的尴尬了。
好了,硬广时间结束。如果要搭建工程,脚手架是不可获取的。这里推荐一个叫做adam的脚手架工具,不仅简单易用,还能轻松的创建你自己想要的脚手架。首先,通过tnpm安装。
tnpm i @ali/adam -g 然后,添加Weex的脚手架:
adam tpl add weex 紧接着,在某个空目录下,运行adam,并根据提示完成初始化。
脚本
这个脚手架工程中包含了基本的开发命令,通过npm i安装完依赖后,就可以用这些脚本来进行开发了:
转换src目录下的所有.we文件,并输出到dist目录下
npm run build 监听.we文件的改动,并更新dist目录下的相应文件
npm run dev预览H5版页面
npm run serve -- -p 3000在浏览器中打开:http://localhost:3000/index.html?page=dist/welcome.js
生成供Playgorund扫描的二维码
npm run qr -- src/welcome.we启动调试工具(下面有章节具体聊这个事)
npm run debugger有了上述这么多利器,开发Weex真是太爽了!
磨刀不误砍柴工
有了利器后,先不忙着上手,因为你还要先学会怎么操控它,让它能与你人器合一。
文件目录结构
Weex默认的文件结构是要求所有相关的we文件都在同一级目录下,以便能准确的找到依赖的组件,例如:
bar.we
<template>
<div><text>bar</text></div>
</template>foo.we
<template>
<div><bar></bar></div>
</template> 当需要提取一些公共组件,这些公共组件一般存放在一个公共目录下(自建的目录或通过npm安装到node_modules目录),而这样的文件结构,也往往出现在一些完整的项目工程中,当通过上述的脚手架搭建好示例工程手,可以通过前端习惯的require方式来引用非相同目录下的we文件,例如:
components/bar.we
<template>
<div><text>bar</text></div>
</template>foo.we
<template>
<div><bar></bar></div>
</template>
<script>
require('./components/bar')
</script> 其背后的原理,实际上是整个转换和打包过程借助了webpack以及weex-loader,使得其中的模块化定义遵循标准的The way of CommonJS。
引用标准JS文件
有了webpack的助力,在we文件中,也能轻松使用一个符合CommonJS规范的JS文件。例如,通过npm安装了业界No.1的工具库lodash:
foo.we
<template>
<div><text>{{foo + bar}}</text></div>
</template>
<script>
var _ = require('lodash')
module.exports = {
data: {
foo: 'foo',
bar: 'bar'
},
created: function() {
_.assign(this.data, {foo: 'the foo', bar: 'the bar'})
}
}
</script>用上Tomorrow's css和ES2015
如今前端的开发,一般离不开预处理器,比如postcss和babel。在默认的we文件中,即使有webpack的助力,这类预处理器也是对其无能为力的。为此,我们需要拆分这个we文件,让它变成标准的html、css或js文件。
bar.we.html
<template>
<div><text class="hello">Hello {{name}}</text></div>
</template>bar.we.css
.hello {
font-size: 40px;
color: #333;
}bar.we.js
module.exports = {
template: require('./foo.we.html'),
style: require('./foo.we.css'),
data: {
name: 'Weex'
}
} 并且,需要在webpack.config.js中加入几个能解析这些特殊文件的loader:
loaders: [
{
test: /\.we\.js(\?[^?]+)?$/,
loaders: ['weex?type=script']
},
{
test: /\.we\.css(\?[^?]+)?$/,
loaders: ['weex?type=style']
},
{
test: /\.we\.html(\?[^?]+)?$/,
loaders: ['weex?type=tpl']
}
] 之后,仍然使用require的方式来引用这个'we'文件:
foo.we
<template>
<div><bar></bar></div>
</template>
<script>
require('./bar.we.js')
</script> 当分割了we文件后,你就可以分别对其中的css或js文件使用你想要的预处理器。
不过需要特别提醒的是,目前weex-loader只支持module.exports={...}的模块输出方式,所以即使你在js文件中用了ES6的import,但请勿使用export来导出模块
船到桥头自然直
在实际进行Weex开发时,不免遇到一些令人困惑的问题。另外,也有可能写的代码没那么精湛而使得工程质量或产品性能达不到预期。笔者作为js-framework的主要开发者之一,虽然也没写过多少产品代码,但凭借对js-framework的深入理解,以及对众多业务当中槽点的剖析,尽量给大家呈现一些开发上的实践方案。不求最佳,但求最实用。(注:以下观点,不分先后)
调用native提供的模块方法
Weex的代码本身是运行在js的runtime下的,所以为了和native进行通讯,就需要借由hybrid的方式。其中,对于native提供的一系列模块方法,就需要用一种特殊,但直观的方式来调用。
原本,Weex中集成了一些预定义的API,例如this.$sendMtop。但这些预定义API的维护成本过高,因此在最新甚至以后的Weex版本中,会渐渐废弃这类预定义的API,而改用更加通用的方式:
var stream = require('@weex-module/stream')
module.exports = {
ready: function() {
if (stream && stream.sendMtop) {
stream.sendMtop(params, callback)
} else {
console.error('stream.sendMtop is invalid')
}
}
} 这里又再次请出了万能的require,不过和普通的require不同的是,需要指定特定的@weex-module前缀方能正确使用。
慎用或不用异步函数
为了解释异步函数的在Weex中的危害,首先要理解在Weex中产生的两类task。一类,是由Weex控制的js和native交互时产生的task(以下简称Weex的task),比如一系列异步调用native模块方法,或者点击事件等。一类,是系统原生的task(以下简称原生的task),比如setTimeout,Promise。在Weex的task中更新数据时,Weex可以自动更新View。而在原生的task中,因为Weex丧失了控制权,所以无法做到自动更新。这就导致,在原生的task中产生的diff,会滞留直到下一次Weex的task才会被触发更新View。从表面上看,就是在这些原生的task中改变数据后,并没有及时反应到View上。为了,避免这个问题的产生,目前来说并不推荐使用Promise。而对于setTimeout来说,可以使用native提供的timer.setTimeout的模块方法。
生命周期的一二三
Weex当前版本设计了组件的生命周期,以下的一张图可以比较直观的告诉大家在整个生命周期里都做了些什么事情:
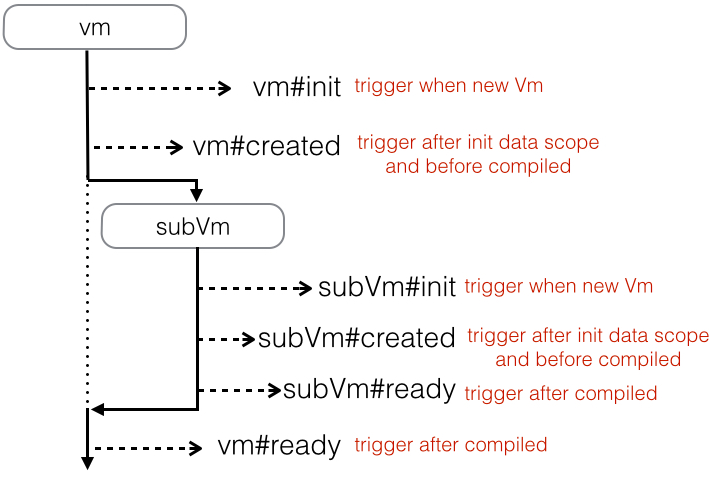
那么在这些生命周期的Hook里,可以做哪些事情呢:
- 在
init中可以进行数据请求,比如mtop。但这个时候上下文中还没有data对象,同时也不建议在之后的任何阶段改变data的数据结构。 - 在
created中,可以对data进行操作了,且此时更新数据不会产生多余的diff,但切忌也不能更改data的数据结构。另外,可以通过this.$on来监听子组件的dispatch。 - 在
ready中,此时子组件已经ready,可以获取子组件的Vm对象了。而此时,如果更新数据,会产生多余的diff。
特别提醒:这三个阶段,都是不允许更改data的数据结构的。
[Bug]设置样式的默认值
来看一个通过改变class来改变样式的例子:
<template>
<div>
<text class="{{className}}" onclick="toggle">Hello Weex</text>
</div>
</template>
<style>
.normal {
font-size: 40px;
}
.hightlight {
font-size: 40px;
color: red;
}
</style>
<script>
module.exports = {
data: {
className: 'normal'
},
methods: {
toggle: function() {
if (this.className === 'normal') {
this.className = 'hightlight'
} else {
this.className = 'normal'
}
}
}
}
</script>上述例子,通过点击来切换样式名。但是你会惊奇的发现,在最初一次切换之后,字体的颜色就一直是红色的了。
这其实是目前Weex一个bug,讨论如何修复的issue在这里#397。原因就是,在Weex中样式表样式的切换,并不会清除原来的样式。例如,当前样式是highlight,其中字体颜色是red,在切换到normal时,因为没有指定字体颜色,结果原来的red颜色就被保留了下来而并没有清除掉。所以,在上面的例子中为了避开这个bug,需要显示的设置字体颜色:
.normal {
font-size: 40px;
color: black;
}另外,对于最佳实践来说,可以通过组合class名称的方式,把需要切换的样式提取出来:
<template>
<div>
<text class="common {{className}}" onclick="toggle">Hello Weex</text>
</div>
</template>
<style>
.common {
font-size: 40px;
}
.normal {
color: black;
}
.hightlight {
color: red;
}
</style>元素上的属性定义
Weex拥有一套类似前端开发习惯的DSL,HTML和CSS部分也都会遵循W3C的标准。其中元素上的属性定义,对于非前端同学来说会有很多误区,这里务必要说明下。
- 属性名必须全部小写,可以使用连接符
-。 - 属性值,尽量保证是原始类型,即
number/string/boolean/undefined/null。对象类型的值一般用于大数据量的数据绑定。 - 一些HTML文章里会推荐在属性上用
data-xxx的方式,这里并不需要特意加data前缀,因为Weex的js中并没有dataset的API可供调用。
搞定子组件的数据绑定
趁热打铁,来说下子组件的数据绑定。因为数据绑定也是通过属性来定义的,所以首先要遵循上一段所说的规则。
- 绑定数据通过属性来定义,不仅需要在使用的元素上指定属性并绑定父组件中的数据,也要在子组件的data中指定对应的键,并且元素上的属性和子组件中的键名的对应规则是:如果属性中有连接符,则键名为去掉连接符后的驼峰写法,否则全部以小写命名。
- 如果仅仅需要给子组件传递数据,而其中的数据结构对父组件是透明的,那么建议直接使用一个属性来映射;如果,属性是子组件的一些功能(且数量小于等于5个),则可以独立开来(基本上和API行为的设计原则差不多),例如:
<we-element name="sub1">
<template>
<div><text>sub1</text></div>
</template>
<script>
module.exports = {
data: {
aMtopData: {}
}
}
</script>
</we-element>
<we-element name="sub2">
<template>
<div><text>sub2</text></div>
</template>
<script>
module.exports = {
data: {
option1: '',
option2: ''
}
}
</script>
</we-element>
<template>
<div>
<sub1 a-mtop-data="{{mtopdata}}"></sub1>
<sub2 option1="{{options.op1}}" options2="{{options.op2}}"></sub2>
</div>
</template>
<script>
module.exports = {
data: {
options: {
op1: 'op1',
op2: 'op2'
},
mtopdata: {}
},
created: function() {
var self = this
this.$sendMtop({...}, function(r) {
self.mtopdata = r.data
})
}
}
</script>遍历长列表
在我们各类大型运营活动的页面中,大家对楼层/坑位这些词应该不陌生。而这些名词的界面,基本都要靠循环列表来完成。而循环列表的性能又是整个运营页面的关键。所以在遍历这样的列表或者数组的时候,就需要一些技巧。
通常来说,因为存在楼层的概念,而楼层里又是多个坑位,坑位又经常是双列宝贝,眼瞅着这得用个三重循环才能搞定。不过实际上,双列宝贝可以优化成不使用循环的结构。当然了,前端的童靴们一定要对着你们的服务端童靴保持坚定立场,要求获得清晰且正确的数据结构,确保前端不需要对数据结构做二次处理。
通常的数据结构和对应的模板一般是这样的:
<template>
<div onclick="update">
<div class="tabheader">
<div repeat="{{headers}}" track-by="name" append="tree">
<text>{{name}}</text>
</div>
</div>
<div class="floor" repeat="{{floor in floors}}" track-by="floorId">
<div class="items" repeat="{{items in floor.items}}" track-by="lineId" append="tree">
<text>{{items.list[0].name}}</text>
<text>{{items.list[1].name}}</text>
</div>
</div>
</div>
</template>
<style>
.tabheader {
flex-direction: row;
}
.items {
flex-direction: row;
}
</style>
<script>
module.exports = {
data: {
floors: [
{
floorId: 1,
name: 'f1',
items:[
{lineId: 1, list: [{itemId:1, name: 'i1'}, {itemId:2, name: 'i2'}]},
{lineId: 2, list: [{itemId:3, name: 'i3'}, {itemId:4, name: 'i4'}]}
]
}
]
},
computed: {
headers: function() {
return this.floors.map(function(v) {
return {name: v.name}
})
}
},
methods: {
update: function() {
this.floors[0].items.push(
{lineId: 3, list: [{itemId:5, name: 'i5'}, {itemId:6, name: 'i6'}]},
{lineId: 4, list: [{itemId:7, name: 'i7'}, {itemId:8, name: 'i8'}]}
)
this.floors.push({
floorId: 2,
name: 'f2',
items: [
{lineId: 5, list: [{itemId:9, name: 'i9'}, {itemId:10, name: 'i10'}]},
{lineId: 6, list: [{itemId:11, name: 'i11'}, {itemId:12, name: 'i12'}]}
]
})
}
}
}
</script> 其中比较常见的数据结构问题,比如items只是一个一维数组。如果能在服务端就处理好items的多维数组问题,那么前端的效率会高很多。
再仔细剖析其中的模板:
<div class="tabheader" repeat="{{headers}}">
...
computed: {
headers: function() {
return this.floors.map(function(v) {
return {name: v.name}
})
}
} 这里绑定了一个computed特性的数据。当某类数据不太适合展示的时候,推荐可以用computed的方式来达到数据预处理的目的,而不是在created中吭哧吭哧的算一份新的数据结构出来。
...
<div repeat="{{headers}}" track-by="name" append="tree">
...
<div class="floor" repeat="{{floor in floors}}" track-by="floorId">
<div class="items" repeat="{{items in floor.items}}" track-by="lineId"> 在这三个repeat中都用了track-by。它的特点是,可以记录数组中某个项的一个主键,并在之后的更新中复用这个特定的项,而不是重构整个数组。例如
楼层1增加两行坑位
this.floors[0].items.push(
{lineId: 3, list: [{itemId:5, name: 'i5'}, {itemId:6, name: 'i6'}]},
{lineId: 4, list: [{itemId:7, name: 'i7'}, {itemId:8, name: 'i8'}]}
)增加一个楼层
this.floors.push({
floorId: 2,
name: 'f2',
items: [
{lineId: 5, list: [{itemId:9, name: 'i9'}, {itemId:10, name: 'i10'}]},
{lineId: 6, list: [{itemId:11, name: 'i11'}, {itemId:12, name: 'i12'}]}
]
}) 如果没有设置track-by,那么Weex会重构整个数组,导致元素被删除后又重新添加。而添加了id作为track-by的主键后,id相同的元素会通过移动的方式来优化操作。
优化长列表
长列表相信大家都做过。Weex中,对列表的优化已经非常接近原生系统的列表了,这个要归功于我们的Native团队。但即使有了性能不错的列表,对于首屏的渲染还是有追求的。
在Weex中,要做无尽列表其实非常简单,因为在list和scroll的元素上,已经实现了onloadmore事件,这个事件会在滚动触底(或者离底部一定的距离)时触发,所以这样看起来,做无尽列表变得非常容易。不过,这样的无尽列表体验绝对算不上极致。这个时候,可以借助loading这个组件,并配合onloading事件,来展现更加出色的无尽列表。
<template>
<list>
<cell repeat="{{v in items}}" track-by="id">
<text>{{v.name}}</text>
</cell>
<loading class="loading" onLoading="loadingHandler">
<text>{{loadingText}}</text>
</loading>
</list>
</template>
<script>
module.exports = {
data: {
index: 0,
size: 50,
count: 10,
loadingText: '加载更多...',
items: []
},
created: function() {
this.addPage()
},
methods: {
addPage: function() {
for (var i = 0; i < this.size; i++) {
var id = this.index * this.size + i
this.items.push({id: id, name: 'item-' + id})
}
this.index++
},
loadingHandler: function() {
if (this.index === this.count) {
this.loadingText = '没有更多了'
} else {
this.addPage()
}
}
}
}
</script>设计优秀的Weex组件
在Weex原生功能越来越丰富的前提下,开发者可以设计出各类符合业务需求的UI组件,这些UI组件基本可以遵循标准的模块化开发,已达到复用和高度定制的目的。
- 用脚手架来初始化Weex组件的仓库再合适不过了。
- Weex是一种数据驱动的设计框架,组件并不是通过API来暴露行为,而是通过数据绑定来给组件设置行为。
- 组件的通信,可以通过
$dispath/$broadcast来完成,不过这得付出一点点性能的代价。而在父组件拿到直接子组件的对象后,其实可以通过$on/$emit来减少性能的开销。 - 如果组件需要高度定制UI,可以考虑使用
content/slot标签,具体可以参考下wxc-marquee。 - 借由脚手架初始化Weex组件工程,可以轻松发布到
npm/tnpm,并且开发者在通过npm install安装后,可以轻松的以require方式来引入这些组件。
调试代码(查看日志)
Weex未来会接入Chrome Dev-tools,甚至Debugger for IDE,这些都可以小小期待下的。而当下可以通过输出日志的原始方式来调试。
在最开始的利器一章中,我已经让大家安装了weex-toolkit,并拥有了weex命令。那么现在要用它来开启调试的大门:
weex --debugger或者在脚手架工程中运行:
npm run debugger 这个时候会输出一段本地的ip地址,在浏览器里输入这个地址,会展示一个二维码。用手淘debug包或Playground扫码之后,就开启了输出日志模式。

在这个界面中,你可以通过选择设备的日志级别,以及展示的输出级别来找到你想要的日志。同时在代码中,可以通过console.log/debug/info/warn/debug来输出相应级别的日志。
在日志debug级别中,以[js framework]开头的,便是js-framework的解析操作。在日志verbose级别中,以Calling JS和Calling Native开头的,就是js和native互相通信的操作。
后记
到今天为止,笔者绞尽脑汁写了这些实践给各位同学。不过笔者承诺,本文涉及到的很多实践会不断的更新和新增,有兴趣的同学收藏本文,并随时欢迎在评论区进行讨论!














 4284
4284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









