




 本文讲解了HTTP请求头headers的作用,如何在爬虫中设置User-Agent,并通过实例演示了如何构造包含cookie和User-Agent的headers。深入理解并利用headers对于网络抓取至关重要。
本文讲解了HTTP请求头headers的作用,如何在爬虫中设置User-Agent,并通过实例演示了如何构造包含cookie和User-Agent的headers。深入理解并利用headers对于网络抓取至关重要。
示例:res = requests.get(url, headers='')
1、什么是headers参数?
其实这里是伪装成浏览器 header是浏览器向服务器发送的一个头信息,上面的代码就是发送了浏览器自己的型号。
2、爬虫的时候怎么传herders参数呢?
随便打开一个网页--->按f12-->点network-->name下随便点一个-->点headers-->往下翻到requests headers-->找到User-Agent便是headers的内容了
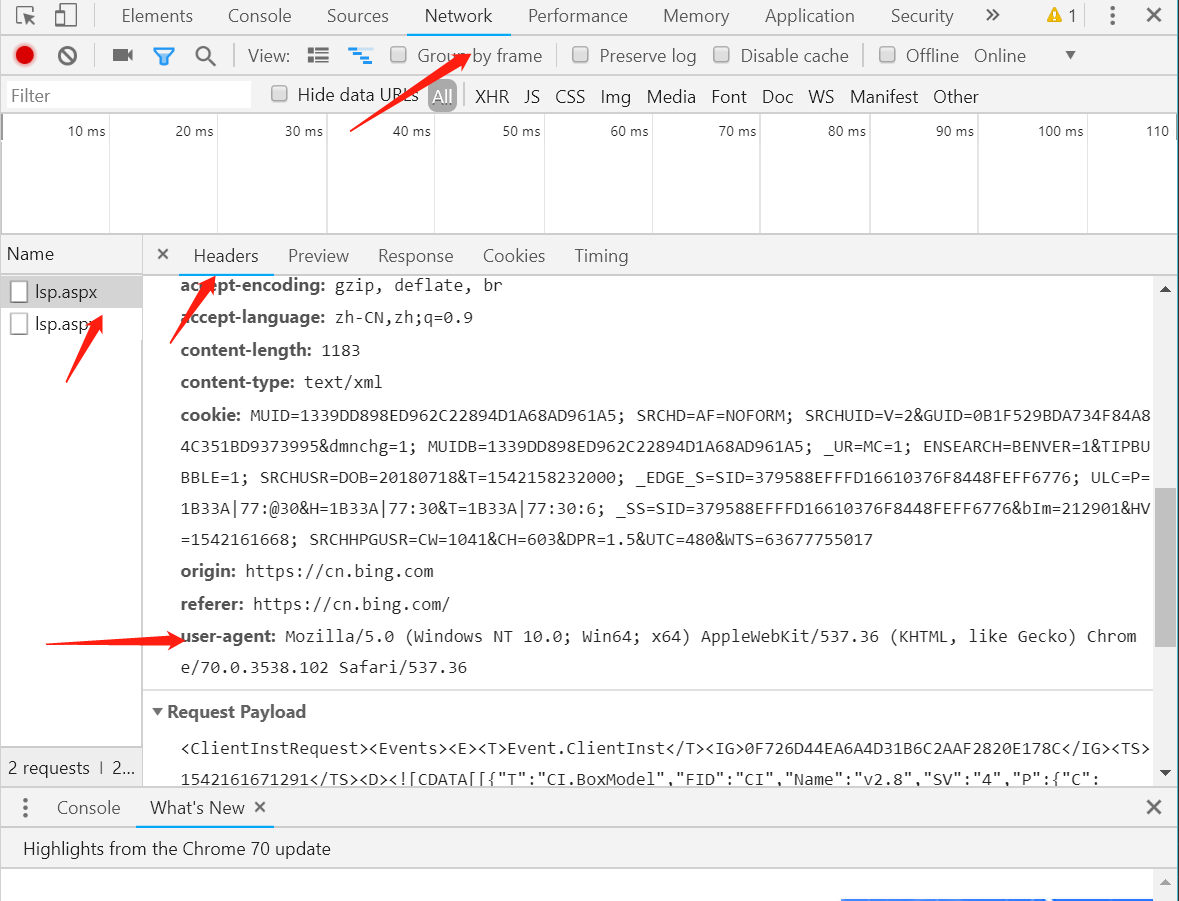
提取后完整示例如下:
headers = {'cookie': 'SINAGLOBAL=7755731542583.8125.1645778146660; _s_tentry=-; Apache=7132237945462.021.1645778388802; ULV=1645778388819:2:2:2:7132237945462.021.1645778388802:1645778146674; SUB=_2A25PHOZ1DeRhGeRM7FIS8i3LyD2IHXVsaFC9rDV8PUNbmtB-LVf5kW9NU8XyUlX9iNdrfCSpw9HLvxBA3GXLIcC0; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5GCsvIfgqNxm9sIRXsBPfv5JpX5KzhUgL.FozES050eoeNe022dJLoIEqLxK-LBo5L12qLxK-LBo5L12qLxKnLB.BLB.zLxK-LBo5L1KykeBtt; ALF=1677314468; SSOLoginState=1645778469', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'}


















 4544
4544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









