




1、日期时间函数
① date_format()函数,
用于以不同的格式显示日期/时间数据
语法: DATE_FORMAT(date,format)
| 格式 | 描述 |
| %Y | 年,如2022 |
| %m | 月,01~12形式表示的月,如05 |
| %d | 日,01~31形式表示的日,如08 |
| %H | 时,00~23形式表示的小时,如23 |
| %i | 分,00~59形式表示的分钟,如59 |
| %S | 秒,00~59形式表示的秒,如59 |
如:DATE_FORMAT(date,'%Y %m %d %H:%i %s')
更多日期时间格式参见: MySQL DATE_FORMAT() 函数 (w3school.com.cn) https://www.w3school.com.cn/sql/func_date_format.asp
https://www.w3school.com.cn/sql/func_date_format.asp
YEAR() 返回统计的年份
MONTH() 返回统计的月份
DAY() 返回统计的天
HOUR() 返回小时值
MINUTE() 返回分钟值
SECOND() 返回秒数
WEEK() 全年第几周
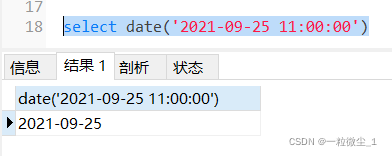
DATE()函数,取年-月-日,示例如下:
② timestampdiff(interval,start_time,end_time)
计算时间差函数,interval代表指定的单位,常用可选:
- YEAR 年数
- MONTH 月数
- DAY 天数(返回秒数差除以3600*24的整数部分)
- HOUR 小时(返回秒数差除以3600的整数部分)
- MINUTE 分钟(返回秒数差除以60的整数部分)
- SECOND 秒
③ datediff(end_time,start_time)
两个日期相减,返回天数,大的值在前
④ timediff(end_time,start_time)
两个日期相减,返回 time 差值(时分秒格式),大的值在前
⑤ last_day(date)
获取某一个月最后一天的日期
SELECT LAST_DAY('2022-04-12') 取2022年4月的最后一天的日期
输出结果:2022-04-30
⑥ date_add()
mysql里查找某一天的后一天的用法是:DATE_ADD(yyyy-mm-dd,INTERVAL 1 DAY)
⑦ date_sub()
函数从日期减去指定的时间间隔,date_sub('2019-07-27', interval 30 day)表示往前推30天
⑧ 不同数据库获取系统日期的函数
| 不同数据库获取系统日期的函数 | |
| DBMS | 函数 |
| Access | NOW() |
| DB2 | CURRENT_DATE |
| MySQL | CURRENT_DATE() |
| Oracle | SYSDATE |
| PostgreSQL | CURRENT_DATE |
| SQL Server | GETDATE |
| SQLite | DATE('now') |
2、文本处理函数
对字符型数据进行操作的函数,SQL中的文本函数有:
| 函数 | 说明 | 使用 |
| left() | 从一个字符串最左边开始返回指定个数的字符 | left(字符串,个数) |
| right() | 从一个字符串最右边开始返回指定个数的字符 | right(字符串,个数) |
| length() | 返回字符串的长度 | length(字符串) |
| upper() | 将字符转大写 | upper(字符串) |
| lower() | 将字符转小写 | lower(字符串) |
| concat() | 将字符拼接在一起 | concat(字符串1,字符串2,…) |
| LTRIM() | 去掉字符串左边的空格 | LTRIM(字符串) |
| RTRIM() | 去掉字符串右边的空格 | RTRIM(字符串) |
| TRIM() | 去掉字符串左右两边的空格 | TRIM(字符串) |
char_length()与length()的区别
无论是LENGTH()还是CHAR_LENGTH()都是为了统计字符串的长度。只不过,LENGTH()是按照字节来统计的,CHAR_LENGTH()是按照字符来统计的。例如:一个包含5个字符且每个字符占两个字节(比如汉字)的字符串而言,LENGTH()返回长度10,CHAR_LENGTH()返回长度是5;如果对于单字节的字符,则两者返回结果相同。
百分比格式表示
CONCAT(字段名,'%')
①substring()函数
- 字符串的截取:substring(字符串,起始位置,截取字符数)
②substring_index()文本分割函数
substring_index(FIELD, sep, n)可以将字段FIELD按照sep分隔:
(1).当n大于0时取第n个分隔符(n从1开始)左边的全部内容;
(2).当n小于0时取倒数第n个分隔符(n从-1开始)右边的全部内容;
③soundex()函数,返回字符串的SOUNDEX值。
SOUNDEX 是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。 SOUNDEX 考虑了类似的发音字符和音节,使得能对字符串进行发音比较而不是字母比较。
如:Customers 表中有一个顾客Kids Place ,其联系名为 Michelle Green 。
SELECT cust_name, cust_contact
FROM Customers
WHERE SOUNDEX(cust_contact) = SOUNDEX('Michael Green');
④group_concat()将多行合并成一行(比较常用)
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
示例:group_concat(distinct concat(date,':',tag) separator ';')
⑤concat()字符串拼接
语法:concat(字符串1,字符串2,…)
⑥concat_ws()函数
功能:一次性指定分隔符
语法:concat_ws(separator,str1,str2,...)
说明:第一个参数指定分隔符 分隔符不能为空 如果为NULL 则返回值NULL
⑦replace() 替换函数
语法:replace(字符串,原字符,新字符)
3、数值处理函数
| 函数 | 说明 |
| COUNT( ) | 计数,COUNT(*)所有,COUNT(指定列名)统计非空(NULL)行 |
| SUM( ) | 求和 |
| AVG( ) | 求平均值, 函数忽略列值为 NULL 的行 |
| MAX( ) | 最大值,忽略为NULL的行,如用于文本则返回最后一行 |
| MIN( ) | 最小值,忽略为NULL的行,如用于文本则返回最前一行 |
| ABS() | 返回一个数的绝对值 |
| PI() | 返回圆周率 |
此外还有:
Exp() --返回一个数的指数值,用法:Exp(数值)
Round() --将数值四舍五入为指定数值,用法:Round(数值,返回的小数位)
Rand(N) --产生随机数,如果有 N,则每次产生的随机数一样,范围从 0~1,如果没有 N,则每次产生的随机数不一样,范围还是 0-1。
LOG(X) --返回X的自然对数
Ceil(X) --生成不小于X的最小整数。如select ceil(3.1)--结果为4
Floor(X) --生成不大于X的最大整数。如select floor(3.1)--结果为3
- 四舍五入
ROUND(要舍入的字段,规定要返回的小数位数可以为0) - 向上取整:
FLOOR(字段) - 向下取整:
CEILING(字段)
数据格式转换
- CAST(字段名 AS 格式类型 )
- SQL常用的格式类型
- 二进制:BINARY
- 字符型: CHAR
- 日期 : DATE
- 时间: TIME
- 日期时间型 : DATETIME
- 浮点数 : DECIMAL
- 整数 : SIGNED
- 无符号整数 : UNSIGNED
# 注意一般数据库默认都是unsigned, 是不能出现负数的, 可用cast(字段 as signed)即可
4、控制函数
CASE WHEN 这个函数比较重要,是我们做数据透视要用到的函数。
-- 语法
case
when 列满足条件 1 then 结果 1
when 列满足条件 2 then 结果 2
else 返回默认值
end
5、窗口函数
窗口函数,又叫 OLAP 函数,MySQL 8 以上的版本才支持。
-- 语法
窗口函数()over (partition by 分区的字段 order by 排序的字段 desc/asc)
窗口函数语法解释:
• over:指定函数执行的窗口范围,若 over 后什么都不写,则指定满足 where 条件的所有行
• partition by:按哪些字段进行分组
• order by:按哪些字段进行排序
1)排序函数:
要显示排序的名次时,用到排序窗口函数,有 3 种用于排序的窗口函数:
①row_number()
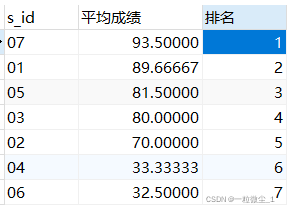
这个函数赋予唯一的连续位次,会根据顺序计算。如:
-- 查询学生的平均成绩及其名次
select s_id,avg(score) as '平均成绩',
row_number() over(order by avg(score) DESC) as '排名'
from sc
group by s_id
②rank()
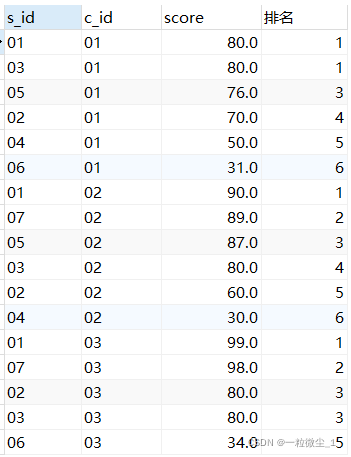
在计算排序时,排序相同时名次会重复,但会保留名次空缺,排序总数不会变。
语法:rank()over (partition by 分区的字段 order by 排序的字段 desc/asc……),order by后面可以跟多个字段进行排序
示例:select *,rank() over(PARTITION by c_id order by score desc,……) as '排名' from sc
③dense_rank()
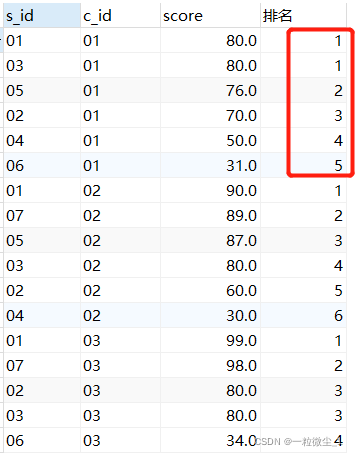
在计算排序时,若存在相同位次, 不会跳过之后的位次。排序相同时会重复, 总数会减少。
④ nth_value(measure_expr, n) 函数从结果集中获取第N行的值
- 计算第二慢用时,取按试卷分区耗时倒排第二名:
- NTH_VALUE(measure_expr, 2) OVER (PARTITION BY …… ORDER BY …… DESC)
- 计算第二快用时,取按试卷分区耗时正排第二名:
- NTH_VALUE(measure_expr, 2) OVER (PARTITION BY …… ORDER BY …… ASC)
2)分布函数:
对某个记录,看它低于/高于归属组内的比例(累计占比/分位数),通常有 2 种函数:
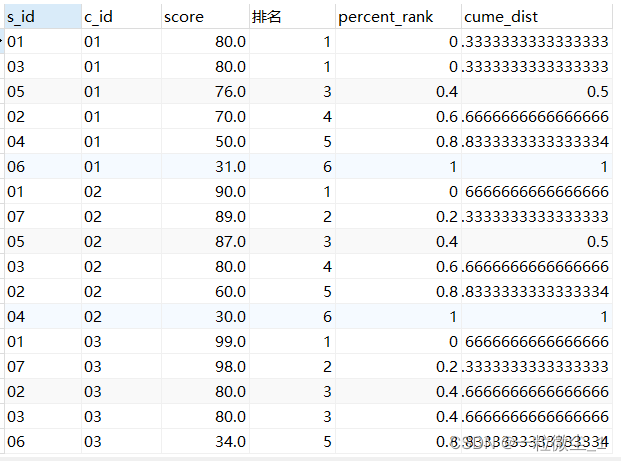
①percent_rank()
-- 语法
percent_rank()over (partition by 分区的字段 order by 排序的字段 desc/asc)
每行:(rank - 1)/(rows - 1)
如有重复值,取重复的第一行的值
②cume_dist()
-- 语法
cume_dist()over (partition by 分区的字段 order by 排序的字段 desc/asc)
每行:rank/rows
如有重复值,取重复的最后一行的值
3)前后函数:
求当前行的前 N 行或后 N 行的值,注意前后函数和其他窗口函数的区别是要指定字段。
①Lead()
-- 语法
Lead(字段,N) over (partition by 分区的字段 order by 排序的字段 desc/asc)
当前行之后第 N 行对应的字段的值
select *,Lead(score,3) over(PARTITION by c_id order by score desc) as '排名' from sc
②Lag()
-- 语法
Lag(字段,N) over (partition by 分区的字段 order by 排序的字段 desc/asc)
当前行之前第 N 行对应的字段的值
select *,Lag(score,3) over(PARTITION by c_id order by score desc) as '排名' from sc
4)头尾函数:
求第一个/最后一个字段的值
注意和最大最小值的区别。如果排序了,头尾函数就是最大最小值,但如果没有排序,头尾函数就是第一个和最后一个值。
①first_value()
-- 语法
first_value(字段)over (partition by 分区的字段 order by 排序的字段 desc/asc)
指定字段在不同分区里的第一个字段的值
②last_value()
-- 语法
last_value(字段)over (partition by 分区的字段 order by 排序的字段 desc/asc)
指定字段在不同分区里的最后一个字段的值
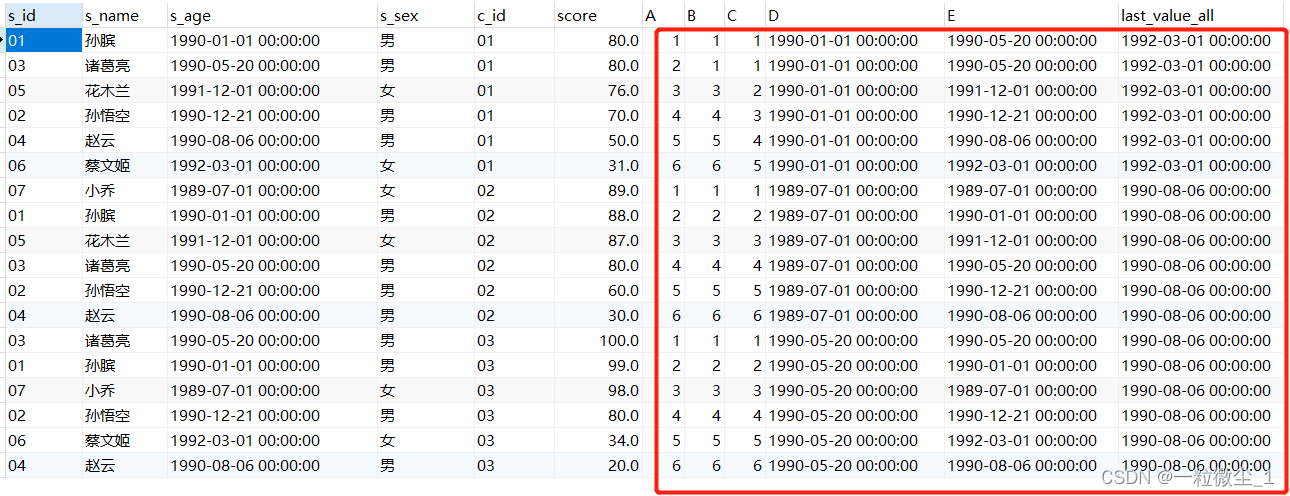
first_value()很直观,就是第一行的值
但last_value()很奇怪,为什么每一条记录都不一样。原因是:其默认统计范围是 rows between unbounded preceding and current row(无界前一行和当前行之间的行),修改为rows between unbounded preceding and unbounded following(无界前后行之间的行)即可。
示例:
select * ,
row_number() over (partition by c_id order by score desc) A,
rank() over (partition by c_id order by score desc) as B,
dense_rank() over (partition by c_id order by score desc) as C,
first_value(s_age) over (partition by c_id order by score desc) as D,
last_value(s_age) over (partition by c_id order by score desc) as E,
last_value(s_age) over (partition by c_id order by score desc
rows between unbounded preceding and unbounded following) as last_value_all
from (select a.*,b.c_id,b.score
from student a,sc b
where a.s_id=b.s_id) as t

运行结果:
6.聚类窗口函数
和聚类窗口函数的用法和GROUP BY 函数类似。
- MIN()OVER() :不改变表结构的前提下,计算出最小值
- MAX()OVER():不改变表结构的前提下,计算出最大值
- COUNT()OVER():不改变表结构的前提下,计数
- SUM()OVER():不改变表结构的前提下,求和
- AVG()OVER():不改变表结构的前提下,求平均值
- rows……preceding
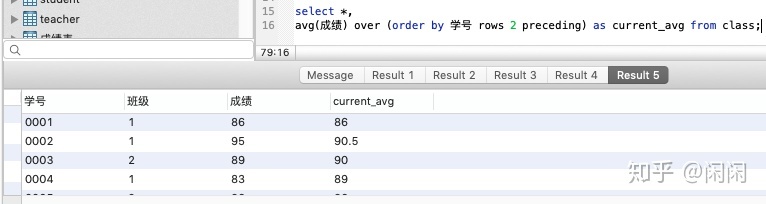
上面的窗口函数中,用了rows和preceding这两个单词,是“之前......行”的意思。也就是说每一行得到的结果是自身记录及前2行的平均。想要计算当前行与前N行(共N➕1)的平均时,只要调整rows.....preceding中间的数字即可。
7.exists和not exists
- 当存在0级用户未完成试卷数大于2时:
- 筛选存在性条件:WHERE EXISTS (SELECT uid FROM t_tag_count WHERE
level= 0 AND incomplete_cnt > 2) - 输出每个0级用户的试卷未完成数和未完成率:
- 筛选0级用户:
level= 0 - SELECT uid, incomplete_cnt, incomplete_rate
- 筛选0级用户:
- 筛选存在性条件:WHERE EXISTS (SELECT uid FROM t_tag_count WHERE
- 当不存在0级用户未完成试卷数大于2时:
- 筛选存在性条件:WHERE NOT EXISTS (SELECT uid FROM t_tag_count WHERE
level= 0 AND incomplete_cnt > 2) - 输出所有有作答记录的用户的这两个指标:
- 筛选有作答记录的用户:total_cnt > 0
- SELECT uid, incomplete_cnt, incomplete_rate
- 筛选存在性条件:WHERE NOT EXISTS (SELECT uid FROM t_tag_count WHERE
- 合并上述结果,条件互斥,so只可能有一个结果集:UNION ALL
8.with ……as……
WITH AS短语,也叫做子查询部分,定义一个SQL片断后,该SQL片断可以被整个SQL语句所用到。有的时候,with as是为了提高SQL语句的可读性,减少嵌套冗余。
例如:with A as (select * from class)
后续就可以用A代替子查询部分
也可以创建多个临时表,方法如下:
with A as (select * from class), B as(select * from classical), ……

















 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









