







ForkJoinPool线程池最大的特点就是分叉(fork)合并(join),将一个大任务拆分成多个小任务,并行执行,再结合工作窃取模式(worksteal)提高整体的执行效率,充分利用CPU资源。
一. 应用场景
ForkJoinPool使用分治算法,用相对少的线程处理大量的任务,将一个大任务一拆为二,以此类推,每个子任务再拆分一半,直到达到最细颗粒度为止,即设置的阈值停止拆分,然后从最底层的任务开始计算,往上一层一层合并结果,简单的流程如下图:

从图中可以看出ForkJoinPool要先执行完子任务才能执行上一层任务,所以ForkJoinPool适合在有限的线程数下完成有父子关系的任务场景,比如:快速排序,二分查找,矩阵乘法,线性时间选择等场景,以及数组和集合的运算。
下面是个简单的代码示例计算从1到1亿之间所有数字之和:
package com.javakk;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
/**
* ForkJoinPool求和
* @author 老K
*/publicclassForkJoinPoolTest{
privatestatic ForkJoinPool forkJoinPool;
/**
* 求和任务类继承RecursiveTask
* ForkJoinTask一共有3个实现:
* RecursiveTask:有返回值
* RecursiveAction:无返回值
* CountedCompleter:无返回值任务,完成任务后可以触发回调
*/privatestaticclassSumTaskextendsRecursiveTask<Long> {
privatelong[] numbers;
privateint from;
privateint to;
publicSumTask(long[] numbers, int from, int to){
this.numbers = numbers;
this.from = from;
this.to = to;
}
/**
* ForkJoin执行任务的核心方法
* @return
*/@Overrideprotected Long compute(){
if (to - from < 10) { // 设置拆分的最细粒度,即阈值,如果满足条件就不再拆分,执行计算任务long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
} else { // 否则继续拆分,递归调用int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
publicstaticvoidmain(String[] args){
// 也可以jdk8提供的通用线程池ForkJoinPool.commonPool// 可以在构造函数内指定线程数
forkJoinPool = new ForkJoinPool();
long[] numbers = LongStream.rangeClosed(1, 100000000).toArray();
// 这里可以调用submit方法返回的future,通过future.get获取结果
Long result = forkJoinPool.invoke(new SumTask(numbers, 0, numbers.length - 1));
forkJoinPool.shutdown();
System.out.println("最终结果:"+result);
System.out.println("活跃线程数:"+forkJoinPool.getActiveThreadCount());
System.out.println("窃取任务数:"+forkJoinPool.getStealCount());
}
}输出结果(活跃线程数和窃取任务会根据本地环境和任务执行情况变化):
最终结果:5000000050000000
活跃线程数:4
窃取任务数:12上例中在compute方法里拆分的最小粒度是10个元素,大家可以改成其他的值试下,会发现执行的效率差别很大,所以要注意拆分粒度对性能的影响。
ForkJoinPool内部的队列能够保证执行任务的顺序,至于为什么它能够在有限的线程数量下完成非常多的任务,后面会讲到。
二. 与ThreadPoolExecutor原生线程池的区别
ForkJoinPool和ThreadPoolExecutor都实现了Executor和ExecutorService接口,都可以通过构造函数设置线程数,threadFactory,可以查看ForkJoinPool.makeCommonPool()方法的源码查看通用线程池的构造细节。
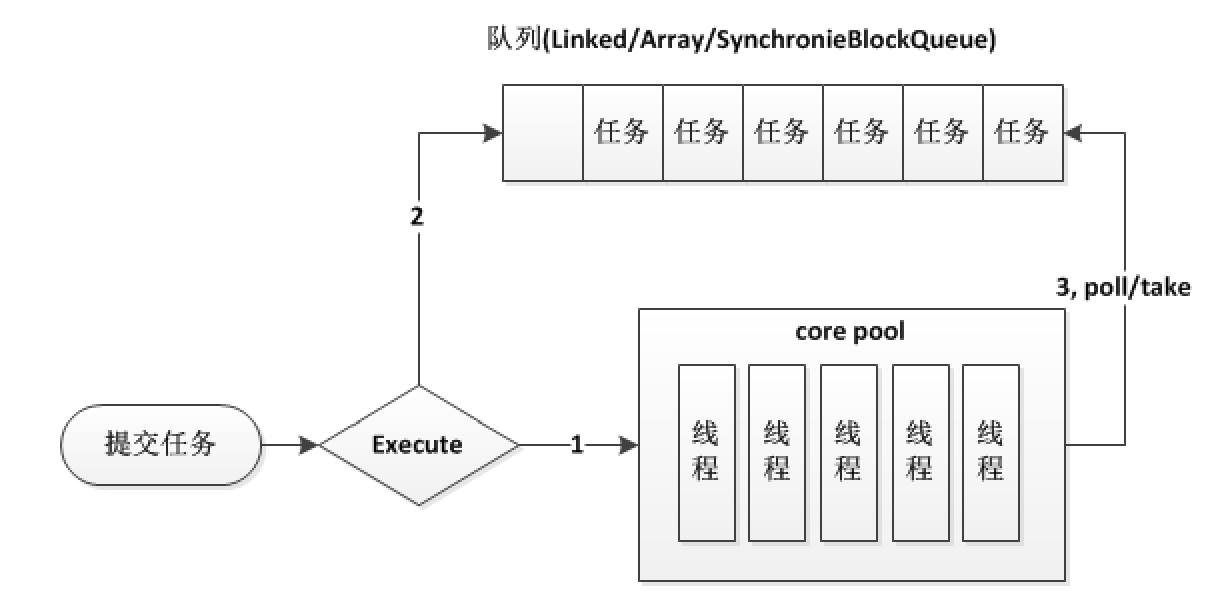
在内部结构上我觉得两个线程池最大的区别是在工作队列的设计上,如下图
ThreadPoolExecutor:
ForkJoinPool:
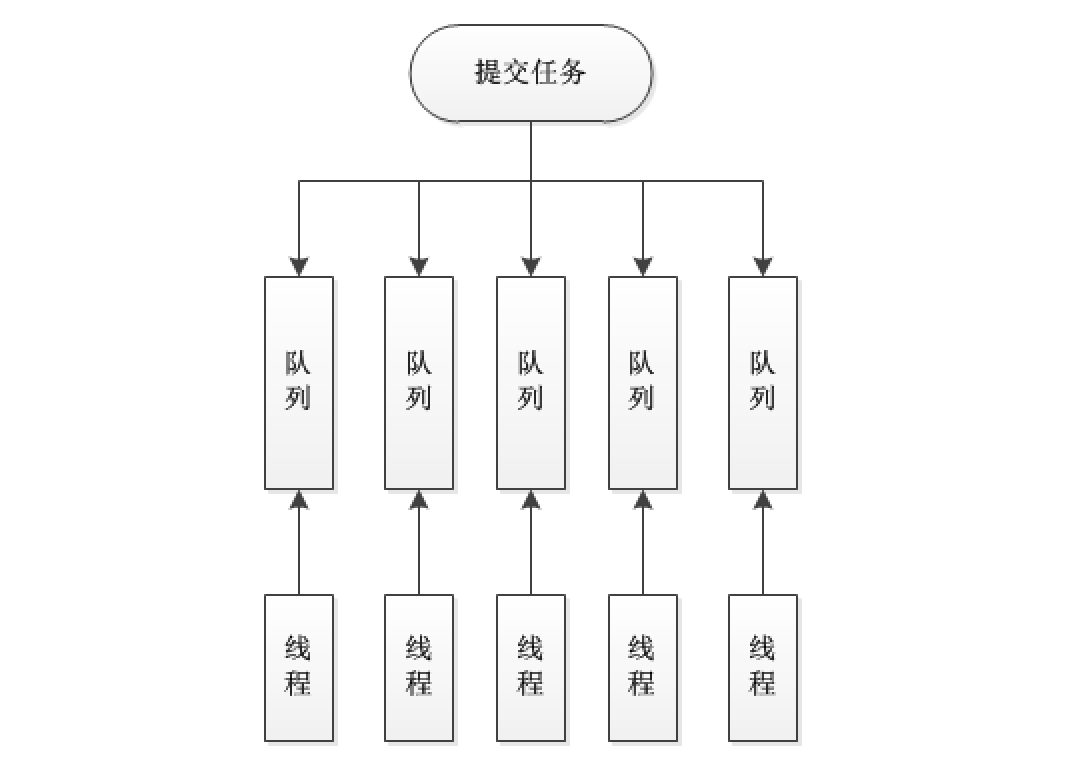
图上细节画的不严谨,但大致能看出区别:
ForkJoinPool每个线程都有自己的队列
ThreadPoolExecutor共用一个队列
通过上面的代码示例可以看到使用ForkJoinPool可以在有限的线程数下来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过2000万个任务。但是使用ThreadPoolExecutor是不可能的,因为ThreadPoolExecutor中的线程无法选择优先执行子任务,要完成2000万个具有父子关系的任务时,就需要2000万个线程,这样会导致ThreadPoolExecutor的任务队列撑满或创建的最大线程数把内存撑爆直接gg。
ForkJoinPool最适合计算密集型任务,而且最好是非阻塞任务,之前的一篇文章:Java踩坑记系列之线程池 也说了线程池的不同使用场景和注意事项。
所以ForkJoinPool是ThreadPoolExecutor线程池的一种补充,是对计算密集型场景的加强。
三. 工作窃取的实现原理
第一节的代码示例输出结果显示活跃线程是4个,但却完成了2000万个子任务,窃取任务是12个(窃取数跟拆分层级和计算复杂度有关),这是work steal工作窃取的作用。
ForkJoinPool类中的WorkQueue正是实现工作窃取的队列,javadoc中的注释如下:

大意是大多数操作都发生在工作窃取队列中(在嵌套类工作队列中)。这些是特殊形式的Deques,主要有push,pop,poll操作。
Deque是双端队列(double ended queue缩写),头部和尾部任何一端都可以进行插入,删除,获取的操作,即支持FIFO(队列)也支持LIFO(栈)顺序。
Deque接口的实现最常见的是LinkedList,除此还有ArrayDeque,ConcurrentLinkedDeque等
工作窃取模式主要分以下几个步骤:
每个线程都有自己的双端队列
当调用fork方法时,将任务放进队列头部,线程以LIFO顺序,使用push/pop方式处理队列中的任务
如果自己队列里的任务处理完后,会从其他线程维护的队列尾部使用poll的方式窃取任务,以达到充分利用CPU资源的目的
从尾部窃取可以减少同原线程的竞争
当队列中剩最后一个任务时,通过cas解决原线程和窃取线程的竞争
流程大致如下所示:

工作窃取便是ForkJoinPool线程池的优势所在,在一般的线程池比如ThreadPoolExecutor中,如果一个线程正在执行的任务由于某种原因无法继续运行,那么该线程会处于等待状态,包括singleThreadPool,fixedThreadPool,cachedThreadPool这几种线程池。
而在ForkJoinPool中,那么线程会主动寻找其他尚未被执行的任务然后窃取过来执行,减少线程等待时间。
JDK8中的并行流(parallelStream)功能是基于ForkJoinPool实现的,另外还有java.util.concurrent.CompletableFuture异步回调future,内部使用的线程池也是ForkJoinPool,有兴趣的同学可以看下这篇文章:Java异步编程指南














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









