







探究Lucene计算权重的过程
我们知道,影响一个词在一篇文档中的重要性主要有两个因素:
1 term frequency (tf):该词在当前文档出现了多少次,tf越大,说明越重要。
2 document frequency (df):有多少文档包含该term,该词越大说明太普通了,越不重要。
| 比如solr一词在文档中出现次数很多,说明这篇这篇文档主要是跟solr有关的;那比如the this it which 诸如此类的词,也很多,但重要吗,很明显不重要,为什么?因为每一篇文档可能都有很多这样的词,所以这时候就是由df来决定了。 |
计算权重的公式如下:
Wt,d = tft,d * log(n / dft)
| Wt,d:词在文档中的权重 tft,d:词在该文档中出现的频率次数 n: 文档总数 dft:包含这个词的文档的数量 |
当然,不同的系统可能有自己不同的实现。
VSM: 向量空间模型算法
1 我们把文档看做一系列的词
2 每一个词在文档中都有自己的权重
3 不同的词根据自己在文档中的权重来影响文档打分
4 我们把文档中词的权重看做一个向量:
Document Vector = {weight1, weight2, …… ,weight N}
5 我们把Query也用向量表示
Query Vector = {weight1, weight2, …… , weight N}
6 我们把搜索出来的文档向量和query向量放在一个N维空间,每一个term是一个维度。
7 我们认为两个向量之间的夹角越小,相关性越大。所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分高,相关性越大
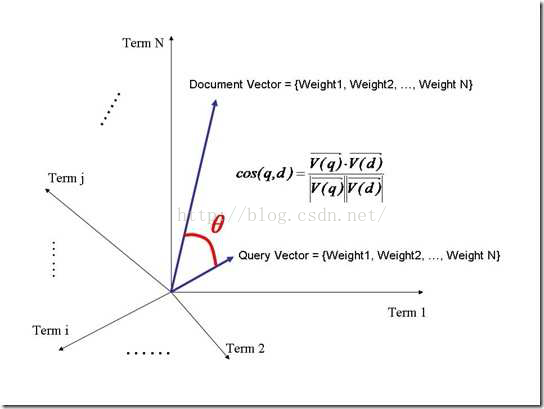

| 查询语句一般是很短的,包含的词(Term)是很少的,因而查询向量的维数很小,而文档很长,包含词(Term)很多,文档向量维数很大。你的图中两者维数怎么都是N呢?在这里,既然要放到相同的向量空间,自然维数是相同的,不同时,取二者的并集,如果不含某个词(Term)时,则权重(Term Weight)为0 |
举例子:
查询语句共有3个term, 文档共有5个term
|
| Term1 | Term2 | Term3 | Term4 | Term5 |
| Document1 | 0 | 0.179 | 0 | 0.66 | 0.345 |
| Document2 | 0 | 0.245 | 0.123 | 0.66 | 0.8 |
| Query | 0.154 | 0 | 0 | 0.66 | 0.5 |
计算2篇文档跟查询语句的相关性打分分别为:
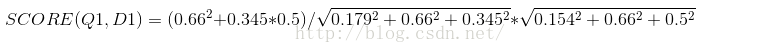
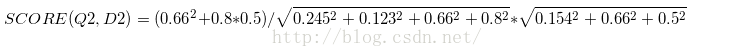
得到的结果第二个比第一个大,所以返回的结果第二个排在第一个前面















 2315
2315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











