






CART(Classification And Regression Tree),是一种基于局部的回归算法,通过将数据集切分为多份,在每一份数据中单独建模。
CART回归树的主要步骤:1、 CART树的生成 2、 回归树的剪枝
CART分类树用Gini指数作为划分属性的指标,但在CART回归树中,样本的标签是一系列的连续值,不能再使用Gini指数作为指标,因此使用均方差作为回归树的指标。设有m个数据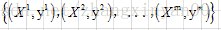
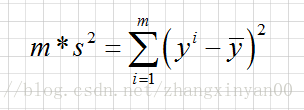
# coding:UTF-8
'''
Date:20161030
@author: zhaozhiyong
'''
import numpy as np
import pickle as pickle
import pdb
from graphviz import Digraph
#from Draw import BTree
class node:
'''树的节点的类
'''
def __init__(self, fea=-1, value=None, results=None, right=None, left=None):
self.fea = fea # 用于切分数据集的属性的列索引值
self.value = value # 设置划分的值
self.results = results # 存储叶节点的值
self.right = right # 右子树
self.left = left # 左子树
def load_data(data_file):
'''导入训练数据
input: data_file(string):保存训练数据的文件
output: data(list):训练数据
'''
data = []
f = open(data_file)
for line in f.readlines():
sample = []
lines = line.strip().split("\t")
for x in lines:
sample.append(float(x)) # 转换成float格式
data.append(sample)
f.close()
return data
def split_tree(data, fea, value):
'''根据特征fea中的值value将数据集data划分成左右子树
input: data(list):训练样本
fea(float):需要划分的特征index
value(float):指定的划分的值
output: (set_1, set_2)(tuple):左右子树的聚合
'''
set_1 = [] # 右子树的集合
set_2 = [] # 左子树的集合
for x in data:
if x[fea] >= value:
set_1.append(x)
else:
set_2.append(x)
return (set_1, set_2)
def leaf(dataSet):
'''计算叶节点的值
input: dataSet(list):训练样本
output: np.mean(data[:, -1])(float):均值
'''
data = np.mat(dataSet)
return np.mean(data[:, -1])
def err_cnt(dataSet):
'''回归树的划分指标
input: dataSet(list):训练数据
output: m*s^2(float):总方差
'''
data = np.mat(dataSet)
return np.var(data[:, -1]) * np.shape(data)[0]
def build_tree(data, min_sample, min_err):
'''构建树
input: data(list):训练样本
min_sample(int):叶子节点中最少的样本数
min_err(float):最小的error
output: node:树的根结点
'''
# 构建决策树,函数返回该决策树的根节点
if len(data) <= min_sample:
return node(results=leaf(data))
# 1、初始化
best_err = err_cnt(data)
bestCriteria = None # 存储最佳切分属性以及最佳切分点
bestSets = None # 存储切分后的两个数据集
# 2、开始构建CART回归树
feature_num = len(data[0]) - 1
for fea in range(0, feature_num):
feature_values = {}
for sample in data:
feature_values[sample[fea]] = 1
for value in feature_values.keys():
# 2.1、尝试划分
(set_1, set_2) = split_tree(data, fea, value)
if len(set_1) < 2 or len(set_2) < 2:
continue
# 2.2、计算划分后的error值
now_err = err_cnt(set_1) + err_cnt(set_2)
# 2.3、更新最优划分
if now_err < best_err and len(set_1) > 0 and len(set_2) > 0:
best_err = now_err
print("-----err : ",best_err)
bestCriteria = (fea, value)
bestSets = (set_1, set_2)
# 3、判断划分是否结束
# pdb.set_trace()
if best_err > min_err:
right = build_tree(bestSets[0], min_sample, min_err)
left = build_tree(bestSets[1], min_sample, min_err)
return node(fea=bestCriteria[0], value=bestCriteria[1], \
right=right, left=left)
else:
return node(results=leaf(data)) # 返回当前的类别标签作为最终的类别标签
def predict(sample, tree):
'''对每一个样本sample进行预测
input: sample(list):样本
tree:训练好的CART回归树模型
output: results(float):预测值
'''
# 1、只是树根
if tree.results != None:
return tree.results
else:
# 2、有左右子树
val_sample = sample[tree.fea] # fea处的值
branch = None
# 2.1、选择右子树
if val_sample >= tree.value:
branch = tree.right
# 2.2、选择左子树
else:
branch = tree.left
return predict(sample, branch)
def cal_error(data, tree):
''' 评估CART回归树模型
input: data(list):
tree:训练好的CART回归树模型
output: err/m(float):均方误差
'''
m = len(data) # 样本的个数
n = len(data[0]) - 1 # 样本中特征的个数
err = 0.0
for i in range(m):
tmp = []
for j in range(n):
tmp.append(data[i][j])
pre = predict(tmp, tree) # 对样本计算其预测值
# 计算残差
err += (data[i][-1] - pre) * (data[i][-1] - pre)
return err / m
def save_model(regression_tree, result_file):
'''将训练好的CART回归树模型保存到本地
input: regression_tree:回归树模型
result_file(string):文件名
'''
with open(result_file, 'wb') as f:
pickle.dump(regression_tree, f)
######################获取二叉树的深度 ####################
class Solution(object):
def isBalanced(self, root): #获取二叉树的深度
if root==None:
return 0
leftheight=self.isBalanced(root.left)
rightheight=self.isBalanced(root.right)
if leftheight>=rightheight:
return leftheight+1
else:
return rightheight+1
if __name__ == "__main__":
# 1、导入训练数据
print ("----------- 1、load data -------------")
data = load_data("sine.txt")
y = []
for i in range(len(data)):
y_tmp = data[i][1]
y.append(y_tmp)
ss = set(y)
print(len(ss))
# 2、构建CART树
print ("----------- 2、build CART ------------")
# pdb.set_trace()
regression_tree = build_tree(data, 20, 0.3)
# 3、评估CART树
print ("----------- 3、cal err -------------")
err = cal_error(data, regression_tree)
print ("\t--------- err : ", err)
# 4、保存最终的CART模型
print("----------4、save result -----------")
save_model(regression_tree, "regression_tree")
对训练好的CART回归树,画图代码如下:
# -*- coding: utf-8 -*-
"""
Created on Thu May 24 16:16:59 2018
@author: Administrator
"""
from graphviz import Digraph
import pickle as pickle
def load_model(tree_file):
'''导入训练好的CART回归树模型
input: tree_file(list):保存CART回归树模型的文件
output: regression_tree:CART回归树
'''
with open(tree_file, 'rb') as f:
regression_tree = pickle.load(f)
return regression_tree
class node:
'''树的节点的类
'''
def __init__(self, fea=-1, value=None, results=None, right=None, left=None):
self.fea = fea # 用于切分数据集的属性的列索引值
self.value = value # 设置划分的值
self.results = results # 存储叶节点的值
self.right = right # 右子树
self.left = left # 左子树
######################获取二叉树的深度 ####################
class Solution(object):
def isBalanced(self, root): #获取二叉树的深度
if root==None:
return 0
leftheight=self.isBalanced(root.left)
rightheight=self.isBalanced(root.right)
if leftheight>=rightheight:
return leftheight+1
else:
return rightheight+1
#####################遍历二叉树########################
class BTree(object):
def __init__(self,dot):
self.dot = dot
def preorder(self,pre_treenode ,treenode,orientation):
'前序(pre-order,NLR)遍历'
if treenode.results != None: #只有树根
a = str(pre_treenode.value)
self.dot.node(a, a)
result = str(treenode.results)
self.dot.node(result, result,shape = 'box',stytle = 'filled',color = ".7.3 1.0")
self.dot.edge(a, result)
return
else: #有左右子树
a = str(treenode.value)
self.dot.node(a, a)
if treenode.left.results == None:
left = str(treenode.left.value)
self.dot.node(left, left) #dot.node(节点名,节点标签(显示出来的))
self.dot.edge(a, left)
if treenode.right.results == None:
right = str(treenode.right.value)
self.dot.node(right, right)
self.dot.edge(a, right)
self.preorder(treenode,treenode.left,'left')
self.preorder(treenode,treenode.right,'right')
root = load_model("regression_tree")
dot = Digraph(comment='The Test Table')
bt = BTree(dot)
bt.preorder('',root,'root')
#print(dot.source)
dot.render('test-output/test-table.gv', view=True)
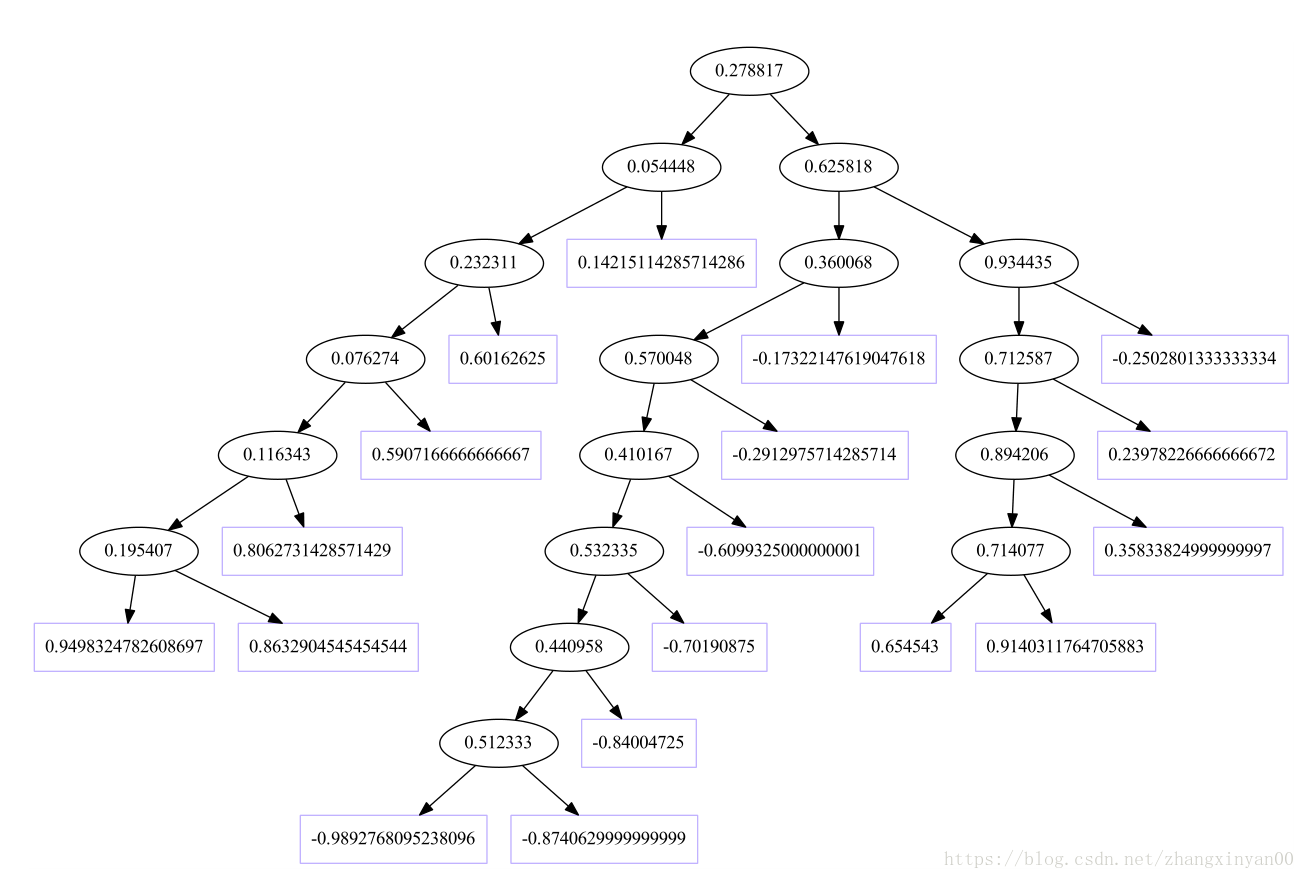
本数据训练的CART树如下图:椭圆形的框中的数据代表分界点,将数据分为左右两部分,矩形框代表叶子节点,也就是该节点所包含的数据的y的平均值,也即最后的回归值。














 9419
9419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









