







如果你现在还不努力,那么将来的你会过的更加吃力。
1 选择属性
属性选择是通过搜索数据中所有可能的属性组合,以找到预测效果最好的属性子集。手工选择属性既繁琐又容易出错,为了帮助用户事项选择属性自动化。Weka中提供了选择属性面板。要自动选择属性需要设立两个对象:属性评估器和搜索方法,如下图所示:
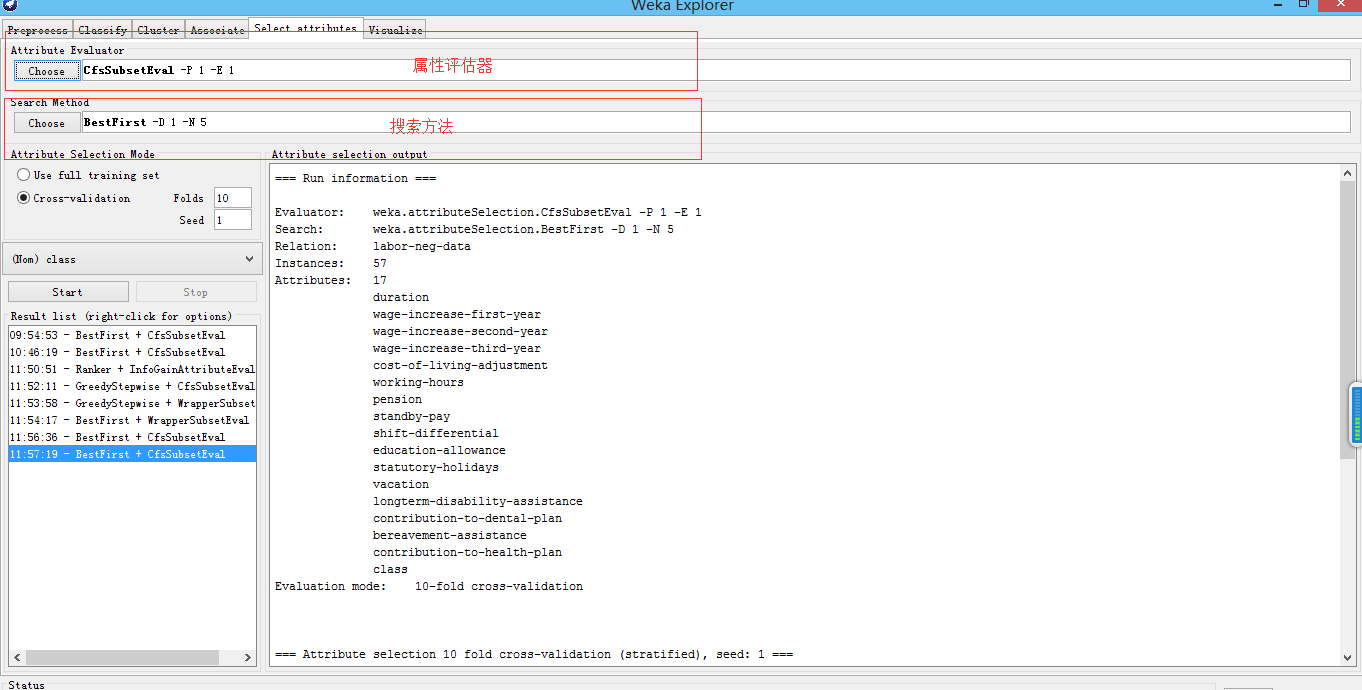
属性评估器确定使用什么方法给每个属性分配一个评估值,搜索方法决定执行什么风格的搜索。
2 选择属性算法的介绍
2-1 属性子集评估器
属性子集评估器选取属性的一个子集,并且返回一个指导搜索的度量数值。
CfsSubsetEval评估器评估每个属性的预测能力以及相互之间的冗余度,倾向于选择与类别属性相关度高,但是相互之间相关度第的属性。选项迭代添加与类别属性相关度最高的属性,只要是子集中不包含与当前属性相关更高的属性。 评估器将缺失值作为单独值,也可以将缺失值计数与其他的值一起按照出现频率分布。
WrapperSubsetEval评估器是包装器方法。它使用一个分类器来评估属性集,它对每个子集采用交叉验证估计学习方案的准确性。
2-2 单个属性评估器
单个属性评估器和Ranker搜索方法一起使用,Ranker产生一个丢弃若干属性后得到的给定数目的属性列表。
ReliefAttributeEval是基于实例的评估器,它随机抽取样本,并检查具有相同和不同类别的邻近实例。它可以运行在离散型和连续性的数据之上,参数包括指定抽样实例的数量,要检查的临近实例的数量,是否对近邻的距离加权,以及控制权重如何根据距离衰减的指数函数。
InfoGainAttributeEval评估器是通过测量类别对应属性的信息增益来评估属性,它首相基于MDL(最小描述长度)的离散化方法(也可以设置二元化处理)对数值属性惊醒离散化。
GainRatioAttributeEval评估器通过测量相应类别的增益率来评估属性。
其他的在使用的时候在研究………………
2-3 搜索方法
搜索方法遍历属性空间以搜索好的子集,通过所选的属性子集评估器来衡量其质量。
BestFirst搜索方法执行带回溯的贪婪爬山法,用户可以指定在系统的回溯钱,必须连续遇到多少个无法改善的结点。它可以从空属性集开始向前搜索,也可以从全集可是向后搜索,也可以从中间点开始双向搜索(增删单个属性)。为了提高效率可以缓存已经评估的子集。
GreedyStepwise搜索方法贪婪搜索属性的子集空间。不会进行回溯。
Ranker对单个属性进行排名的方案。
3 Weka选择属性实例分析
选择属性的一般目的是为了更好的实现分类功能,因为属性和最终需要分类的目标属性的关联度是不一样的。
使用劳工数据集labor.arff
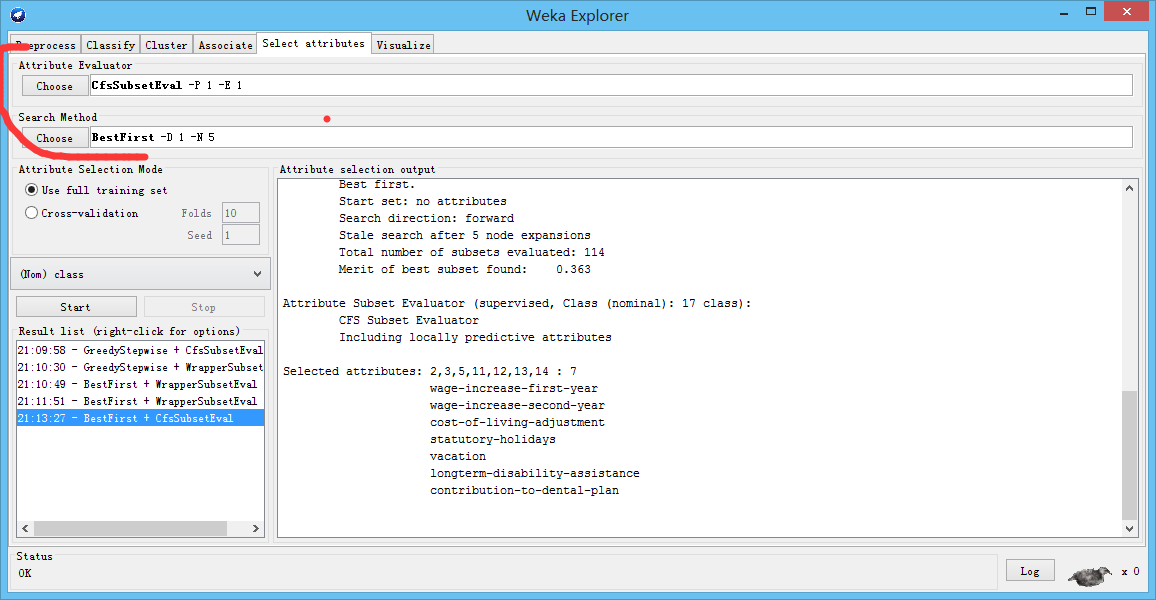
CfsSubsetEval
=== Run information ===
Evaluator: weka.attributeSelection.CfsSubsetEval -P 1 -E 1
Search: weka.attributeSelection.GreedyStepwise -T -1.7976931348623157E308 -N -1 -num-slots 1
Relation: labor-neg-data
Instances: 57
Attributes: 17
duration
wage-increase-first-year
wage-increase-second-year
wage-increase-third-year
cost-of-living-adjustment
working-hours
pension
standby-pay
shift-differential
education-allowance
statutory-holidays
vacation
longterm-disability-assistance
contribution-to-dental-plan
bereavement-assistance
contribution-to-health-plan
class
Evaluation mode: evaluate on all training data
=== Attribute Selection on all input data ===
Search Method:
Greedy Stepwise (forwards).
Start set: no attributes
Merit of best subset found: 0.363
Attribute Subset Evaluator (supervised, Class (nominal): 17 class):
CFS Subset Evaluator
Including locally predictive attributes
Selected attributes: 2,3,5,11,12,13,14 : 7
wage-increase-first-year
wage-increase-second-year
cost-of-living-adjustment
statutory-holidays
vacation
longterm-disability-assistance
contribution-to-dental-plan
WrapperSubsetEval评估器
=== Run information ===
Evaluator: weka.attributeSelection.WrapperSubsetEval -B weka.classifiers.trees.J48 -F 5 -T 0.01 -R 1 -E DEFAULT -- -C 0.25 -M 2
Search: weka.attributeSelection.BestFirst -D 1 -N 5
Relation: labor-neg-data
Instances: 57
Attributes: 17
duration
wage-increase-first-year
wage-increase-second-year
wage-increase-third-year
cost-of-living-adjustment
working-hours
pension
standby-pay
shift-differential
education-allowance
statutory-holidays
vacation
longterm-disability-assistance
contribution-to-dental-plan
bereavement-assistance
contribution-to-health-plan
class
Evaluation mode: evaluate on all training data
=== Attribute Selection on all input data ===
Search Method:
Best first.
Start set: no attributes
Search direction: forward
Stale search after 5 node expansions
Total number of subsets evaluated: 138
Merit of best subset found: 0.842
Attribute Subset Evaluator (supervised, Class (nominal): 17 class):
Wrapper Subset Evaluator
Learning scheme: weka.classifiers.trees.J48
Scheme options: -C 0.25 -M 2
Subset evaluation: classification accuracy
Number of folds for accuracy estimation: 5
Selected attributes: 1,2,4,6,11,12 : 6
duration
wage-increase-first-year
wage-increase-third-year
working-hours
statutory-holidays
vacation
研究对比:使用J48分类器,十折交叉验证来比较GfsSubsetEval评估器和WrapperSubsetEval评估器。
直接全集使用
=== Run information ===
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: labor-neg-data
Instances: 57
Attributes: 17
duration
wage-increase-first-year
wage-increase-second-year
wage-increase-third-year
cost-of-living-adjustment
working-hours
pension
standby-pay
shift-differential
education-allowance
statutory-holidays
vacation
longterm-disability-assistance
contribution-to-dental-plan
bereavement-assistance
contribution-to-health-plan
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
J48 pruned tree
------------------
wage-increase-first-year <= 2.5: bad (15.27/2.27)
wage-increase-first-year > 2.5
| statutory-holidays <= 10: bad (10.77/4.77)
| statutory-holidays > 10: good (30.96/1.0)
Number of Leaves : 3
Size of the tree : 5
Time taken to build model: 0.04 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 42 73.6842 %
Incorrectly Classified Instances 15 26.3158 %
Kappa statistic 0.4415
Mean absolute error 0.3192
Root mean squared error 0.4669
Relative absolute error 69.7715 %
Root relative squared error 97.7888 %
Coverage of cases (0.95 level) 91.2281 %
Mean rel. region size (0.95 level) 85.9649 %
Total Number of Instances 57
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0.700 0.243 0.609 0.700 0.651 0.444 0.695 0.559 bad
0.757 0.300 0.824 0.757 0.789 0.444 0.695 0.738 good
Weighted Avg. 0.737 0.280 0.748 0.737 0.740 0.444 0.695 0.675
=== Confusion Matrix ===
a b <-- classified as
14 6 | a = bad
9 28 | b = good
使用Cfs的结果,首先过滤属性
=== Run information ===
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: labor-neg-data-weka.filters.unsupervised.attribute.Remove-R1,4,6-10,15-16
Instances: 57
Attributes: 8
wage-increase-first-year
wage-increase-second-year
cost-of-living-adjustment
statutory-holidays
vacation
longterm-disability-assistance
contribution-to-dental-plan
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
J48 pruned tree
------------------
wage-increase-first-year <= 2.5: bad (15.27/2.27)
wage-increase-first-year > 2.5
| longterm-disability-assistance = yes
| | statutory-holidays <= 10
| | | wage-increase-first-year <= 3: bad (2.0)
| | | wage-increase-first-year > 3: good (3.99)
| | statutory-holidays > 10: good (25.67)
| longterm-disability-assistance = no
| | vacation = below_average: bad (5.09/1.09)
| | vacation = average: good (2.64/1.0)
| | vacation = generous: good (2.34)
Number of Leaves : 7
Size of the tree : 12
Time taken to build model: 0 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 44 77.193 %
Incorrectly Classified Instances 13 22.807 %
Kappa statistic 0.4935
Mean absolute error 0.2787
Root mean squared error 0.441
Relative absolute error 60.9191 %
Root relative squared error 92.3655 %
Coverage of cases (0.95 level) 89.4737 %
Mean rel. region size (0.95 level) 78.0702 %
Total Number of Instances 57
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0.650 0.162 0.684 0.650 0.667 0.494 0.737 0.586 bad
0.838 0.350 0.816 0.838 0.827 0.494 0.733 0.777 good
Weighted Avg. 0.772 0.284 0.770 0.772 0.771 0.494 0.735 0.710
=== Confusion Matrix ===
a b <-- classified as
13 7 | a = bad
6 31 | b = good
使用Wrap结果,首先过滤属性
=== Run information ===
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: labor-neg-data-weka.filters.unsupervised.attribute.Remove-R3,5,7-10,13-16
Instances: 57
Attributes: 7
duration
wage-increase-first-year
wage-increase-third-year
working-hours
statutory-holidays
vacation
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
J48 pruned tree
------------------
wage-increase-first-year <= 2.5: bad (15.27/2.27)
wage-increase-first-year > 2.5
| statutory-holidays <= 10
| | vacation = below_average: bad (7.54/1.54)
| | vacation = average: bad (0.0)
| | vacation = generous: good (3.23)
| statutory-holidays > 10: good (30.96/1.0)
Number of Leaves : 5
Size of the tree : 8
Time taken to build model: 0 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 46 80.7018 %
Incorrectly Classified Instances 11 19.2982 %
Kappa statistic 0.5905
Mean absolute error 0.2593
Root mean squared error 0.4162
Relative absolute error 56.6868 %
Root relative squared error 87.1592 %
Coverage of cases (0.95 level) 92.9825 %
Mean rel. region size (0.95 level) 78.9474 %
Total Number of Instances 57
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0.800 0.189 0.696 0.800 0.744 0.594 0.775 0.608 bad
0.811 0.200 0.882 0.811 0.845 0.594 0.775 0.808 good
Weighted Avg. 0.807 0.196 0.817 0.807 0.810 0.594 0.775 0.738
=== Confusion Matrix ===
a b <-- classified as
16 4 | a = bad
7 30 | b = good
总结:
第一:经过属性选择之后,分类的准确度得到提高;
第二:对于本例Wrap由于Cfs














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









