







转自:http://blog.csdn.net/zbc1090549839/article/details/51853944
虽然Hadoop经历了多年的发展,作为技术人员都或多或少的使用过或者了解过。这里还是做一个简单的总结,主要原因是之前主要是做hadoop的开发,对hadoop的运维知之甚少,但真正的接触到hadoop运维的工作的时候,其实会发现,对hadoop的一整套框架和理论知识都需要系统的学习,才能把工作做得更好,同时做基于hadoop的数据分析工作的时候,也时常会涉及到一些hadoop参数的调优。因此,在这里做一个简单的总结。由于是自己查阅资料并结合工作进行总结的,不免有疏漏或者错误之处,遇到了敬请一并指出。
一、hadoop是什么:
hadoop是Apache下使用JAVA开发的一个集分布式存储和分布式计算分析于一体的开源软件框架。其中最核心的设计是HDFS和MapReduce,HDFS对大数据存储提供支持,MapReduce则是分布式的计算框架。基于HDFS和MapReduce,hadoop还提供了类SQL分析查询工具HIVE和KV数据库Hbase,以及最近活跃的内存计算引擎Spark等等。
下面将简单介绍其中的几个组件运行机制及操作方法:HDFS、MapReduce、Hive
二、HDFS:
HDFS是为用户提供分布式的文件存储服务的软件框架,主要有以下几个方面的特点:
1、高容错性:由于HDFS的文件备份机制,一份文件会同时在HDFS集群中不同的机器甚至机架上备份多份文件,因此保证了文件不会因某一台机器出现故障而导致数据丢失的情况。
2、数据批处理:HDFS设计就是用来存储大数据文件的、一次写入、多次读取的应用场景而设计的。
3、使用BLOCK作为基本的存储单元:在HDFS中,使用block(文件块)作为基本数据存储单元,一个block空间为64M或者128M(可由用户自定义配置),一个文件会切分为多个block存储在HDFS中,方便了文件的管理和读取。
一个HDFS集群基本由3部分组成:client、namenode、datanode,表现为一个主从的结构,如下图所示:

namenode:HDFS master节点,负责维护整个HDFS的元数据信息,包括文件目录树和文件写记录信息,并且这些信息是维护在内存中。由于HDFS中的文件是以block单位组织的,一个文件的一个block的元数据大小约为130字节,一个文件大小小于block size的文件在HDFS中也会占据一个block(尽管在物理硬盘上实际没有占据这么大的空间),假设有1000万个文件,则会在namenode中消耗约2G的内存(由于文件有多份备份,实际消耗的可能更多)。
datanode:slave节点,负责保存文件的具体数据,并时刻向namenode汇报节点的状态和block信息。
client:向namenode发起文件读写请求,然后从datanode中读写数据。
可以看到,由于namenode是把数据直接放在内存中的,尽管也有checkpoint机制将文件元数据信息持久化到内存中,但单点问题还是导致整个集群的稳定性较差。
HDFS容错机制:
seconday namenode:
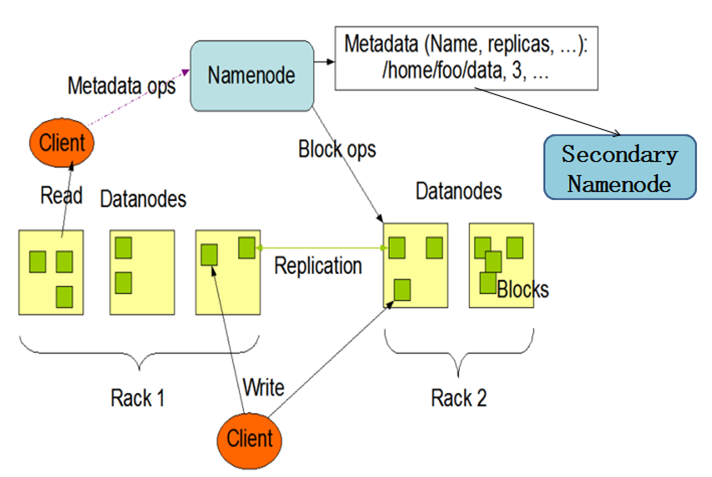
seconday namenode本身不对外提供服务,只是实时将namenode的信息同步过来,并完成写日志的合并操作,再将这些信息写入磁盘,因此在namenode挂了之后,可以通过seconday namenode的信息将元数据恢复过来。由于namenode和seconday namenode本身并不会持久化block的状态信息,因此恢复过程中,需要datanode将自己所维护的block状态信息发送给新的namenode,同时由于HDFS的元数据信息是从磁盘恢复到内存,因此恢复集群的服务需要一定的时间。
HDFS HA:
HDFS HA机制增加一个standby节点来提高HDFS的集群服务稳定性
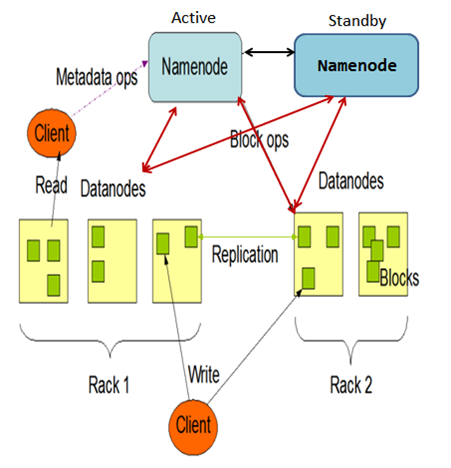
Active namenode节点对外提供服务,Standby namenode节点实时同步Active namenode节点的元数据信息和写日志到自己的内存中,并且Active namenode和Standby namenode都可以配置自己的seconday namenode。集群中的datanode节点不仅需要将自己的状态信息发送给Active namenode,也需要将这些信息发送给Standby namenode,因此保证了Active namenode和Standby namenode的数据一致性。当Active namenode节点挂掉之后,我们可以直接热切换到Standby namenode,因此对外界来讲,集群服务的故障时间是很短暂的,基本保证了整个HDFS集群的高可用性。
HDFS文件写入过程:
client端首先向namenode发起文件写请求,namenode根据集群的状态和datanode的空闲情况,确定待写入文件的datanode节点位置信息并将这些信息返回给client。client获得datanode节点位置信息后向datanode节点发起具体的文件写入请求,然后将文件逐步读入client的内存缓冲区,当client的内存缓冲区的大小达到一个block size大小时,把数据发送给datanode1,datanode1完成数据接收后 向另外一个datanode拷贝这份文件,形成备份文件,之后datanode1向namenode发送消息,报告文件的位置信息,最终结束写事件。
HDFS文件读过程:
client向namenode发起文件读请求,namenode判断请求的文件是否存在,如果不存在就直接返回,否则,namenode将返回该文件及其备份所在的datanode及具体的block信息。client拿到datanode和block信息信息后,向具体的datanode发起文件读请求并发送block信息,datanode拿到block信息后读取block对应的文件数据并将数据返回给client,如果整个数据读取结束,就完成了HDFS的读数据的过程。如果中途有datanode挂了的话,client则去读其文件副本所在的datanode的文件数据。














 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









