







携程实时用户行为服务作为基础服务,目前普遍应用在多个场景中,比如猜你喜欢(携程的推荐系统)、动态广告、用户画像、浏览历史等等。
以猜你喜欢为例,猜你喜欢为应用内用户提供潜在选项,提高成交效率。旅行是一项综合性的需求,用户往往需要不止一个产品。作为一站式的旅游服务平台,跨业务线的推荐,特别是实时推荐,能实际满足用户的需求,因此在上游提供打通各业务线之间的用户行为数据有很大的必要性。
携程原有的实时用户行为系统存在一些问题,包括:1)数据覆盖不全;2)数据输出没有统一格式,对众多使用方提高了接入成本;3)日志处理模块是web service,比较难支持多种数据处理策略和实现方便扩容应对流量洪峰的需求等。
而近几年旅游市场高速增长,数据量越来越大,并且会持续快速增长。有越来越多的使用需求,对系统的实时性,稳定性也提出了更高的要求。总的来说,当前需求对系统的实时性/可用性/性能/扩展性方面都有很高的要求。
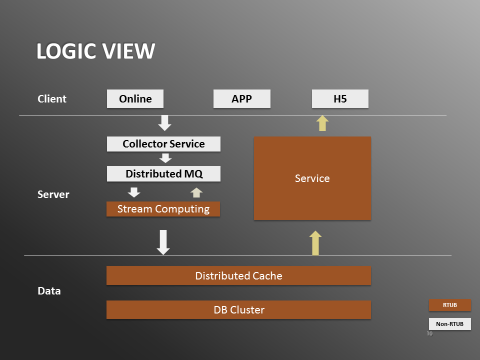
在处理流,行为日志会从客户端(App/Online/H5)上传到服务端的Collector Service。Collector Service将消息发送到分布式队列。数据处理模块由流计算框架完成,从分布式队列读出数据,处理之后把数据写入数据层,由分布式缓存和数据库集群组成。
输出流相对简单,Web Service的后台会从数据层拉取数据,并输出给调用方,有的是内部服务调用,比如推荐系统,也有的是输出到前台,比如浏览历史。系统实现采用的是Java+Kafka+Storm+Redis+MySQL+Tomcat+spring的技术栈。
1. Java:目前公司内部Java化的氛围比较浓厚,并且Java有比较成熟的大数据组件
1.突发流量洪峰,怎么应对;
2.出现失败数据或故障模块,如何保证失败数据重试并同时保证新数据的处理;
3.环境问题或bug导致数据积压,如何快速消解;
4.程序bug,旧数据需要重新处理,如何快速处理同时保证新数据;
首先是用storm解决了突发流量洪峰的问题。storm具有如下特性:

对当前系统来说,通过storm处理框架,消息能在进入kafka之后毫秒级别被处理。此外,storm具有强大的scale out能力。只要通过后台修改worker数量参数,并重启topology(storm的任务名称),可以马上扩展计算能力,方便应对突发的流量洪峰。
对消息的处理storm支持多种数据保证策略,at least once,at most once,exactly once。对实时用户行为来说,首先是保证数据尽可能少丢失,另外要支持包括重试和降级的多种数据处理策略,并不能发挥exactly once的优势,反而会因为事务支持降低性能,所以实时用户行为系统采用的at least once的策略。这种策略下消息可能会重发,所以程序处理实现了幂等支持。
storm的发布比较简单,上传更新程序jar包并重启任务即可完成一次发布,遗憾的是没有多版本灰度发布的支持。
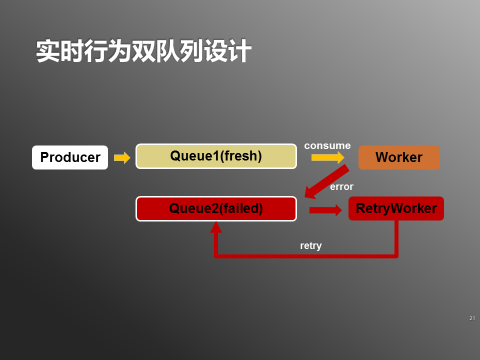
这样Worker对Queue1的消费进度不会被异常数据影响,可以保持消费新鲜数据。RetryWorker会监听Queue2,消费异常数据,如果处理还没有成功,则按照一定的策略(如下图)等待或者重新将异常数据写入Queue2。
1.系统是否有单点?
2.DB扩容/维护/故障怎么办?
3.Redis维护/升级补丁怎么办?
另外系统在部分模块不可用时通过降级处理保障整个系统的可用性。先看看正常数据处理流程:(如下图)
为了降低故障情况下对下游的影响,查询服务通过Netflix的Hystrix组件支持了熔断模式(如下图)。
开关打开之后会开始计时,timeout后会进入Half Open的状态,在该状态下会允许一个请求通过,进入业务处理模块,如果能正常返回则关闭开关,否则继续保持开关打开直到下次timeout。这样业务恢复之后就能正常服务请求。
另外,为了防止单个调用方的非法调用对服务的影响,服务也支持了多个维度限流,包括调用方AppId/ip限流和服务限流,接口限流等。
实时用户行为系统的数据层包括Redis和MySQL,Redis因为实现了一致性哈希,扩容时只要加机器,并对分配到新分区的数据作读补偿就可以。
MySQL方面,我们也做了水平切分作为扩展的准备,分片数量的选择考虑为2的n次方,这样做在扩容时有明显的好处。因为携程的mysql数据库现在普遍采用的是一主一备的方式,在扩容时可以直接把备机拉平成第二台(组)主机。假设原来分了2个库,d0和d1,都放在服务器s0上,s0同时有备机s1。扩容只需要如下几步:
1.确保s0 -> s1同步顺利,没有明显延迟
2.s0暂时关闭读写权限
3.确认s1已经完全同步s0更新
4.s1开放读写权限
5.d1的dns由s0切换到s1
整个过程比较简单方便,降低了运维负担,一定程度也能降低过多操作造成类似GitLab式悲剧的可能性。
以猜你喜欢为例,猜你喜欢为应用内用户提供潜在选项,提高成交效率。旅行是一项综合性的需求,用户往往需要不止一个产品。作为一站式的旅游服务平台,跨业务线的推荐,特别是实时推荐,能实际满足用户的需求,因此在上游提供打通各业务线之间的用户行为数据有很大的必要性。
携程原有的实时用户行为系统存在一些问题,包括:1)数据覆盖不全;2)数据输出没有统一格式,对众多使用方提高了接入成本;3)日志处理模块是web service,比较难支持多种数据处理策略和实现方便扩容应对流量洪峰的需求等。
而近几年旅游市场高速增长,数据量越来越大,并且会持续快速增长。有越来越多的使用需求,对系统的实时性,稳定性也提出了更高的要求。总的来说,当前需求对系统的实时性/可用性/性能/扩展性方面都有很高的要求。
一、架构
图1:实时用户行为系统逻辑视图
在处理流,行为日志会从客户端(App/Online/H5)上传到服务端的Collector Service。Collector Service将消息发送到分布式队列。数据处理模块由流计算框架完成,从分布式队列读出数据,处理之后把数据写入数据层,由分布式缓存和数据库集群组成。
输出流相对简单,Web Service的后台会从数据层拉取数据,并输出给调用方,有的是内部服务调用,比如推荐系统,也有的是输出到前台,比如浏览历史。系统实现采用的是Java+Kafka+Storm+Redis+MySQL+Tomcat+spring的技术栈。
1. Java:目前公司内部Java化的氛围比较浓厚,并且Java有比较成熟的大数据组件
2. Kafka/Storm:Kafka作为分布式消息队列已经在公司有比较成熟的应用,流计算框架Storm也已经落地,并且有比较好的运维支持环境。
4. MySQL: 作为基础系统,稳定性和性能也是系统的两大指标,对比NoSQL的主要选项,比如HBase和ElasticSearch,十亿数据级别上MySQL在这两方面有更好的表现,并且经过设计能够有不错的水平扩展能力。
二、实时性
1.突发流量洪峰,怎么应对;
2.出现失败数据或故障模块,如何保证失败数据重试并同时保证新数据的处理;
3.环境问题或bug导致数据积压,如何快速消解;
4.程序bug,旧数据需要重新处理,如何快速处理同时保证新数据;
系统从设计之初就考虑了上述情况。
首先是用storm解决了突发流量洪峰的问题。storm具有如下特性:
图2:Storm特性
对当前系统来说,通过storm处理框架,消息能在进入kafka之后毫秒级别被处理。此外,storm具有强大的scale out能力。只要通过后台修改worker数量参数,并重启topology(storm的任务名称),可以马上扩展计算能力,方便应对突发的流量洪峰。
对消息的处理storm支持多种数据保证策略,at least once,at most once,exactly once。对实时用户行为来说,首先是保证数据尽可能少丢失,另外要支持包括重试和降级的多种数据处理策略,并不能发挥exactly once的优势,反而会因为事务支持降低性能,所以实时用户行为系统采用的at least once的策略。这种策略下消息可能会重发,所以程序处理实现了幂等支持。
storm的发布比较简单,上传更新程序jar包并重启任务即可完成一次发布,遗憾的是没有多版本灰度发布的支持。
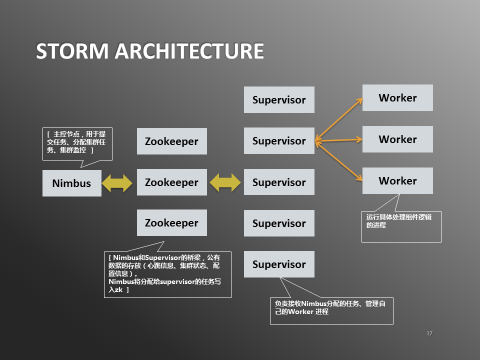
图3:Storm架构
图4:双队列设计
这样Worker对Queue1的消费进度不会被异常数据影响,可以保持消费新鲜数据。RetryWorker会监听Queue2,消费异常数据,如果处理还没有成功,则按照一定的策略(如下图)等待或者重新将异常数据写入Queue2。
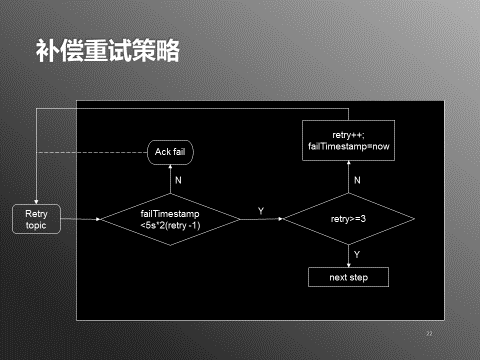
图5:补偿重试策略
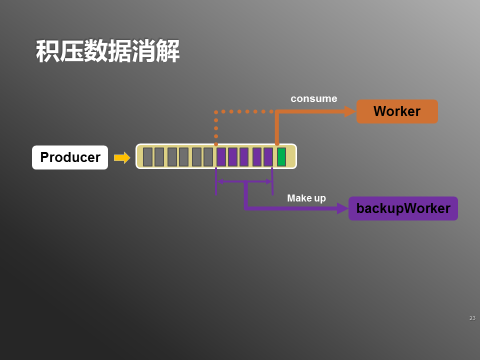
图6:积压数据消解
三、可用性
1.系统是否有单点?
2.DB扩容/维护/故障怎么办?
3.Redis维护/升级补丁怎么办?
4.服务万一挂了如何快速恢复?如何尽量不影响下游应用?
另外系统在部分模块不可用时通过降级处理保障整个系统的可用性。先看看正常数据处理流程:(如下图)
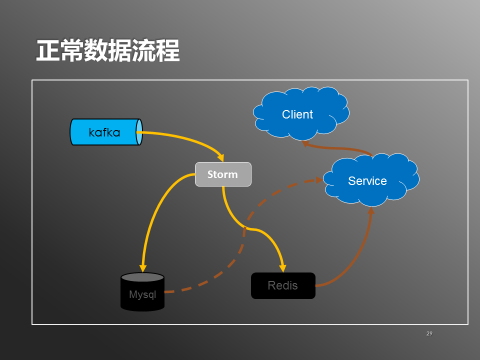
图7:正常数据流程
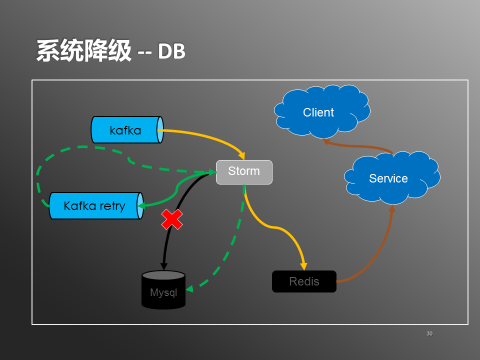
图8:系统降级-DB
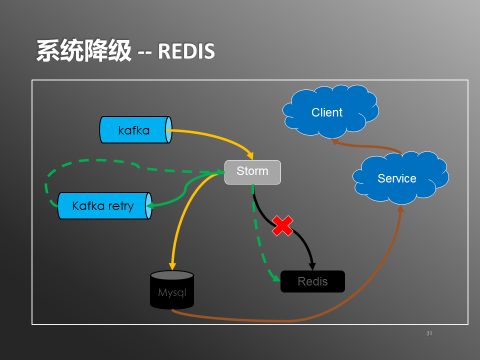
图9:系统降级-Redis
为了降低故障情况下对下游的影响,查询服务通过Netflix的Hystrix组件支持了熔断模式(如下图)。
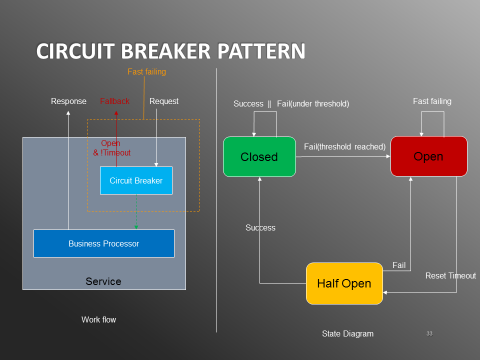
图10:Circuit Breaker Pattern
开关打开之后会开始计时,timeout后会进入Half Open的状态,在该状态下会允许一个请求通过,进入业务处理模块,如果能正常返回则关闭开关,否则继续保持开关打开直到下次timeout。这样业务恢复之后就能正常服务请求。
另外,为了防止单个调用方的非法调用对服务的影响,服务也支持了多个维度限流,包括调用方AppId/ip限流和服务限流,接口限流等。
四、性能&扩展
实时用户行为系统的数据层包括Redis和MySQL,Redis因为实现了一致性哈希,扩容时只要加机器,并对分配到新分区的数据作读补偿就可以。
MySQL方面,我们也做了水平切分作为扩展的准备,分片数量的选择考虑为2的n次方,这样做在扩容时有明显的好处。因为携程的mysql数据库现在普遍采用的是一主一备的方式,在扩容时可以直接把备机拉平成第二台(组)主机。假设原来分了2个库,d0和d1,都放在服务器s0上,s0同时有备机s1。扩容只需要如下几步:
1.确保s0 -> s1同步顺利,没有明显延迟
2.s0暂时关闭读写权限
3.确认s1已经完全同步s0更新
4.s1开放读写权限
5.d1的dns由s0切换到s1
6.s0开放读写权限
整个过程比较简单方便,降低了运维负担,一定程度也能降低过多操作造成类似GitLab式悲剧的可能性。
五、部署
另外有部分情况下程序可能需要多版本运行,比如行为纪录暂时有多个版本,这种情况下我们会新增一个backupJob,在backupJob中运行历史版本。














 2779
2779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









