









简单地说,网络通信时由于TCP会对传输的数据报进行对用户透明的拆分与重新组装,然后将拆分后的分别发送,而我们接收时要获取发送时的数据报,如何再对其拆分与组装,以便于我们能知道报文的意思,这个提取报文的过程就是TCP的拆包与粘包,在我们自己做底层的通信设计时,这是必须要考虑的。结合最近在做一个和通信相关的项目,本文讲几个经典且常用的几种粘包与拆包方法及其在Netty中的实现,Netty是高性能的通信框架,Netty和另一个通信框架Apache的MINA比较像,而且他们作者相同。关于Netty4与MINA2我做过一次比较总结,并将PPT上传在了网上,地址:https://download.csdn.net/download/zhaowen25/9128699
进入主题,Netty提供的拆包与粘包工具类:
1、 基于长度字段
io.netty.handler.codec.LengthFieldPrepender
类关系图如下:
原理和下面的io.netty.handler.codec.LengthFieldBasedFrameDecoder原理类似,不同是这个在编码的过程使用,
例如原报文数据如下:
+----------------------------+
| "HELLO, WORLD" |
+----------------------------+
长度占2个字节且不包含本身的拆包粘包结果如下:
+-----------+--------------------------+
| 0x000C | "HELLO, WORLD" |
+-----------+--------------------------+
长度占2个字节且包含本身的拆包粘包结果如下:
+------------+----------------------------+
| 0x000E | "HELLO, WORLD" |
+------------+----------------------------+
2、基于界定符解码器
io.netty.handler.codec.DelimiterBasedFrameDecoder
类关系图如下:
原理如下:
假设收到的报文如下:
+--------------------+
| ABC\nDEF\r\n |
+--------------------+
如果以‘\n’为界定符,则拆包粘包后的报文就是:
+--------+-------+
| ABC | DEF |
+--------+-------+
如果以‘\r\n’为界定符,则拆包粘包后的报文就是:
+-----------------+
| ABC\nDEF |
+-----------------+
3、基于定长解码器
io.netty.handler.codec.FixedLengthFrameDecoder
类关系图如下:
定长就是指定了报文的长度,解析时就是按长度组合截取,原理如下:
假设接收到的报文如下:
+----+-----+---------+----+
| A | BC | DEFG | HI |
+----+-----+---------+----+
当定长参数为3时,拆包与粘包的结果是:
+--------+-------+------+
| ABC | DEF | GHI |
+--------+-------+------+
4、基于长度字段解码器
io.netty.handler.codec.LengthFieldBasedFrameDecoder
类关系图如下:
所谓长字段就是在报文里有说明报文总长度的字段,其实在TCP的报文规则里就用的这个方法,在头部存放报文总长或除报头的内容总长,具体如下:
长度包含长度字段本身且不排除本身的拆包与粘包:
lengthFieldOffset = 0 长度字段偏移量
lengthFieldLength = 2 长度字段所占长度
lengthAdjustment = 0
initialBytesToStrip = 0 (要排除的用于初始化的偏移位置)
解码前 (14 bytes) 解码后 (14 bytes)
+------------+---------------------------+ +------------+---------------------------+
| Length | Actual Content | -----> | Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+------------+----------------------------+ +-----------+----------------------------+
长度包含长度字段本身且排除本身的拆包与粘包:
lengthFieldOffset = 0 长度字段偏移量
lengthFieldLength = 2 长度字段所占长度
lengthAdjustment = 0
initialBytesToStrip = 2 (排除头部)
解码前 (14 bytes) 解码后 (12 bytes)
+------------+----------------------------+ +---------------------------+
| Length | Actual Content | ----->| Actual Content |
| 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
+------------+----------------------------+ +----------------------------+
长度包含长度字段本身且不排除本身的拆包与粘包:
lengthFieldOffset = 0 长度字段偏移量
lengthFieldLength = 2 长度字段偏移量
lengthAdjustment = -2 调整长度 (长度字段所占长度)
initialBytesToStrip = 0
解码前 (14 bytes) 解码后 (14 bytes)
+------------+----------------------------+ +-----------+----------------------------+
| Length | Actual Content | -----> | Length | Actual Content |
| 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" |
+------------+----------------------------+ +-----------+----------------------------+
有外部头部的拆包与粘包:
lengthFieldOffset = 2 长度字段偏移量 ( = 外部头部Header 1的长度)
lengthFieldLength = 3 长度字段占用字节数
lengthAdjustment = 0
initialBytesToStrip = 0
解码前 (17 bytes) 解码后 (17 bytes)
+--------------+--------------+--------------------------+ +-------------+---------------+--------------------------+
| Header 1 | Length | Actual Content | -----> | Header 1 | Length | Actual Content |
| 0xCAFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
+--------------+--------------+--------------------------+ +--------------+--------------+--------------------------+
长度字段在前且有扩展头部的拆包与粘包:
lengthFieldOffset = 0 长度字段偏移量
lengthFieldLength = 3 长度字段占用字节数
lengthAdjustment = 2 ( Header 1 的长度)
initialBytesToStrip = 0
解码前 (17 bytes) 解码后 (17 bytes)
+----------------+---------------+---------------------------+ +---------------+----------------+---------------------------+
| Length | Header 1 | Actual Content | -----> | Length | Header 1 | Actual Content |
| 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
+----------------+---------------+---------------------------+ +---------------+----------------+---------------------------+
多扩展头部的拆包与粘包:
lengthFieldOffset = 1 长度字段偏移量(=头HDR1的长度)
lengthFieldLength = 2 长度字段占用字节数
lengthAdjustment = 1 调整长度(= 头HDR2的长度)
initialBytesToStrip = 3 排除的偏移量(= the length of HDR1 + LEN)
解码前 (16 bytes) 解码后 (13 bytes)
+----------+-----------+----------+----------------------------+ +----------+---------------------------+
| HDR1 | Length | HDR2 | Actual Content | -----> | HDR2 | Actual Content |
| 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+---------+------------+----------+---------------------------+ +----------+---------------------------+
调整的多扩展头部的拆包与粘包:
lengthFieldOffset = 1 长度字段偏移量(=头HDR1的长度)
lengthFieldLength = 2 长度字段占用字节数
lengthAdjustment = -3 (= the length of HDR1 + LEN, negative)
initialBytesToStrip = 3 排除的偏移量(= the length of HDR1 + LEN)
解码前 (16 bytes) 解码后 (13 bytes)
+---------+-----------+---------+--------------------------+ +---------+-------------------------+
| HDR1 | Length | HDR2 | Actual Content | -----> | HDR2 | Actual Content |
| 0xCA | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+---------+-----------+---------+--------------------------+ +---------+-------------------------+
5、基于换行符解码器
io.netty.handler.codec.LineBasedFrameDecoder
类关系图如下:
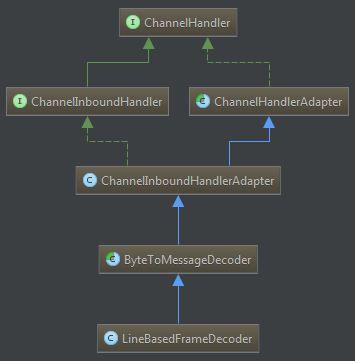
英文的解释是:A decoder that splits the received ByteBufs on line endings.
一行的结束标志包括: "\n" 和 "\r\n",所以又属于io.netty.handler.codec.FixedLengthFrameDecoder的范畴。
6、关于Netty中的ByteBuf
由于Netty底层是ByteBuf的结构特殊,具有双指针(读指针和写指针)如下:

所以相比MINA的ChannelBuffer的性能要高很多,这也是拆包与粘包的应用之处,就是如何将byte数组转换成我们想要的Messgae。
从类的关系图中我们可以看到Netty里两种数据流向,其实这是ChannelPipeline(管道)中的两种处理链,如图所示:
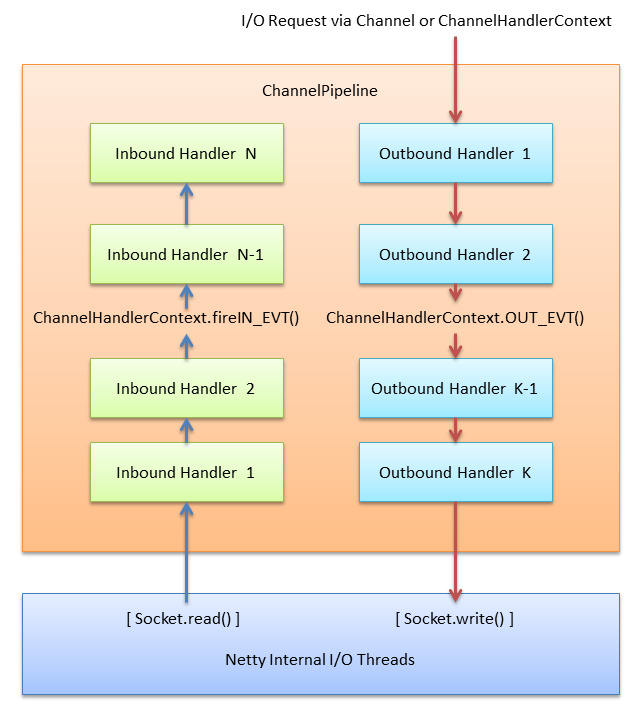
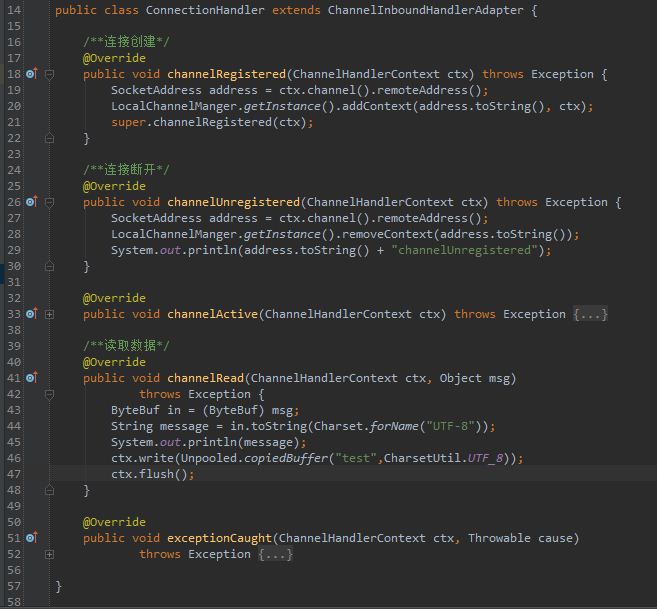
所以处理连接是继承类ChannelInboundHandlerAdapter,如下:
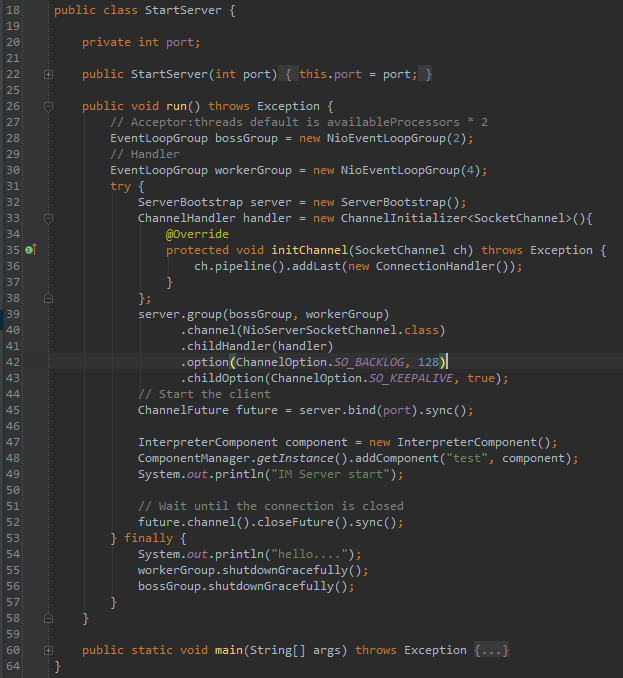
用Netty创建服务并且用能到这些拆包与粘的地方的代码如下(第36行处):
总结一下:和拆包与粘包相关的还有就是大小端,也就是高位与低位的位置问题,这些都与编解码相关,通信相关的问题也是这些问题,
今天基本上讲清楚了TCP拆包与粘包,其中引例来自Netty中的注释,我翻译了一下,可能有些地方翻译的不是很到位,感兴趣的可以直接看Netty4的源码。














 2921
2921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









