







常见聚类算法
1 聚类分析概述
聚类(Clustering)的本质是对数据进行分类,将相异的数据尽可能地分开,而将相似的数据聚成一个类别(簇),使得同一类别的数据具有尽可能高的同质性(homogeneity),类别之间有尽可能高的异质性(heterogeneity),从而方便从数据中发现隐含的有用信息。聚类算法的应用包含如下几方面:(1) 其他数据挖掘任务的关键中间环节:用于构建数据概要,用于分类、模式识别、假设生成和测试;用于异常检测,检测远离群簇的点。
(2) 数据摘要、数据压缩、数据降维:例如图像处理中的矢量量化技术。创建一个包含所有簇原型的表,即每个原型赋予一个整数值,作为它在表中的索引。每个对象用与它所在簇相关联的原型的索引表示。
(3) 协同过滤:用于推荐系统和用户细分。
(4) 动态趋势检测:对流数据进行聚类,检测动态趋势和模式。
(5) 用于多媒体数据、生物数据、社交网络数据的应用。
2 聚类算法的分类
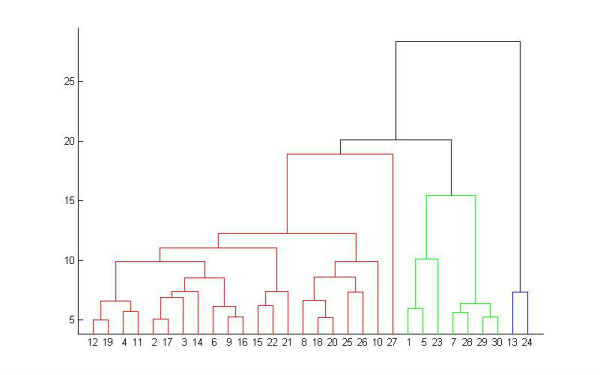
(1)基于分层的聚类(hierarchical methods):主要讲给定的数据集进行逐层分解,直到满足某种条件为止。具体可分为“自底向上”和“自顶向下”两种方案。在“自底向上”方案中,初始时每个数据点组成一个单独的组,在接下来的迭代中,按一定的距离度量将相互邻近的组合并成一个组,直至所有的记录组成一个分组或者满足某个条件为止。代表算法有:BIRCH,CURE,CHAMELEON等。自底向上的凝聚层次聚类如下图所示。
(2)基于划分的聚类(partitioning methods):给定包含个点的数据集,划分法将构造
个分组,每个分组代表一个聚类,这里每个分组至少包含一个数据点,每个数据点属于且仅属于一个分组。对于给定的
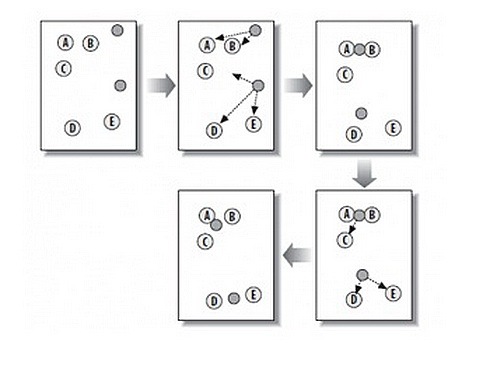
值,算法先给出一个初始的分组方法,然后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案较前一次好,这里好的标准在于同一组中的点越近越好,不同组中的点越远越好。代表算法有:K-means,K-medoids,CLARANS。K-means聚类过程图解如下:
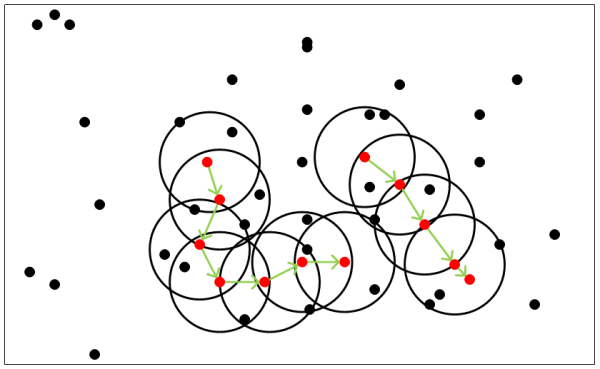
(3)基于密度的聚类(density-based methods):基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现“球形”聚簇的缺点。其核心思想在于只要一个区域中点的密度大于某个阈值,就把它加到与之相近的聚类中去。代表算法有:DBSCAN,OPTICS,DENCLUE,WaveCluster。DBSCAN的聚簇生成过程的简单理解如下图,后续会进行详述。
 (5)基于
模型的聚类(model-based methods):基于模型的方法给每一个聚类假定一个模型,然后去寻找能很好的拟合模型的数据集。模型可能是数据点在空间中的密度分布函数或者其它。这样的方法通常包含的潜在假设是:
数据集是由一系列的潜在概率分布生成的。通常有两种尝试思路:统计学方法和神经网络方法。其中,统计学方法有
COBWEB算法、
GMM(Gaussian Mixture Model),神经网络算法有
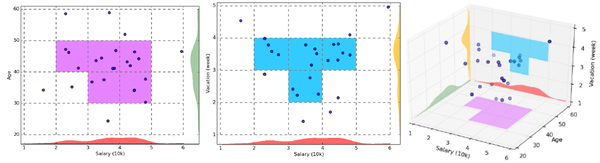
SOM(Self Organized Maps)算法。下图是GMM过程的一个简单直观地理解。
(5)基于
模型的聚类(model-based methods):基于模型的方法给每一个聚类假定一个模型,然后去寻找能很好的拟合模型的数据集。模型可能是数据点在空间中的密度分布函数或者其它。这样的方法通常包含的潜在假设是:
数据集是由一系列的潜在概率分布生成的。通常有两种尝试思路:统计学方法和神经网络方法。其中,统计学方法有
COBWEB算法、
GMM(Gaussian Mixture Model),神经网络算法有
SOM(Self Organized Maps)算法。下图是GMM过程的一个简单直观地理解。
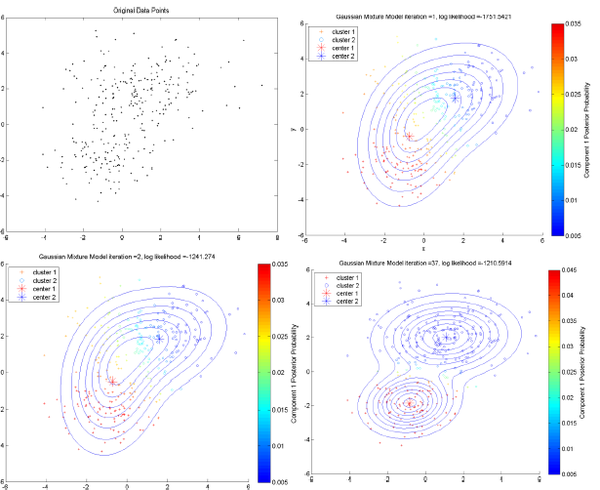
3 聚类分析的要求
不同的聚类算法有不同的应用背景,有的适合于大数据集,可以发现任意形状的聚簇;有的算法思想简单,适用于小数据集。总的来说,数据挖掘中针对聚类的典型要求包括:
(1) 可伸缩性:当数据量从几百上升到几百万时,聚类结果的准确度能一致。(2) 处理不同类型属性的能力:许多算法针对的数值类型的数据。但是,实际应用场景中,会遇到二元类型数据,分类/标称类型数据,序数型数据。
(3) 发现任意形状的类簇:许多聚类算法基于距离(欧式距离或曼哈顿距离)来量化对象之间的相似度。基于这种方式,我们往往只能发现相似尺寸和密度的球状类簇或者凸型类簇。但是,实际中类簇的形状可能是任意的。
(4) 初始化参数的需求最小化:很多算法需要用户提供一定个数的初始参数,比如期望的类簇个数,类簇初始中心点的设定。聚类的结果对这些参数十分敏感,调参数需要大量的人力负担,也非常影响聚类结果的准确性。
(5) 处理噪声数据的能力:噪声数据通常可以理解为影响聚类结果的干扰数据,包含孤立点,错误数据等,一些算法对这些噪声数据非常敏感,会导致低质量的聚类。
(6) 增量聚类和对输入次序的不敏感:一些算法不能将新加入的数据快速插入到已有的聚类结果中,还有一些算法针对不同次序的数据输入,产生的聚类结果差异很大。
(7) 高维性:有些算法只能处理2到3维的低纬度数据,而处理高维数据的能力很弱,高维空间中的数据分布十分稀疏,且高度倾斜。
(8) 可解释性和可用性:我们希望得到的聚类结果都能用特定的语义、知识进行解释,和实际的应用场景相联系。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









