第三章之字典的变种:
OrderedDict
首先来看下面的代码,在一个字典中,有name,age,city,在遍历这个字典的时候。顺序却是随机的,不是按照我们添加的顺序也就是name->age->city。
d={}
d['name']='zhf'
d['age']=33
d['city']='chengdu'
for k,v in d.items():
print k,v
city chengdu
age 33
name zhf
我们如果想字典按照我们添加的顺序呈现出来,就必须用到OrderedDict.
from collections import OrderedDict
d1=OrderedDict()
d1['name']='zhf'
d1['age']=33
d1['city']='chengdu'
for k,v in d1.items():
print k,v
结果如下,遍历的时候就和添加的顺序一致了。
E:\python2.7.11\python.exe E:/py_prj/fluent_python/chapter3.py
name zhf
age 33
city Chengdu
collections.Counter:
这个映射类型是给对象准备一个整数计数器。比如有字符:aaaabccc.那么Counter将会去计算每个字符出现的次数,并返回一个字典。
ct=Counter('aaaabccc')
print ct
E:\python2.7.11\python.exe E:/py_prj/fluent_python/chapter3.py
Counter({'a': 4, 'c': 3, 'b': 1})
可以看到返回的是一个字典,因此我们可以用字典的方式去获取到它对应的计数值。ct['a']。当去获取一个不存在的字母的时候,则会返回0.例如 ct['d']的返回结果就是0
当更新这个字符的时候,计数器会在上一次的基础上进行更新。
ct=Counter('aaaabccc')
ct.update('adef')
print ct
for c in ct.elements():
print c
E:\python2.7.11\python.exe E:/py_prj/fluent_python/chapter3.py
Counter({'a': 5, 'c': 3, 'b': 1, 'e': 1, 'd': 1, 'f': 1})
a
a
a
a
a
c
c
c
b
e
d
f
可以看到初始字符为aaaabccc, 更新添加adef后,a的次数变为5.整个字符串就变成aaaaacccbedf
集合:
集合的本质是许多唯一对象的聚集。因此集合可以去掉重复的元素。参考下面的代码
d=['abc','def','abc','def']
s=set(d)
print s
E:\python2.7.11\python.exe E:/py_prj/fluent_python/chapter3.py
set(['abc', 'def'])
假设有2个集合a和b,需要统计集合a的哪些元素在集合b中也出现。如果不使用集合,代码只能写成下面的形式:
a=['abc','def','aaa']
b=['abc','bbb','ccc','def']
for n in a:
if n in b:
print n
但是如果使用集合,则不用这么麻烦。在集合中。a|b返回的是合集,a&b返回的是交集。a-b返回的是差集。如下,用集合的话一行代码就搞定。
a=['abc','def','aaa']
b=['abc','bbb','ccc','def']
print set(a) & set(b)
E:\python2.7.11\python.exe E:/py_prj/fluent_python/chapter3.py
set(['abc', 'def'])
合集的结果
print set(a) | set(b)
E:\python2.7.11\python.exe E:/py_prj/fluent_python/chapter3.py
set(['abc', 'aaa', 'ccc', 'bbb', 'def'])
差集的结果,差集是指属于A但不属于B的结合
print set(a)-set(b)
set(['aaa'])
对称差集:集合A与集合B中所有不属于A∩B的元素集合
print set(a)^set(b)
set(['ccc', 'aaa', 'bbb'])
关于字典,列表,集合运行效率的对比.
1 首先我们用haystack建立一个字典,里面的元素大小分别从1000增长到10000000.然后看下运行时间
start=time.clock()
for n in needles:
if n in haystack:
found+=1
end=time.clock()
print end-start
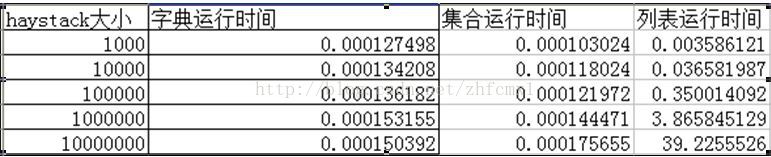
可以看出时间差别如此的大,对于列表而言,haystack的大小没增长10倍,运行时间呈线性增长。
为什么会导致如此大的区别呢,原因在于字典以及集合都用到了散列表,而列表没有用散列表,因此每次搜索列表都需要扫描一次完整的表。这里介绍下什么是散列表
散列表又叫hash表,是根据关键码的值而直接进行访问的数据结构。通过把关键码映射到表中的一个位置来访问表,以便加快访问速度。这个映射函数就叫散列函数。通俗点说就是对于存储在字典或者集合中的每一个组,都会计算一个hash值。这个hash值可以当做在字典和集合中存储的位置。然后查找的时候只需要计算这个hash值就可以找到存储的位置,这样就避免了遍历整个表。
字典的代码:
found=0
haystack={}
needles=[float(random.randint(0,500)) for i in range(500)]
length=10000000
for i,v in enumerate(range(length)):
haystack[i]=(float(random.randint(0,length)))
start=time.clock()
for n in needles:
if n in haystack:
found+=1
end=time.clock()
print end-start
集合的代码:
found=0
haystack=set()
needles=[float(random.randint(0,500)) for i in range(500)]
length=1000
for i in range(length):
haystack.add(float(random.randint(0,length)))
start=time.clock()
for n in needles:
if n in haystack:
found+=1
end=time.clock()
print end-start
列表的代码
found=0
haystack=[]
needles=[float(random.randint(0,500)) for i in range(500)]
length=10000
for i in range(length):
haystack.append(float(random.randint(0,length)))
start=time.clock()
for n in needles:
if n in haystack:
found+=1
end=time.clock()
print end-start
既然字典和集合会保存一个hash表,那么肯定会比列表占据更多的内存。我们来实际看下是不是这样的。我们还是用profile来看下内存的增长
来看字典的
@profile
def memory_try():
haystack={}
length=10000000
for i,v in enumerate(range(length)):
haystack[i]=(float(random.randint(0,length)))
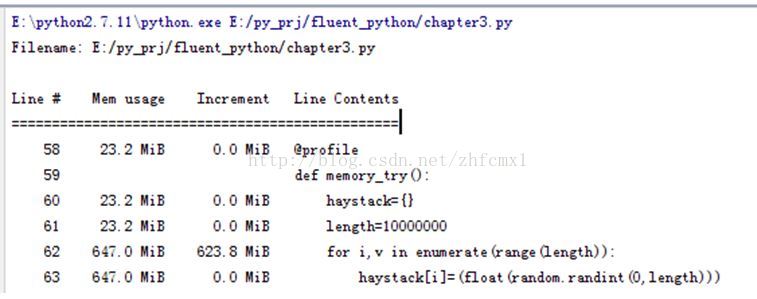
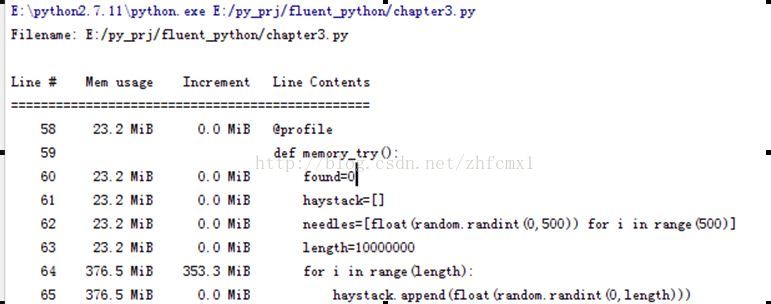
因此可以看出字典的高效率是用空间换时间得来的
























 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











