






 本文详细介绍如何使用Docker快速构建Hadoop开发测试环境,包括Hadoop、Hive、HBase和Spark等组件的集成。通过创建独立网络,实现多节点间的高效通信,简化Hadoop集群搭建流程。
本文详细介绍如何使用Docker快速构建Hadoop开发测试环境,包括Hadoop、Hive、HBase和Spark等组件的集成。通过创建独立网络,实现多节点间的高效通信,简化Hadoop集群搭建流程。
转载:https://kiwenlau.com/2016/06/12/160612-hadoop-cluster-docker-update/
注注注注注注 下面的比较全
基于Docker构建的Hadoop开发测试环境,包含Hadoop,Hive,HBase,Spark
https://github.com/ruoyu-chen/hadoop-docker/tree/master摘要: kiwenlau/hadoop-cluster-docker是去年参加Docker巨好玩比赛开发的,得了二等奖并赢了一块苹果手表,目前这个项目已经在GitHub上获得了236个Star,DockerHub的镜像下载次数2000+。总之,项目还算很受欢迎吧,这篇博客将介绍项目的升级版。
- 作者: KiwenLau
- 日期: 2016-06-12
一. 项目介绍
将Hadoop打包到Docker镜像中,就可以快速地在单个机器上搭建Hadoop集群,这样可以方便新手测试和学习。
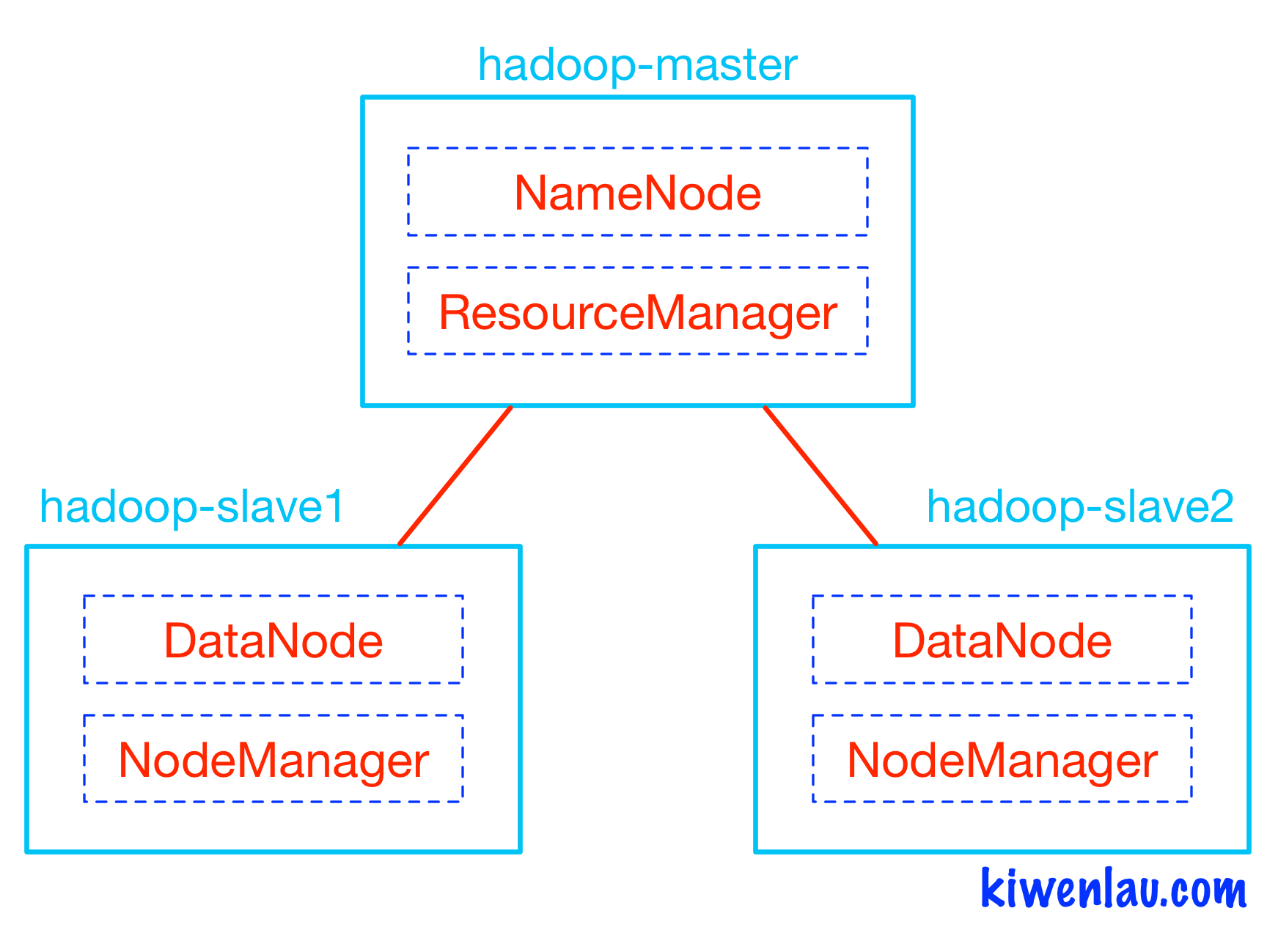
如下图所示,Hadoop的master和slave分别运行在不同的Docker容器中,其中hadoop-master容器中运行NameNode和ResourceManager,hadoop-slave容器中运行DataNode和NodeManager。NameNode和DataNode是Hadoop分布式文件系统HDFS的组件,负责储存输入以及输出数据,而ResourceManager和NodeManager是Hadoop集群资源管理系统YARN的组件,负责CPU和内存资源的调度。
之前的版本使用serf/dnsmasq为Hadoop集群提供DNS服务,由于Docker网络功能更新,现在并不需要了。更新的版本中,使用以下命令为Hadoop集群创建单独的网络:
sudo docker network create --driver=bridge hadoop
然后在运行Hadoop容器时,使用”–net=hadoop”选项,这时所有容器将运行在hadoop网络中,它们可以通过容器名称进行通信。
项目更新要点:
- 去除serf/dnsmasq
- 合并Master和Slave镜像
- 使用kiwenlau/compile-hadoop项目编译的Hadoo进行安装
- 优化Hadoop配置
二. 3节点Hadoop集群搭建步骤
1. 下载Docker镜像
sudo docker pull kiwenlau/hadoop:1.02. 下载GitHub仓库
git clone https://github.com/kiwenlau/hadoop-cluster-docker3. 创建Hadoop网络
sudo docker network create --driver=bridge hadoop4. 运行Docker容器
cd hadoop-cluster-docker
./start-container.sh运行结果
start hadoop-master container...
start hadoop-slave1 container...
start hadoop-slave2 container...
root@hadoop-master:~#- 启动了3个容器,1个master, 2个slave
- 运行后就进入了hadoop-master容器的/root目录
5. 启动hadoop
- 直接运行 不要sudo
./start-hadoop.sh
- 执行结果
Starting namenodes on [hadoop-master]
hadoop-master: Warning: Permanently added 'hadoop-master,172.18.0.2' (ECDSA) to the list of known hosts.
hadoop-master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-hadoop-master.out
hadoop-slave2: Warning: Permanently added 'hadoop-slave2,172.18.0.4' (ECDSA) to the list of known hosts.
hadoop-slave1: Warning: Permanently added 'hadoop-slave1,172.18.0.3' (ECDSA) to the list of known hosts.
hadoop-slave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hadoop-slave2.out
hadoop-slave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hadoop-slave1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-hadoop-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn--resourcemanager-hadoop-master.out
hadoop-slave1: Warning: Permanently added 'hadoop-slave1,172.18.0.3' (ECDSA) to the list of known hosts.
hadoop-slave2: Warning: Permanently added 'hadoop-slave2,172.18.0.4' (ECDSA) to the list of known hosts.
hadoop-slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-hadoop-slave1.out
hadoop-slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-hadoop-slave2.out
6. 运行wordcount
./run-wordcount.sh运行结果
mkdir: cannot create directory 'input': File exists
20/08/12 08:38:30 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.18.0.2:8032
20/08/12 08:38:30 INFO input.FileInputFormat: Total input paths to process : 2
20/08/12 08:38:30 INFO mapreduce.JobSubmitter: number of splits:2
20/08/12 08:38:30 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1597220981365_0001
20/08/12 08:38:31 INFO impl.YarnClientImpl: Submitted application application_1597220981365_0001
20/08/12 08:38:31 INFO mapreduce.Job: The url to track the job: http://hadoop-master:8088/proxy/application_1597220981365_0001/
20/08/12 08:38:31 INFO mapreduce.Job: Running job: job_1597220981365_0001
20/08/12 08:38:39 INFO mapreduce.Job: Job job_1597220981365_0001 running in uber mode : false
20/08/12 08:38:39 INFO mapreduce.Job: map 0% reduce 0%
20/08/12 08:38:45 INFO mapreduce.Job: map 100% reduce 0%
20/08/12 08:38:50 INFO mapreduce.Job: map 100% reduce 100%
20/08/12 08:38:51 INFO mapreduce.Job: Job job_1597220981365_0001 completed successfully
20/08/12 08:38:51 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=56
FILE: Number of bytes written=352398
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=258
HDFS: Number of bytes written=26
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=7567
Total time spent by all reduces in occupied slots (ms)=2727
Total time spent by all map tasks (ms)=7567
Total time spent by all reduce tasks (ms)=2727
Total vcore-milliseconds taken by all map tasks=7567
Total vcore-milliseconds taken by all reduce tasks=2727
Total megabyte-milliseconds taken by all map tasks=7748608
Total megabyte-milliseconds taken by all reduce tasks=2792448
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=42
Map output materialized bytes=62
Input split bytes=232
Combine input records=4
Combine output records=4
Reduce input groups=3
Reduce shuffle bytes=62
Reduce input records=4
Reduce output records=3
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=76
CPU time spent (ms)=1380
Physical memory (bytes) snapshot=832122880
Virtual memory (bytes) snapshot=2679701504
Total committed heap usage (bytes)=603979776
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=26
File Output Format Counters
Bytes Written=26
input file1.txt:
Hello Hadoop
input file2.txt:
Hello Docker
wordcount output:
Docker 1
Hadoop 1
Hello 2
- NameNode: http://192.168.59.1:50070/Hadoop网页管理地址:
- ResourceManager: http://192.168.59.1:8088/
192.168.59.1为运行容器的主机的IP。
三. N节点Hadoop集群搭建步骤
1. 准备
- 参考第二部分1~3:下载Docker镜像,下载GitHub仓库,以及创建Hadoop网络
2. 重新构建Docker镜像
|
- 可以指定任意N(N>1)
3. 启动Docker容器
|
- 与第2步中的N保持一致。
4. 运行Hadoop
- 参考第二部分5~6:启动Hadoop,并运行wordcount。
参考

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









