







题目来源
题目描述

题目解析
理解题意是关键
输入: nums1 = [4,1,2], nums2 = [1,3,4,2].
输出: [-1,3,-1]
解释:
* 对于num1中的数字4,在nums2中找到了一个4,此时nums2中4右边的数是2,比4小,因此-1
对于num1中的数字1,在nums2中找到了一个1,第二个数组中数字1右边的数有3,4,2,因此输出3。
对于num1中的数字2,在nums2中找到了一个1,第二个数组中数字1右边的数没有数,因此输出 -1。
暴力模拟
思路
根据题意,我们发现 n u m s 1 nums_1 nums1是一个查询数组,逐个查询 n u m s 2 nums_2 nums2中元素右边的第一个更大的值,因此,我们可以暴力的逐个计算 n u m s 1 nums_1 nums1中的每个元素值 n u m s 1 [ i ] nums_1[i] nums1[i]在 n u m s 2 nums_2 nums2中对应位置的右边的第一个比 n u m s 1 [ i ] nums_1[i] nums1[i]大的元素值。具体的,我们使用如下方法:
- 初始化与 n u m s 1 nums_1 nums1等长的查询数组 r e s res res
- 遍历
n
u
m
s
1
nums_1
nums1中的所有元素,不妨设当前遍历到元素为
n
u
m
s
1
[
i
]
nums_1[i]
nums1[i]
- 从前向后遍历 n u m s 2 nums_2 nums2中的元素,直到找到 n u m s 2 [ j ] = n u m s 1 [ i ] nums_2[j] = nums_1[i] nums2[j]=nums1[i]
- 从 j + 1 j+1 j+1开始继续向后遍历,直到找到 n u m s 2 [ k ] > n u m s 2 [ j ] nums_2[k]>nums_2[j] nums2[k]>nums2[j],其中 k > = j + 1 k>=j+1 k>=j+1
- 如果找到了 n u m s 2 [ k ] nums_2[k] nums2[k],则将 r e s [ i ] res[i] res[i]设置为 n u m s 2 [ k ] nums_2[k] nums2[k],否则将 r e s [ i ] res[i] res[i]设置为-1
- 查询数组 r e s res res 即为最终结果
实现
class Solution {
public int[] nextGreaterElement(int []findNums, int[] allNums){
int m = findNums.length, n = allNums.length;
int []res = new int[m];
for (int i = 0; i < m; i++) {
int bk = findNums[i]; // 待查询的元素
int j = 0; // 每次查询都从allNums中第0个开始查找
while (j < n && allNums[j] != bk){ // 去allNums中寻找到bk的位置索引
++j;
}
int k = j + 1;
while (k < n && allNums[k] < bk){ // 去allNums中剩下的空间中查找比bk大的元素的索引
++k;
}
res[i] = k < n ? allNums[k] : -1; // allNums中是否存在比n大的元素
}
return res;
}
}
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
int m = nums1.size(), n = nums2.size();
std::vector<int> res(m);
for (int i = 0; i < m; ++i) {
int bk = nums1[i];
int j = 0;
while (j < n && nums2[j] != bk){
++j;
}
int k = j + 1;
while (k < n && nums2[k] < bk){
++k;
}
res[i] = k < n ? nums2[k] : -1;
}
return res;
}
};

- 时间复杂度:O(n * m)
- 空间复杂度:O(1),返回值不算额外空间。
哈希表
上面方法中对于每一个findNums中的元素我们都要在allNums中从头开始遍历,这个效率是非常低的。那我们有没有什么办法可以降低遍历的次数呢?
我们可以先用哈希表记录findNums中的所有元素以及其位置,直接遍历allNums,然后看allNums,然后看allNums中的每一个元素是否在哈希表中,在的话,我们才往右寻找比他大的数,这样可以极大的减少遍历的次数
public int[] nextGreaterElement(int []findNums, int[] allNums){
int []res = new int[findNums.length];
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < findNums.length; i++) {
map.put(findNums[i], i);
}
for (int i = 0; i < allNums.length; i++) {
if(map.containsKey(allNums[i])){
// 对于在nums1中的元素,才向右查找。
int j = i + 1;
while (j < allNums.length && allNums[j] < allNums[i]){
j++;
}
res[map.get(allNums[i])] = (j > allNums.length ? -1 : allNums[j]);
}
}
return res;
}
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
int m = nums1.size(), n = nums2.size(), curr;
std::map<int, int> mapper;
for (int i = 0; i < n; ++i) {
mapper[nums2[i]] = i;
}
std::vector<int> res(m);
for (int i = 0; i < m; ++i) {
curr = nums1[i];
if(mapper.count(curr)){
int j = mapper[curr] + 1;
while (j < n && nums2[j] < curr){
++j;
}
res[i] = j < n ? nums2[j] : -1;
}
}
return res;
}
};

- 时间复杂度:O(n + m * m) 【n为findNums的长度,m为allNums的长度】,理论上来讲是这个复杂度,但是,我们有 if 判断在 map 中的才往右遍历,而且不是从头遍历,所以,整体的时间复杂度是远远小于
O(n + m * m)的。 - 空间复杂度:O(n),哈希表占用额外空间
单调栈 + 哈希表
方法二中对于每一个在 nums1 中的元素,我们还是需要往右遍历 nums2 才能找到第一个比它大的数,这个效率也是有点低下的,有没有方法改进呢?
思路
我们可以预处理allNums,使查询findNums中的每个元素在allNums中对应元素的右边的第一个更大的元素值时不需要再遍历allNums。于是,我们将题目分解为两个子问题:
- 第一个子问题:如何更高效的计算allNums中每个元素右边的第一个更大的值
- 第二个子问题:如何存储第一个子问题的结果
算法
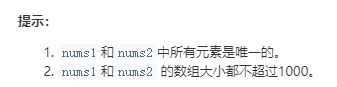
我们可以使用单调栈来解决第一个子问题。
- 先遍历大数组allNums,首先将第一个元素入栈
- 继续遍历,当当前元素小于栈顶元素时,继续将它入栈;当当前元素大于栈顶元素时,栈顶元素出栈
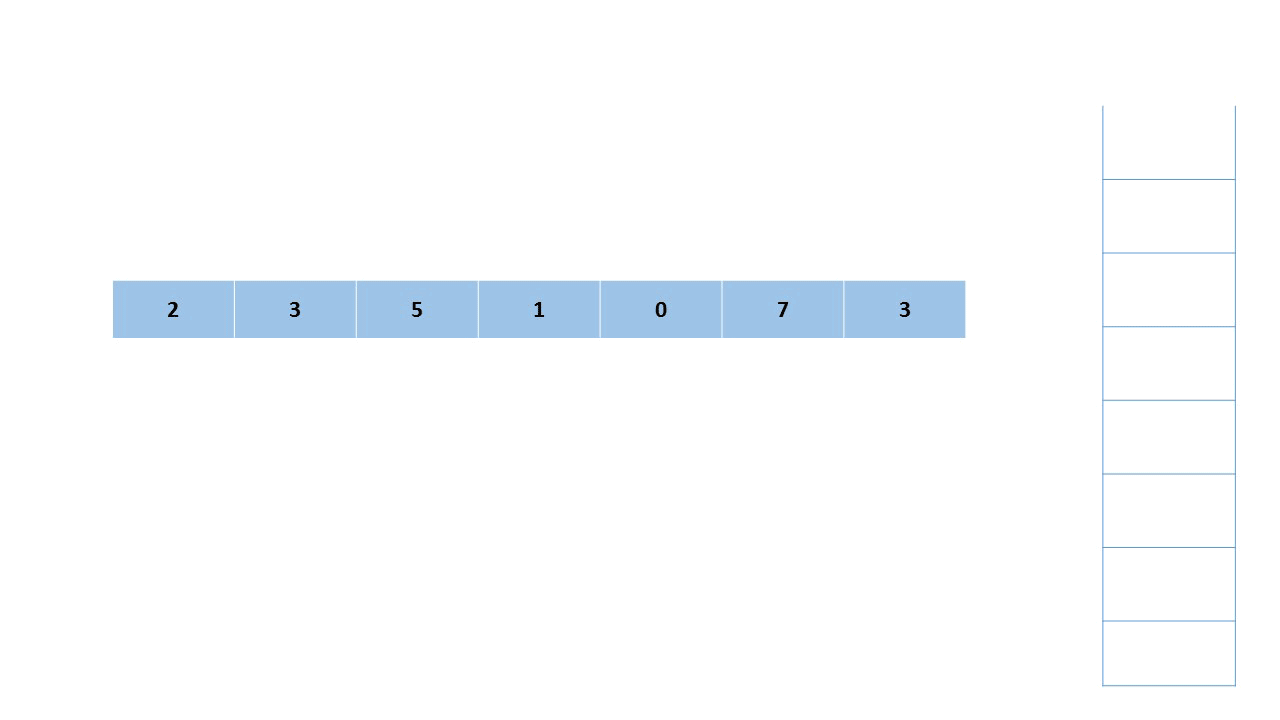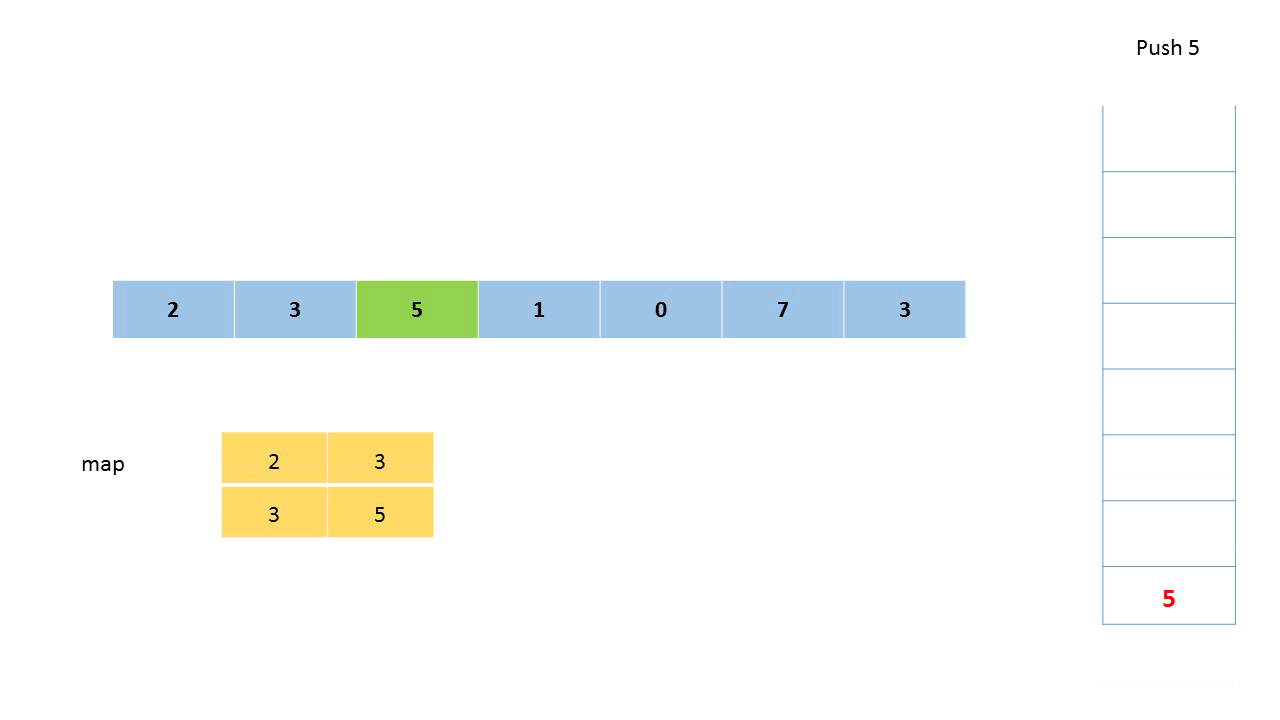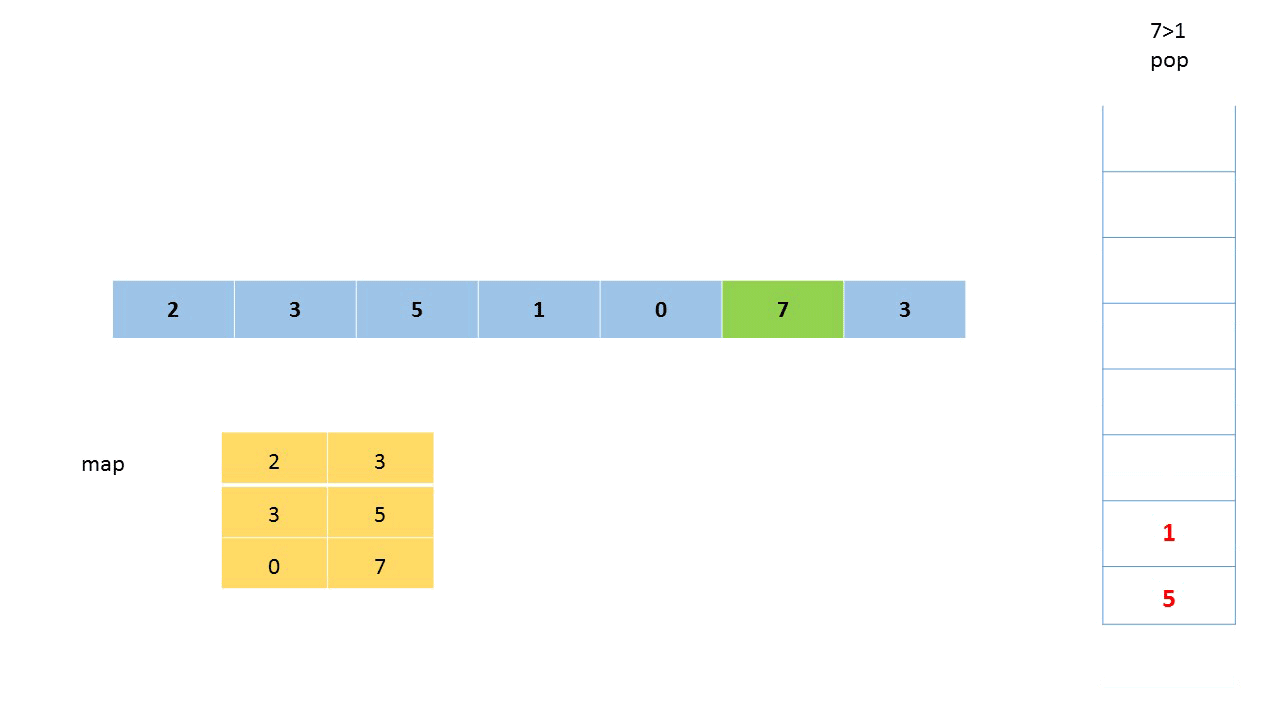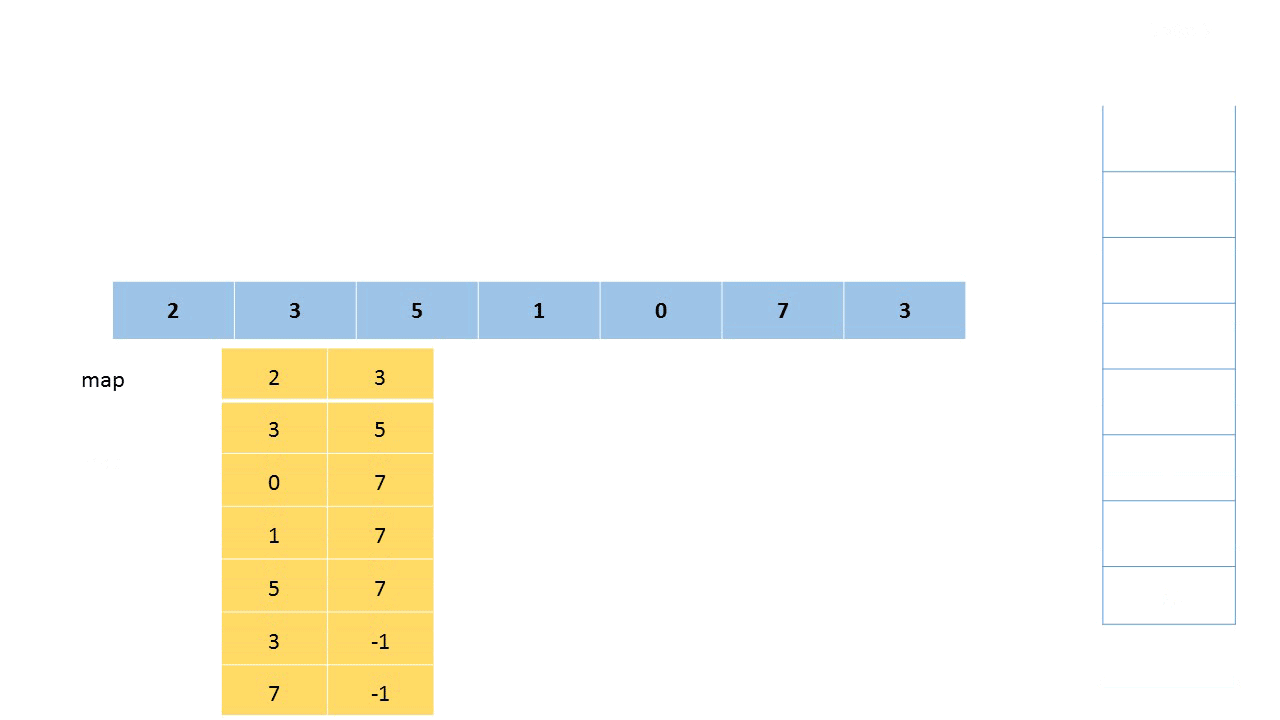
实现
class Solution {
public int[] nextGreaterElement(int[] findNums, int[] nums) {
if (findNums == null || nums == null || findNums.length == 0 || nums.length == 0){
return new int[]{};
}
int[] res = new int[findNums.length];
Stack<Integer> stack = new Stack<>();
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++){
while (!stack.empty() && nums[i] > stack.peek()){
map.put(stack.pop(), nums[i]);
}
stack.push(nums[i]);
}
for (int i = 0; i < findNums.length; i++){
res[i] = map.getOrDefault(findNums[i], -1);
}
return res;
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









