







tcpdump
是什么
- 通俗的说,tcpdump是一个抓包工具,用于抓取互联网上传输的数据包。
- 形象的说,tcpdump就好比是国家海关,驻扎在出入境的咽喉要道,凡是要入境和出境的集装箱,海关人员总要打开箱子,看看里面都装了点啥。
- 学术的说,tcpdump是一种嗅探器(sniffer),利用以太网的特性,通过将网卡适配器(NIC)置于混杂模式(promiscuous)来获取传输在网络中的信息包。
tcpdump 可以工作在各种 Unix类的操作系统上,包括 Linux、FreeBSD、macOS、Solaris 等,也是目前使用最为广泛的
抓包工具之一。
要用tcpdump抓包,请记住,一定要切换到root账户下,因为只有root才有权限将网卡变更为“混杂模式”
所谓混杂模式,也就是嗅探(Sniffering),就是把目的地址不是本机地址的网络报文也抓取下来
BPF
tcpdump过滤报文的功能是使用BPF实现的。
- BPF 全称是 Berkeley Packet Filter(也叫 BSD Packet Filter),它是tcpdump等抓包工具的底层基础。
- 在BPF出现之前,虽然各家操作系统都有自己的抓包工具,但是带有各种不足。比如,有些系统把所有网络报文一股脑儿塞给用户空间程序,开销非常大;而有些系统虽然有报文过滤功能,但是工作很不稳定。
- 为解决这些问题,当初 tcpdump 的两个作者发表了关于BPF的论文,它以一种新的基于寄存器的虚拟机方式,实现了高效稳定的报文过滤功能。
- 从此以后,抓包技术这棵大树有了一个甚为强大的根基,而构建在 BPF 之上的libpcap、tcpdump 等不断枝繁叶茂,进一步使得抓包工作变得方便、稳定
libpcap
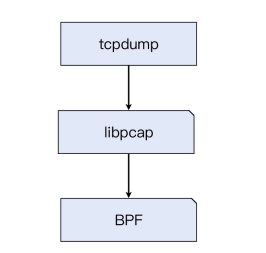
BPF实现了抓包虚拟机,但是它是如何被用户空间程序使用的呢?于是,libpcap出现了,它提供了API给用户空间程序序(包括 tcpdump、Wireshark 等),使得后者能方便的调用BPF实现抓包过滤等工具。也就是说,libpcap是BPF的一层API封装。
tcpdump调用了libpcap的接口,后者调用BPF实现了报文过滤和抓取
其他工具
WinPcap
Windows 上也可以做到类似 Linux 这样的抓包,其底层就是依赖 WinPcap,它是libpcap 的 Windows 版本。
eBPF
Linux 从 3.18 版本开始支持 extended BPF,简称 eBPF。这是一个更加通用的内核接口,不仅能支持网络抓包,还能支持网络以外的内核观测点的信息收集等工作。所以事实上,eBPF 已经是一个通用工具,而不再局限在网络工具这个角色定位上了。
同时,也因为它在数据面上的性能很出色,所以现在不少公司正在探索,利用它实现一些数据面的开发工作,比如高性能的负载均衡。
为什么抓包文件有好几种类型?
抓包文件后缀名有 pcap、cap、pcapng 这几种不同的后缀名。为什么会有好几种类型呢?
pcap
这个是 libpcap 的格式,也是 tcpdump 和 Wireshark 等工具默认支持的文件格式。pcap格式的文件中除了报文数据以外,也包含了抓包文件的元信息,比如版本号、抓包时间、每个报文被抓取的最大长度,等等。
cap
cap 文件可能含有一些 libpcap 标准之外的数据格式,它是由一些 tcpdump 以外的抓包程序生成的。比如 Citrix 公司的 netscaler 负载均衡器,它的 nstrace 命令生成的抓包文件,就是以.cap 为扩展名的。这种文件除了包含 pcap 标准定义的信息以外,还包含了 LB的前端连接和后端连接之间的 mapping 信息。Wireshark 是可以读取这些.cap 文件的,只要在正确的版本上。
pcapng
pcap 格式虽然满足了大部分需求,但是它也有一些不足。比如,现在多网口的情况已经越来越常见了,我们也经常需要从多个网络接口去抓取报文,那么在抓包文件里,如果不把这些报文跟所属的网口信息展示清楚,那我们的分析,岂不是要张冠李戴了吗?
为了弥补 pcap 格式的不足,人们需要有一种新的文件格式,pcapng 就出现了。有了它,单个抓包文件就可以包含多个网络接口上抓取到的报文了。

我们可以看到,上图中右边的 pcapng 格式是包含报文的网络接口信息的,而左边的 pcap就没有。
当然,pcapng 还有很多别的特性,比如更细粒度的报文时间戳、允许对报文添加注释、更灵活的元数据,等等。如果你是用版本比较新的 Wireshark 和 tshark 做抓包,默认生成的抓包文件就已经是 pcapng 格式了。
怎么用
注意,一定要先进入sudo权限
如何抓取报文?
直接启动tcpdump,将抓取所有经过第一个网络接口上的数据包

指定网卡
- tcpdump默认选择第一块网卡(一般是eth0)进行抓包,我们可以使用-i(interface)参数指定通过哪一个网卡抓包,比如下面为抓取所有经过eth1网络接口上的数据包
- tcpdump –i eth1


- 如果想知道我们可以通过哪几个网卡抓包,可以使用-D参数,如:
- lo是回环接口
- any : 通过任意一块网卡进行抓包

指定主机和端口
最常见的场景是要抓取去往某个 ip,或者从某个 ip 过来的流量。
我们可以用host {对端 IP} 作为抓包过滤条件,比如:
tcpdump host 10.10.10.10
抓取某个端口的流量
tcpdump port 22
抓取所有经过ens33,目标或者源地址是
192.168.0.11
tcpdump -i ens33 host 192.168.0.11

抓取主机10.37.63.255和主机10.37.63.61或10.37.63.95的通信:

抓取主机192.168.13.210除了和主机10.37.63.61之外所有主机通信的数据包:

抓取主机10.37.63.255除了和主机10.37.63.61之外所有主机通信的ip包

其他
还有不少参数我们也经常用到,比如:
- -w 文件名,可以把报文保存到文件;
- -c 数量,可以抓取固定数量的报文,这在流量较高时,可以避免一不小心抓取过多报文;
- -s 长度,可以只抓取每个报文的一定长度
- -v/-vv/-vvv,可以打印更加详细的报文信息;
- -e,可以打印二层信息,特别是 MAC 地址;
- -p,关闭混杂模式
- -nn选项: 当tcpdump遇到协议号或者端口号时,不要将这些号码转换成对应的协议名称或者端口名称。比如,众所周知21端口是FTP端口,我们希望显示21,而非tcpdump自作聪明的将它显示成FTP
- -X: 告诉tcpdump命令,需要把协议头和包内容都原原本本的显示出来(tcpdump会以16进制和ASCII的形式显示),这在进行协议分析时是绝对的利器。(待添加例子)
# tcpdump -i ens33 -nn -X 'port 10727' -c 1
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
16:42:07.840634 IP 192.168.0.11.10727 > 128.199.176.14.443: Flags [.], ack 3848341625, win 1026, options [nop,nop,sack 1 {1453:5809}], length 0
0x0000: 4500 0034 0ede 4000 8006 fa5c c0a8 000b E..4..@....\....
0x0010: 80c7 b00e 29e7 01bb 7492 4982 e561 0879 ....)...t.I..a.y
0x0020: 8010 0402 b48e 0000 0101 050a e561 0e25 .............a.%
0x0030: e561 1f29 .a.)
1 packet captured
6 packets received by filter
0 packets dropped by kernel
- ‘port 10727’: 这是告诉tcpdump不要看到啥就显示啥。我们只关心源端口或目的端口是10727的数据包,其他的数据包别给我显示出来
- -c选项:是Count的含义,这设置了我们希望tcpdump帮我们抓几个包。我设置的是1,所以tcpdump不会帮我再多抓哪怕一个包回来。
【-e选项】- 增加以太网帧头部信息输出
- OUI,即Organizationally unique identifier,是“组织唯一标识符”,在任何一块网卡(NIC)中烧录的6字节MAC地址中,前3个字节体现了OUI,其表明了NIC的制造组织。通常情况下,该标识符是唯一的。

【-l选项】- 使得输出变为行缓冲
- 默认是全缓冲的,-I可以将tcpdump的输出变为“行缓冲”方式
- 需求: “对于tcpdump输出的内容,提取每一行的第一个域,即”时间域”,并输出出来,为后续统计所用” ---->
# tcpdump -i ens33 -l |awk '{print $1}'----> 如果不加-l选项,那么只有全缓冲区满,才会输出一次,这样不仅会导致输出是间隔不顺畅的,而且当你ctrl-c时,很可能会断到一行的半截,损坏统计数据的完整性。

【-t选项】- 输出时不打印时间戳
# tcpdump -i eth0 -c 1
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
01:52:10.433391 ARP, Request who-has 116.255.247.61 tell 116.255.247.125, length 64
# tcpdump -i eth0 -c 1 -t
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
ARP, Request who-has 116.255.245.35 tell 116.255.245.62, length 64
- tcpdump -w google.cap : 将抓包结果存放在google.cap文件中,结束以后可以用Wireshark打开查看
# tcpdump -i ens33 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
15:37:42.628409 IP 192.168.0.212.22 > 192.168.0.11.6665: Flags [P.], seq 2262547790:2262548318, ack 983050816, win 239, length 528
***
<==按下 [ctrl]-c 之之后結束
6680 packets captured <==捉下來的封包数量
14250 packets received by filter <==由过滤所得的總封包數量
7512 packets dropped by kernel <==被核心所丢弃的封包
-
15:37:42.628409: 封包被抓取的时间: 时:分:秒
-
IP : IP协议
-
192.168.0.212.22 > 192.168.0.11.6665: 发送方的ip是192.168.0.212,端口是22;接收方的ip是192.168.0.11,端口是6665
-
只取出 port 22的包
# tcpdump -i ens33 -nn port 22
15:42:35.407981 IP 192.168.0.11.6665 > 192.168.0.212.22: Flags [.], ack 34000, win 8209, length 0
15:42:35.409271 IP 192.168.0.212.22 > 192.168.0.11.6665: Flags [P.], seq 34000:34048, ack 6225, win 239, length 48
15:42:35.409292 IP 192.168.0.212.22 > 192.168.0.11.6665: Flags [P.], seq 34048:34080, ack 6225, win 239, length 32
15:42:35.409310 IP 192.168.0.11.6665 > 192.168.0.212.22: Flags [.], ack 34080, win 8208, length 0
如何过滤报文
例子1
比如如果我们想要统计某个HTTPS VIP的访问流量里,TLS版本(TLS1.0、1.1、1.2、1.3)的分布。为了控制抓包文件的大小,我们又不想什么TLS报文都抓,只想抓取TLS版本信息。但是问题是针对这个需求,tcpdump本身没有一个现成的过滤器。 怎么做呢?
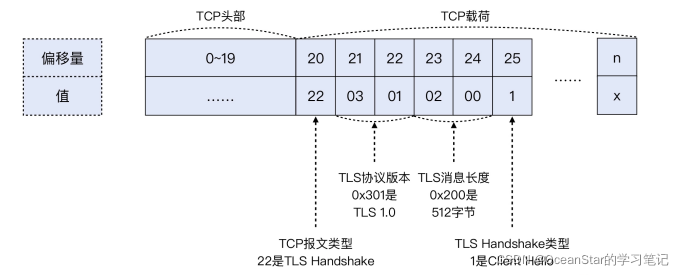
其实,BPF本身是基于偏移量来做报文解析的,所以我们可以在tcpdump中使用这种偏移量技术,实现我们的需求。 下面这个命令,就可以抓取到 TLS 握手阶段的 ClientHello 报文:
tcpdump -w file.pcap 'dst port 443 && tcp[20]==22 && tcp[25]==1
- dst port 443:这个最简单,就是抓取从客户端发过来的访问 HTTPS 的报文。
- tcp[20]==22:这是提取了 TCP 的第 21 个字节(因为初始序号是从 0 开始的),由于TCP 头部占 20 字节,TLS 又是 TCP 的载荷,那么 TLS 的第 1 个字节就是 TCP 的第21 个字节,也就是 TCP[20],这个位置的值如果是 22(十进制),那么就表明这个是TLS 握手报文。
- tcp[25]==1:同理,这是 TCP 头部的第 26 个字节,如果它等于 1,那么就表明这个是\Client Hello 类型的 TLS 握手报文
下面是抓包文件里的样子:
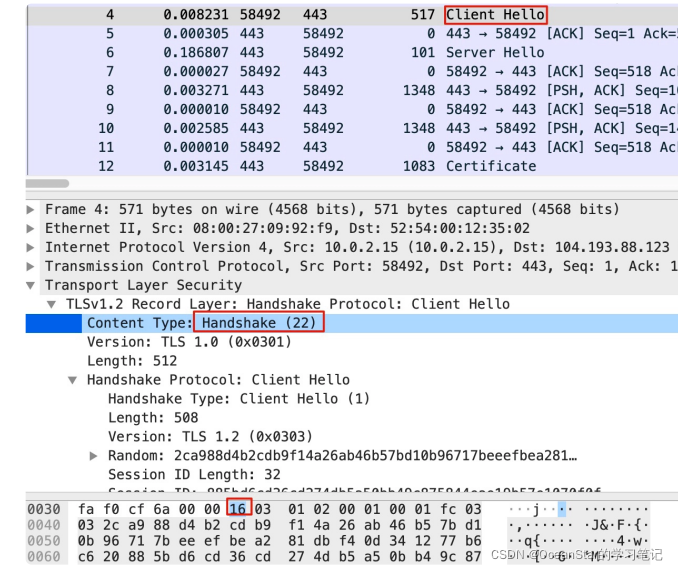
这里你可能会有疑问:上面的图里,TCP[20]的位置的值不是 16 吗?其实,这个是十六进制的 16,换算成十进制,就是 22 了。
例子2
对一些常见的过滤场景,tcpdump 也预定义了一些相对方便的过滤器。比如我们想要过滤出 TCP RST 报文,那么可以用下面这种写
法,相对来说比用数字做偏移量的写法,要更加容易理解和记忆:
tcpdump -w file.pcap 'tcp[tcpflags]&(tcp-rst) != 0'
如果是用偏移量的写法,会是下面这样:
tcpdump -w file.pcap 'tcp[13]&4 != 0'
如何在抓包时显示报文内容?
有时候你想看 TCP 报文里面的具体内容,比如应用层的数据,那么你可以用 -X 这个参数,以 ASCII 码来展示 TCP 里面的数据:
$ sudo tcpdump port 80 -X

如何读取抓包文件?
tcpdump 加上 -r 参数和文件名称,就可以读取这个文件了,而且也可以加上过滤条件。比如:
tcpdump -r file.pcap 'tcp[tcpflags] & (tcp-rst) != 0'
如何过滤后转存?
有时候,我们想从抓包文件中过滤出想要的报文,并转存到另一个文件中。比如想从一个抓包文件中找到 TCP RST 报文,并把这些 RST 报文保存到新文件。那么就可以这么做:
tcpdump -r file.pcap 'tcp[tcpflags] & (tcp-rst) != 0' -w rst.pcap
如何让抓包时间尽量长一点?
-s 这个长度参数,它的使用场景其实就包括了延长抓包时间。我们给tcpdump 加上 -s 参数,指定抓取的每个报文的最大长度,就节省抓包文件的大小,也就延长了抓包时间。
一般来说,帧头是 14 字节,IP 头是 20 字节,TCP 头是 20~40 字节。如果你明确地知道这次抓包的重点是传输层,那么理论上,对于每一个报文,你只要抓取到传输层头部即可,也就是前 14+20+40 字节(即前 74 字节):
tcpdump -s 74 -w file.pcap
而如果是默认抓取 1500 字节,那么生成的抓包文件将是上面这个抓包文件的 20 倍。
但是,如果你还想看 TLS 甚至更上层的应用层的信息,这么做就不行了。比如下面这个抓包就是用了 74 字节作为每个报文的抓取长度,所以第五层开始的信息,就看不到或者看不全了。
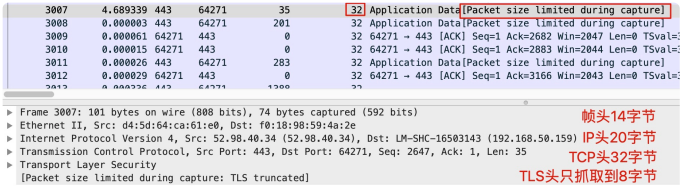
显然,TLS 只分到了 8 个字节,信息不完整,所以 Wireshark 也无能为力,没法告诉我们这个 TLS 头部里的信息了。
tcptrace
不过,有时候我们并不方便用 Wireshark 打开抓包文件做分析,比如抓包的机器不允许向外传文件,也就是可能只能在这台机器上做分析。我们可以用 tcpdump -r 的方式,打开原始抓包文件看看:
$ tcpdump -r test.pcap | head -10
reading from file test.pcap, link-type EN10MB (Ethernet)
03:55:10.769412 IP victorebpf.51952 > 180.101.49.12.https: Flags [S], seq 3448
03:55:10.779061 IP 180.101.49.12.https > victorebpf.51952: Flags [S.], seq 156
03:55:10.779111 IP victorebpf.51952 > 180.101.49.12.https: Flags [.], ack 1, w
03:55:10.784134 IP victorebpf.51952 > 180.101.49.12.https: Flags [P.], seq 1:5
03:55:10.784297 IP 180.101.49.12.https > victorebpf.51952: Flags [.], ack 518,
03:55:10.795094 IP 180.101.49.12.https > victorebpf.51952: Flags [P.], seq 1:1
03:55:10.795118 IP victorebpf.51952 > 180.101.49.12.https: Flags [.], ack 1502
03:55:10.795327 IP 180.101.49.12.https > victorebpf.51952: Flags [P.], seq 150
03:55:10.795356 IP victorebpf.51952 > 180.101.49.12.https: Flags [.], ack 3881
03:55:10.802868 IP 180.101.49.12.https > victorebpf.51952: Flags [P.], seq 388
报文都是按时间线原样展示的,缺乏逻辑关系,是不是难以组织起有效的分析?比如,要搞清楚里面有几条 TCP 连接都不太容易。这时候怎么办呢?
其实,还有一个工具能帮上忙,它就是 tcptrace。它不能用来抓包,但是可以用来分析。
比如下面这样,tcptrace 告诉我们,这个抓包文件里有 2 个 TCP 连接,并且是以 RST 结束的:
$ tcptrace -b test.pcap
1 arg remaining, starting with 'test.pcap'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004
145 packets seen, 145 TCP packets traced
elapsed wallclock time: 0:00:00.028527, 5082 pkts/sec analyzed
trace file elapsed time: 0:00:04.534695
TCP connection info:
1: victorebpf:51952 - 180.101.49.12:443 (a2b) 15> 15< (complete) (rese
2: victorebpf:56794 - 180.101.49.58:443 (c2d) 56> 59< (complete) (rese


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









