







 本文详细解析了SQL中的多表关联查询,包括内连接和外连接的概念及应用。通过实例解释了内连接如何根据关联条件返回匹配数据,而外连接则允许返回即使在另一表中没有匹配项的数据。讨论了嵌套循环关联可能导致的性能问题,并强调了索引对于提升多表关联查询效率的重要性。优化多表关联的关键在于合理建立索引,确保驱动表和被驱动表的查询都通过索引进行。
本文详细解析了SQL中的多表关联查询,包括内连接和外连接的概念及应用。通过实例解释了内连接如何根据关联条件返回匹配数据,而外连接则允许返回即使在另一表中没有匹配项的数据。讨论了嵌套循环关联可能导致的性能问题,并强调了索引对于提升多表关联查询效率的重要性。优化多表关联的关键在于合理建立索引,确保驱动表和被驱动表的查询都通过索引进行。
多表关联最最基本的原理
我们先来看一下这个SQL语句:select * from t1,t2 where t1.x1=xxx and t1.x2=t2.x2 and t2.x3=xxx
- 首先,如果你在FROM语句后直接来了两个表名,这意思就是要针对两个表进行查询了,而且会把两个表的数据给关联起来,假设你要是没有限定什么多表连接条件,那么可能会搞出来一个笛卡尔积的东西
- 举个例子,假设t1表里有10条数据,t2表里与5条数据,那么此时select * from t1, t2,其实会查出来50条数据,因为t1表里的每条数据都会跟t2表里的每条数据连接起来返回给你,那么就是查出来10*5=50套数据。这就是笛卡尔积。
- 不过通常一般没人会傻到写类似这样的SQL语句,因为查出来这种数据实在是没什么意义。所以通常都会在多表关联语句中的where子句里引入一些关联条件,现在我们来看一下上面的WHERE子句:where t1.x1=xxx and t1.x2=t2.x2 and t2.x3=xxx
- 首先呢,t1.x1=xxx,这个可以明确,绝对不是多表关联的连接条件,他是针对t1表的数据筛选条件,本质是从t1表里筛选出一波数据出来再跟t2表做关联的意思。然后t2.x3=xxx,也不是关联条件,他也是针对t2表的筛选条件。
- 其实真正的关联条件是t1.x2=t2.x2,这个条件,意思就是说,必须要让t1表里的每条数据根据自己的x2字段的值去关联上t2表里的某条记录,要求是t1表里这条数据的x2值和t2表里的那条数据的x2字段值是相等的。
- 举个例子,假设t1表里有1条数据的x2字段的值是265,然后t2表里有2条数据的x2字段的值也是265,那么此时就会把t1表里的那条数据和t2表的2条数据分别关联起来,最终会返回给你两条关联后的数据。
那么基本概念理解清楚了,具体到上面的SQL语句:select * from t1,t2 where t1.x1=xxx and t1.x2=t2.x2 and t2.x3=xxx。这个SQL执行的过程可能是类似这样的:
- 首先根据t1.x1=xxx这个筛选条件,去t1表里查出来一批数据,此时可能是const、ref、index、all,都有可能,具体看你索引如何建的
- 然后假设从t1表里按照t1.x1=xxx条件筛选出2条数据,接着对这两条数据,根据每条数据的x2字段的值,以及t2.x3=xxx这个条件,去t2表里找x2字段值和x3字段值都匹配的数据,比如说t1表第一条数据的x2字段的值是265,此时就根据t2.x2=265和t2.x3=xxx这俩条件,找出来一波数据,比如找出来2条吧。
- 此时就把t1表里x2字段为265的那个数据跟t2表里t2.x2=265和t2.x3=xxx的两条数据,关联起来,就可以了,t1表里另外一条数据也是如法炮制而已,这就是多表关联最最基本的原理。
- 记住,他可能是先从一个表里查一波数据,这个表叫做“驱动表”,再根据这波数据去另外一个表里查一波数据进行关联,另外一个表叫做“被驱动表”
内连接&外连接
假设我们有一个员工表,还有一个产品销售业绩表:
- 员工表里包含了id(主键)、name(姓名)、department(部门)
- 产品销售业绩表里包含了id(主键)、employee_id(员工id)、产品名称
(product_name)、销售业绩(saled_amount)。
现在假设你想看看每个员工对每个产品的销售业绩,写个SQL:
select
e.name,e.department,
ps.product_name,ps.saled_amount
from employee e,product_saled pa
where e.id=pa.employee_id
此时看到的数据可能如下:
员工 部门 产品 业绩
张三 大客户部 产品A 30万
张三 大客户部 产品B 50万
张三 大客户部 产品C 80万
李四 零售部 产品A 10万
李四 零售部 产品B 12万
上面SQL执行原理:
- 先从员工表中左全表扫描,找出每个员工,然后针对每个员工的id去业绩表里找employee_id与员工id相等的数据,可能每个员工的id在业绩表里都会找到多条数据,因为他可有多个产品的销售业绩
- 然后就是把每个员工数据跟他在业绩表里找到的所有业绩数据都关联起来,比如张三这个员工就关联了业绩表里的三条数据,李四这个员工关联了业绩表中的两台数据。
上面过程就是内连接,inner join,意识是要求两个表里的数据必须是完全能关联上的,才能返回回来,这就是内连接
那么现在有这么一个问题,假设员工表里有一个人是新员工,入职到现在一个单子都没开过,也就没有任何的销售业绩,那么此时还是希望能够查出来这个员工的数据,只不过他的销售业绩那块可以给个NULL就行了,表示他没任何业绩。
但是如果仅仅是使用上述SQL语法,似乎是搞不定的,因为那种语法要求,必须要两个表能关联上的数据才会查出来,像你员工表里可能有个王五,根本在业绩表里关联不上任何数据,此时这个人是不会查出来的。
所以此时就要到外连接了,也就是outer join,这个outer join分为左外连接和右外连接:
- 左外连接的意思就是,在左侧的表里的某条数据,如果在右侧的表里关联不到任何数据,也得把左侧表这个数据给返回出来
- 右外连接反之,在右侧的表里如果关联不到左侧表里的任何数据,得把右侧表的数据返回出来。
而且,这里还有一个语法限制,如果你是之前的那种内连接,那么连接条件是可以放在where语句里的,但是外连接一般是把连接条件放在ON字句里的,所以此时可以写出如下的SQL语句:
SELECT
e.name,
e.department,
ps.product_name,
ps.saled_amount
FROM employee e LEFT OUTER JOIN product_saled pa
ON e.id=pa.employee_id
此时返回的数据里,你可能会看到如下的结果:
员工 部门 产品 业绩
张三 大客户部 产品A 30万
张三 大客户部 产品B 50万
张三 大客户部 产品C 80万
李四 零售部 产品A 10万
李四 零售部 产品B 12万
王五 零售部 NULL NULL
其实一般写多表关联,主要就是内连接和外连接
嵌套循环关联
- 简单来说,假设有两个表要一起执行关联,此时会先在一个驱动表里根据它的where筛选条件找出一波数据,比如说找出10条数据
- 接着就对这10条数据走一个循环,用每条数据都到另外一个被驱动表里根据on连接条件和where里的被驱动表的筛选条件去查找数据,找出来的数据就进行关联
- 以此类推,假设驱动表里找出来10条数据,那么就要被驱动表里去查询10次。
- 那么如果是三个表进行关联呢?那就更夸张了,你从表1里查出来10条数据,接着去表2里查10次,假设每次都查出来3条数据,然后关联起来,此时你会得到一个30条数据的结果集,接着再用这批数据去表3里去继续查询30次!
- 这种方法的伪代码有点类似下面这样:
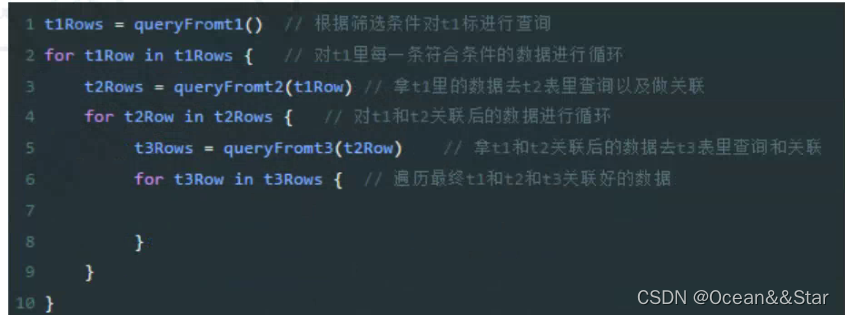
上面那伪代码其实就是3个表关联的伪代码,用的就是最笨的嵌套循环关联方法。
问题是:
- 就是我们往往从驱动表里查出来一波数据之后,要对每一条数据都循环一次去被驱动表里查询数据,所以万一你要是被驱动表的索引都没建好,总不能每次都全表扫描吧?这就是一个很大的问题!
- 另外一个,刚开始对你的驱动表根据WHERE条件进行查询的时候,也总不能全表扫描吧?这也是一个问题!
所以说,为什么有的时候多表关联很慢呢?答案就在这里了
- 你两个表关联,先从驱动表里根据WHERE条件去筛选一波数据,这个过程如果你没给驱动表加索引,万一走一个all全表扫描,岂不是速度很慢?
- 其次,假设你好不容易从驱动表里扫出来一波数据,接着又来一个for循环一条一条去被驱动表里根据ON连接条件和WHERE筛选条件去查,万一你对被驱动表又没加索引,难道又来几十次或者几百次全表扫描?那速度岂不是慢的跟蜗牛一样了!
总结:
- 多表关联本质其实就是先查一个驱动表,接着根据连接条件去被驱动表里循环查询
- 通常而言,针对多表查询的语句,我们要尽量给两个表都加上索引吗,索引要确保从驱动表里查询也是通过索引区查询,接着对被驱动表查询也通过索引区查询。如果能做到这一点,多表关联的语句性能就会很高了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









