







文件的打开和关闭
打开/创建文件
在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
语法:
file = open(文件路径 [, 访问模式='r' [ , buffering=-1 [ , encoding = None ]]])
参数说明:
- 文件路径
- 绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的。
- 相对路径:是从当前文件所在的文件夹开始的路径。
- 访问模式:可选参数
- 当以默认模式打开文件时,默认使用 r 权限,由于该权限要求打开的文件必须存在. 否则会报错: FileNotFoundError: [Errno 2] No such file or directory: ‘a.txt’

- 当以默认模式打开文件时,默认使用 r 权限,由于该权限要求打开的文件必须存在. 否则会报错: FileNotFoundError: [Errno 2] No such file or directory: ‘a.txt’

- buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区
- 如果 buffing 参数的值为 0(或者 False),则表示在打开指定文件时不使用缓冲区;如果 buffing 参数值为大于 1 的整数,该整数用于指定缓冲区的大小(单位是字节);如果 buffing 参数的值为负数,则代表使用默认的缓冲区大小。
- 通常情况下、建议大家在使用 open() 函数时打开缓冲区,即不需要修改 buffing 参数的值。为什么呢?
- 原因很简单,目前为止计算机内存的 I/O 速度仍远远高于计算机外设(例如键盘、鼠标、硬盘等)的 I/O 速度,如果不使用缓冲区,则程序在执行 I/O 操作时,内存和外设就必须进行同步读写操作,也就是说,内存必须等待外设输入(输出)一个字节之后,才能再次输出(输入)一个字节。这意味着,内存中的程序大部分时间都处于等待状态。
- 而如果使用缓冲区,则程序在执行输出操作时,会先将所有数据都输出到缓冲区中,然后继续执行其它操作,缓冲区中的数据会有外设自行读取处理;同样,当程序执行输入操作时,会先等外设将数据读入缓冲区中,无需同外设做同步读写操作。
- encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)。
- 注意,手动修改 encoding 参数的值,仅限于文件以文本的形式打开,也就是说,以二进制格式打开时,不能对 encoding 参数的值做任何修改,否则程序会抛出 ValueError 异常: ValueError: binary mode doesn’t take an encoding argument
举个例子:
f = open('a.txt', 'r')
print(f) #<_io.TextIOWrapper name='a.txt' mode='r' encoding='cp936'>
成功打开文件之后,可以调用文件对象本身拥有的属性获取当前文件的部分信息,其常见的属性为:
- file.name:返回文件的名称;
- file.mode:返回打开文件时,采用的文件打开模式;
- file.encoding:返回打开文件时使用的编码格式;
- file.closed:判断文件是否己经关闭。
关闭文件
close
# 新建一个文件,文件名为:test.txt
f = open('test.txt', 'w')
# 关闭这个文件
f.close()
注意,使用 open() 函数打开的文件对象,必须手动进行关闭,Python 垃圾回收机制无法自动回收打开文件所占用的资源。
with as
任何一门编程语言中,文件的输入输出、数据库的连接断开等,都是很常见的资源管理操作。但资源都是有限的,在写程序时,必须保证这些资源在使用过后得到释放,不然就容易造成资源泄露,轻者使得系统处理缓慢,严重时会使系统崩溃。
如果忘记close或者在打开文件或文件操作过程中抛出了异常,还是无法及时关闭文件。在 Python 中,对应的解决方式是使用 with as 语句操作上下文管理器(context manager),它能够帮助我们自动分配并且释放资源。
使用 with as 操作已经打开的文件对象(本身就是上下文管理器),无论期间是否抛出异常,都能保证 with as 语句执行完毕后自动关闭已经打开的文件。
语法:
with 表达式 [as target]:
代码块
此格式中,用 [] 括起来的部分可以使用,也可以省略。其中,target 参数用于指定一个变量,该语句会将 expression 指定的结果保存到该变量中。with as 语句中的代码块如果不想执行任何语句,可以直接使用 pass 语句代替。
举例:
with open('a.txt', 'a') as f:
f.write("\nPython教程")
文件的读写
写数据(write)
使用write()可以完成向文件写入数据
语法:
file.write(string)
- 其中,file 表示已经打开的文件对象;string 表示要写入文件的字符串(或字节串,仅适用写入二进制文件中)。
- 注意,在使用 write() 向文件中写入数据,需保证使用 open() 函数是以 r+、w、w+、a 或 a+ 的模式打开文件,否则执行 write() 函数会抛出 io.UnsupportedOperation 错误。
- 另外,在写入文件完成后,一定要调用 close() 函数将打开的文件关闭,否则写入的内容不会保存到文件中。这是因为,当我们在写入文件内容时,操作系统不会立刻把数据写入磁盘,而是先缓存起来,只有调用 close() 函数时,操作系统才会保证把没有写入的数据全部写入磁盘文件中。
demo:
- 新建一个文件 file_write_test.py ,向其中写入如下代码:
f = open('test.txt', 'w')
f.write('hello world, i am here!\n' * 5)
f.close()
运行之后会在 file_write_test.py 文件所在的路径中创建一个文件 test.txt ,并写入内容,运行效果显示如下:

如果向文件写入数据后,不想马上关闭文件,也可以调用文件对象提供的 flush() 函数,它可以实现将缓冲区的数据写入文件中。例如:
f = open("a.txt", 'w')
f.write("写入一行新数据")
f.flush()
能不能通过设置 open() 函数的 buffering 参数可以关闭缓冲区,这样数据不就可以直接写入文件中了?对于以二进制格式打开的文件,可以不使用缓冲区,写入的数据会直接进入磁盘文件;但对于以文本格式打开的文件,必须使用缓冲区,否则 Python 解释器会 ValueError 错误。例如:
f = open("a.txt", 'w',buffering = 0)
f.write("写入一行新数据")
运行结果为:
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\demo.py", line 1, in <module>
f = open("a.txt", 'w',buffering = 0)
ValueError: can't have unbuffered text I/O
writelines()
- Python 的文件对象中,不仅提供了 write() 函数,还提供了 writelines() 函数,可以实现将字符串列表写入文件中。
- 注意
- 写入函数只有 write() 和 writelines() 函数,而没有名为 writeline 的函数。
- 使用 writelines() 函数向文件中写入多行数据时,不会自动给各行添加换行符
通过使用 writelines() 函数,可以轻松实现将 a.txt 文件中的数据复制到其它文件中
f = open('a.txt', 'r')
n = open('b.txt','w+')
n.writelines(f.readlines())
n.close()
f.close()
读数据(read)
- 对于借助 open() 函数,并以可读模式(包括 r、r+、rb、rb+)打开的文件,可以调用 read() 函数逐个字节(或者逐个字符)读取文件中的内容。
- 如果文件是以文本模式(非二进制模式)打开的,则 read() 函数会逐个字符进行读取;
- 反之,如果文件以二进制模式打开,则 read() 函数会逐个字节进行读取。
语法:
file.read([size])
- 其中,file 表示已打开的文件对象;
- size 作为一个可选参数,用于指定一次最多可读取的字符(字节)个数,如果省略,则默认一次性读取所有内容。
- 再次强调,size 表示的是一次最多可读取的字符(或字节)数,因此,即便设置的 size 大于文件中存储的字符(字节)数,read() 函数也不会报错,它只会读取文件中所有的数据。
举个例子:
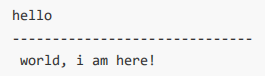
f = open('test.txt', 'r')
content = f.read(5) # 最多读取5个数据
print(content)
print("‐"*30) # 分割线,用来测试
content = f.read() # 从上次读取的位置继续读取剩下的所有的数据
print(content)
f.close() # 关闭文件,这个可是个好习惯哦
- 效果:
举个例子, 对于以二进制格式打开的文件,read() 函数会逐个字节读取文件中的内容:
#以二进制形式打开指定文件
f = open("my_file.txt",'rb+')
#输出读取到的数据
print(f.read())
#关闭文件
f.close()
- 程序执行结果为:
b'Python\xe6\x95\x99\xe7\xa8\x8b\r\nhttp://c.biancheng.net/python/'
- 可以看到,输出的数据为 bytes 字节串。我们可以调用 decode() 方法,将其转换成我们认识的字符串。
读一行数据(readline)
readline只用来读取一行数据(含最后的换行符“\n”)
- 对于读取以文本格式打开的文件,读取一行很好理解;
- 对于读取以二进制格式打开的文件,它们会以“\n”作为读取一行的标志。
语法:
file.readline([size])
- 其中:
- file 为打开的文件对象;
- size 为可选参数,用于指定读取每一行时,一次最多读取的字符(字节)数。
- 和 read() 函数一样,此函数成功读取文件数据的前提是,使用 open() 函数指定打开文件的模式必须为可读模式(包括 r、rb、r+、rb+ 4 种)。
举个例子:
f = open('test.txt', 'r')
content = f.readline(6)
print("1:%s" % content)
content = f.readline()
print("2:%s" % content)
f.close()
读数据(readlines)
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行为列表的 一个元素。
语法:
file.readlines()
举个例子:
f = open('test.txt', 'r')
content = f.readlines()
print(type(content))
for temp in content:
print(temp)
f.close()
tell() , seek()
- tell() 函数用于判断文件指针当前所处的位置
- seek() 函数用于移动文件指针到文件的指定位置。
# with open('demo.txt','rb') as file_obj:
# # print(file_obj.read(100))
# # print(file_obj.read(30))
# # seek() 可以修改当前读取的位置
# file_obj.seek(55)
# file_obj.seek(80,0)
# file_obj.seek(70,1)
# file_obj.seek(-10,2)
# # seek()需要两个参数
# # 第一个 是要切换到的位置
# # 第二个 计算位置方式
# # 可选值:
# # 0 从头计算,默认值
# # 1 从当前位置计算
# # 2 从最后位置开始计算
# print(file_obj.read())
# # tell() 方法用来查看当前读取的位置
# print('当前读取到了 -->',file_obj.tell())
with open('demo2.txt','rt' , encoding='utf-8') as file_obj:
# print(file_obj.read(100))
# print(file_obj.read(30))
# seek() 可以修改当前读取的位置
file_obj.seek(9)
# seek()需要两个参数
# 第一个 是要切换到的位置
# 第二个 计算位置方式
# 可选值:
# 0 从头计算,默认值
# 1 从当前位置计算
# 2 从最后位置开始计算
print(file_obj.read())
# tell() 方法用来查看当前读取的位置
print('当前读取到了 -->',file_obj.tell())
文件的遍历
Python os.walk() 方法
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。
在Unix,Windows中有效。
语法
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
for root, dirs, files in os.walk(".", topdown=False):
for name in files:
print(os.path.join(root, name))
for name in dirs:
print(os.path.join(root, name))
序列化和反序列化
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无 法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字 节序列恢复到内存中,就是反序列化。
- 对象—》字节序列 === 序列化
- 字节序列–》对象 ===反序列化
Python中提供了JSON这个模块用来实现数据的序列化和反序列化。
JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换标准。JSON的本质是字符串。
使用JSON实现序列化
JSON提供了dump和dumps方法,将一个对象进行序列化。
dumps方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能。
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
# file.write(names) 出错,不能直接将列表写入到文件里
# 可以调用 json的dumps方法,传入一个对象参数
result = json.dumps(names)
# dumps 方法得到的结果是一个字符串
print(type(result)) # <class 'str'>
# 可以将字符串写入到文件里
file.write(result)
file.close()
dump方法可以在将对象转换成为字符串的同时,指定一个文件对象,把转换后的字符串写入到这个文件里。
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
# dump方法可以接收一个文件参数,在将对象转换成为字符串的同时写入到文件里
json.dump(names, file)
file.close()
使用JSON实现反序列化
使用loads和load方法,可以将一个JSON字符串反序列化成为一个Python对象。
loads方法需要一个字符串参数,用来将一个字符串加载成为Python对象。
import json
# 调用loads方法,传入一个字符串,可以将这个字符串加载成为Python对象
result = json.loads('["zhangsan", "lisi", "wangwu", "jerry", "henry", "merry", "chris"]')
print(type(result)) # <class 'list'>
load方法可以传入一个文件对象,用来将一个文件对象里的数据加载成为Python对象。
import json
# 以可读方式打开一个文件
file = open('names.txt', 'r')
# 调用load方法,将文件里的内容加载成为一个Python对象
result = json.load(file)
print(result)
file.close()
常见错误
read()函数抛出UnicodeDecodeError异常的解决方法
在使用 read() 函数时,如果 Python 解释器提示UnicodeDecodeError异常,其原因在于,目标文件使用的编码格式和 open() 函数打开该文件时使用的编码格式不匹配。
举个例子,如果目标文件的编码格式为 GBK 编码,而我们在使用 open() 函数并以文本模式打开该文件时,手动指定 encoding 参数为 UTF-8。这种情况下,由于编码格式不匹配,当我们使用 read() 函数读取目标文件中的数据时,Python 解释器就会提示UnicodeDecodeError异常。
要解决这个问题,要么将 open() 函数中的 encoding 参数值修改为和目标文件相同的编码格式,要么重新生成目标文件(即将该文件的编码格式改为和 open() 函数中的 encoding 参数相同)。
除此之外,还有一种方法:先使用二进制模式读取文件,然后调用 bytes 的 decode() 方法,使用目标文件的编码格式,将读取到的字节串转换成认识的字符串。
举个例子:
#以二进制形式打开指定文件,该文件编码格式为 utf-8
f = open("my_file.txt",'rb+')
byt = f.read()
print(byt)
print("\n转换后:")
print(byt.decode('utf-8'))
#关闭文件
f.close()
程序执行结果为:
b'Python\xe6\x95\x99\xe7\xa8\x8b\r\nhttp://c.biancheng.net/python/'
转换后:
Python教程
http://c.biancheng.net/python/















 3660
3660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









