







参考文档
常用maven库及导入本地jar到本地maven库
常用的maven库:
http://mvnrepository.com/
http://search.maven.org/
http://repository.sonatype.org/content/groups/public/
http://people.apache.org/repo/m2-snapshot-repository/
http://people.apache.org/repo/m2-incubating-repository/环境
win下使用myeclipse远程连接hadoop集群(cdh5.3.0)。
对应的hadoop的三个基础组件的jar包都是2.5.0(mapreduce、common、yarn)
IDE:Myeclipse10.7
需要补充的是,我所有的jar包都有在maven的本地库中,因为之前有编译过hadoop2.5.0的源码,并且maven等已经安装好了,详细请参考(window7中)maven 查看 hadoop2.5.0源码
myeclispe新建maven项目
file =>new =>other =>Maven project,在Create a simple project 前面打钩
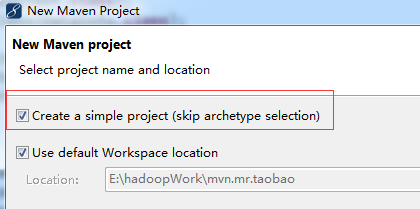
选择next,输入groupid和artifactid
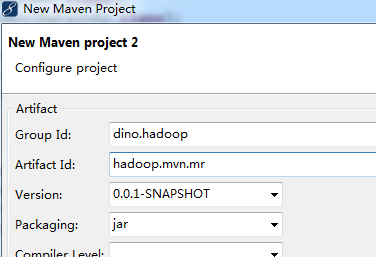
选择finish
groupid和artifactid相当于一个数据库实例与数据库的关系,一个groupid下可以有多个artifactid,一个artifactid相当于一个项目的样子
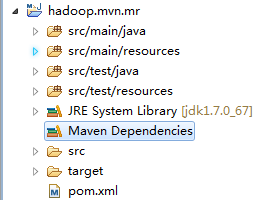
项目建好后的结构图如下
项目中的pom.xml是空的,如下
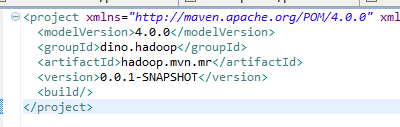
事实上一个简单的maven项目建好了,剩下的就是依赖的问题
增加hadoop的基础依赖
在前面加入dependencies,完整的代码如下,只要复制即可
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>fengming.hadoop.mvn</groupId>
<artifactId>mvn.mr.taobao</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build/>
<dependencies>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>junit</groupId> <!-- 单元测试 建议增加-->
<artifactId>junit</artifactId>
<version>4.8.2</version>
<scope>test</scope>
</dependency>
<dependency><!-- hdfs开发相关 ,必要-->
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.0</version>
</dependency>
<dependency><!-- hadoop的常用工具集 ,必要 -->
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.0</version>
</dependency>
<dependency> <!-- mapreduce的相关 -->
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.5.0</version>
</dependency>
<!-- 有些版本的hadoop-mapreduce-client-common可能命名为hadoop-mapreduce-client-core
出现Cannot initialize Cluster的错误原因也是因为一开始使用的是这个配置
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>x。x。xx</version>
</dependency>
-->
<dependency> <!-- yarn相关 -->
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.5.0</version>
</dependency>
</dependencies>
</project>在pom.xml配置以上选项之后,所有的对应包的相关依赖包也会被导入进来
错误Cannot initialize Cluster
Exception in thread “main” java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:120)

错误产生的原因是在client提交作业的时候找不到对应的类,这里有朋友写了yarn提交作业的流程与源码分析,
Hadoop2.0 客户端提交作业流程
另外根据网上的一些其他信息,我确认我的pom.xml中缺少了一些mapreduce的jar包,所以在项目的pom.xml中加入了
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.5.0</version>
</dependency>这个错误解决方案仅供参考,请问题相关的人结合自己的实际环境进行,导致该问题的原因可能还有其他,比如需要添加的artifactid可能未必是这个,可以参考我在本文的开头的引用文章自行搜索解决的jar包将其添加到自己的pom.xml文件中。














 2127
2127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









