









题目描述
关于对于学生成绩相关的练习题,之前是一个入门级别的需求,现在对这些需求进行增强,首先看数据的改变:
computer,huangxiaoming,85,86,41,75,93,42,85
computer,xuzheng,54,52,86,91,42
computer,huangbo,85,42,96,38
english,zhaobenshan,54,52,86,91,42,85,75
english,liuyifei,85,41,75,21,85,96,14
algorithm,liuyifei,75,85,62,48,54,96,15
computer,huangjiaju,85,75,86,85,85
english,liuyifei,76,95,86,74,68,74,48
english,huangdatou,48,58,67,86,15,33,85
algorithm,huanglei,76,95,86,74,68,74,48
algorithm,huangjiaju,85,75,86,85,85,74,86
computer,huangdatou,48,58,67,86,15,33,85
english,zhouqi,85,86,41,75,93,42,85,75,55,47,22
english,huangbo,85,42,96,38,55,47,22
algorithm,liutao,85,75,85,99,66
computer,huangzitao,85,86,41,75,93,42,85
math,wangbaoqiang,85,86,41,75,93,42,85
computer,liujialing,85,41,75,21,85,96,14,74,86
computer,liuyifei,75,85,62,48,54,96,15
computer,liutao,85,75,85,99,66,88,75,91
computer,huanglei,76,95,86,74,68,74,48
english,liujialing,75,85,62,48,54,96,15
math,huanglei,76,95,86,74,68,74,48
math,huangjiaju,85,75,86,85,85,74,86
math,liutao,48,58,67,86,15,33,85
english,huanglei,85,75,85,99,66,88,75,91
math,xuzheng,54,52,86,91,42,85,75
math,huangxiaoming,85,75,85,99,66,88,75,91
math,liujialing,85,86,41,75,93,42,85,75
english,huangxiaoming,85,86,41,75,93,42,85
algorithm,huangdatou,48,58,67,86,15,33,85
algorithm,huangzitao,85,86,41,75,93,42,85,75一、数据解释
数据字段个数不固定:
第一个是课程名称,总共四个课程,computer,math,english,algorithm,
第二个是学生姓名,后面是每次考试的分数
二、统计需求:
1、统计每门课程的参考人数和课程平均分
2、统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数
3、求出每门课程参考学生成绩最高的2个学生的信息:课程,姓名和平均分
三、解题思路
mapper阶段的输出:
key: CourseScore
value: NullWritable
reducer阶段的输出:
key: CourseScore
value:NullWritable
实现难点:
分组条件(课程) 和 排序规则(课程,成绩)不一致,所以需要自定义分组
自定义分组的代码 CourseScoreGroupComparator.java 在 MR 程序里头
四、代码实现
package com.ghgj.mazh.mapreduce.exercise.coursescore3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CourseScoreMR_Pro_03 {
public static void main(String[] args) throws Exception {
/**
* 一些参数的初始化
*/
String inputPath = "D:\\bigdata\\coursescore2\\input";
String outputPath = "D:\\bigdata\\coursescore2\\output3";
/**
* 初始化一个Job对象
*/
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
/**
* 设置jar包所在路径
*/
job.setJarByClass(CourseScoreMR_Pro_03.class);
/**
* 指定mapper类和reducer类 等各种其他业务逻辑组件
*/
job.setMapperClass(Mapper_CS.class);
job.setReducerClass(Reducer_CS.class);
// 指定maptask的输出类型
job.setMapOutputKeyClass(CourseScore.class);
job.setMapOutputValueClass(NullWritable.class);
// 指定reducetask的输出类型
job.setOutputKeyClass(CourseScore.class);
job.setOutputValueClass(NullWritable.class);
job.setGroupingComparatorClass(CourseScoreGroupComparator.class);
/**
* 指定该mapreduce程序数据的输入和输出路径
*/
Path input = new Path(inputPath);
Path output = new Path(outputPath);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output)) {
fs.delete(output, true);
}
FileInputFormat.setInputPaths(job, input);
FileOutputFormat.setOutputPath(job, output);
/**
* 最后提交任务
*/
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
}
/**
* Mapper组件:
* <p>
* 输入的key:
* 输入的value: computer,xuzheng,54,52,86,91,42
* <p>
* 输出的key: CourseScore
* 输入的value: NullWritable
*/
private static class Mapper_CS extends Mapper<LongWritable, Text, CourseScore, NullWritable> {
CourseScore keyOut = new CourseScore();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] splits = value.toString().split(",");
String course = splits[0];
String name = splits[1];
int sum = 0;
int num = 0;
for(int i=2; i<splits.length; i++){
sum += Integer.valueOf(splits[i]);
num ++;
}
double avgScore = Math.round(sum * 1D / num * 10) / 10D;
keyOut.setCourse(course);
keyOut.setName(name);
keyOut.setScore(avgScore);
context.write(keyOut, NullWritable.get());
}
}
/**
* Reducer组件:
* <p>
* 输入的key: CourseScore
* 输入的values: NullWritable
* <p>
* 输出的key: CourseScore
* 输入的value: NullWritable
*/
private static class Reducer_CS extends Reducer<CourseScore, NullWritable, CourseScore, NullWritable> {
// 成绩最高的两个人的信息
int topN = 2;
@Override
protected void reduce(CourseScore key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
int number = 0;
for(NullWritable nvl: values){
context.write(key, nvl);
number ++;
if(number == topN){
break;
}
}
}
}
/**
* 自定义分组组件
*/
public static class CourseScoreGroupComparator extends WritableComparator{
CourseScoreGroupComparator(){
super(CourseScore.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
CourseScore cs1 = (CourseScore)a;
CourseScore cs2 = (CourseScore)b;
int result = cs1.getCourse().compareTo(cs2.getCourse());
return result;
}
}
}
其中 CourseScore类的实现:
package com.ghgj.mazh.mapreduce.exercise.coursescore3;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class CourseScore implements WritableComparable<CourseScore> {
private String course;
private String name;
private double score;
public CourseScore(String course, String name, double score) {
super();
this.course = course;
this.name = name;
this.score = score;
}
public CourseScore() {
}
public String getCourse() {
return course;
}
public void setCourse(String course) {
this.course = course;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(course);
out.writeUTF(name);
out.writeDouble(score);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.course = in.readUTF();
this.name = in.readUTF();
this.score = in.readDouble();
}
/**
* 排序规则
* compareTo方法既充当排序用,用充当分组规则
*/
@Override
public int compareTo(CourseScore cs) {
int courseDiff = this.course.compareTo(cs.getCourse());
if (courseDiff == 0) {
double diff = cs.getScore() - this.score;
if (diff == 0) {
return 0;
} else {
return diff > 0 ? 1 : -1;
}
} else {
return courseDiff > 0 ? 1 : -1;
}
}
@Override
public String toString() {
return course + "\t" + name + "\t" + score;
}
}
五、执行结果
最后的结果:每个课程的最高成绩的前2名
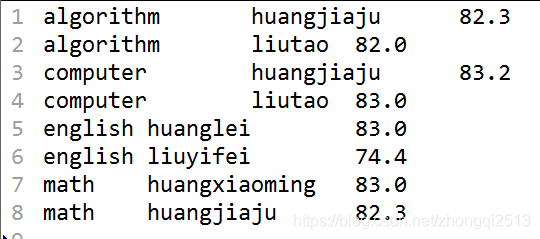
至此,大功告成














 6368
6368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









