






转自:http://blog.csdn.net/tanggao1314/article/details/51457585
一.概念
哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值。
哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。
使用哈希查找有两个步骤:
1. 使用哈希函数将被查找的键转换为数组的索引。在理想的情况下,不同的键会被转换为不同的索引值,但是在有些情况下我们需要处理多个键被哈希到同一个索引值的情况。所以哈希查找的第二个步骤就是处理冲突
2. 处理哈希碰撞冲突。有很多处理哈希碰撞冲突的方法,本文后面会介绍拉链法和线性探测法。
哈希表是一个在时间和空间上做出权衡的经典例子。如果没有内存限制,那么可以直接将键作为数组的索引。那么所有的查找时间复杂度为O(1);如果没有时间限制,那么我们可以使用无序数组并进行顺序查找,这样只需要很少的内存。哈希表使用了适度的时间和空间来在这两个极端之间找到了平衡。只需要调整哈希函数算法即可在时间和空间上做出取舍。
在Hash表中,记录在表中的位置和其关键字之间存在着一种确定的关系。这样我们就能预先知道所查关键字在表中的位置,从而直接通过下标找到记录。使ASL趋近与0.
1) 哈希(Hash)函数是一个映象,即: 将关键字的集合映射到某个地址集合上,它的设置很灵活,只要这个地 址集合的大小不超出允许范围即可;
2) 由于哈希函数是一个压缩映象,因此,在一般情况下,很容易产生“冲突”现象,即: key1!=key2,而 f (key1) = f(key2)。
3). 只能尽量减少冲突而不能完全避免冲突,这是因为通常关键字集合比较大,其元素包括所有可能的关键字, 而地址集合的元素仅为哈希表中的地址值
在构造这种特殊的“查找表” 时,除了需要选择一个“好”(尽可能少产生冲突)的哈希函数之外;还需要找到一 种“处理冲突” 的方法。
二.Hash构造函数的方法
1.直接定址法:
直接定址法是以数据元素关键字k本身或它的线性函数作为它的哈希地址,即:H(k)=k 或 H(k)=a×k+b ; (其中a,b为常数)
例1,有一个人口统计表,记录了从1岁到100岁的人口数目,其中年龄作为关键字,哈希函数取关键字本身,如图(1):
地址 | A1 | A2 | …… | A99 | A100 |
年龄 | 1 | 2 | …… | 99 | 100 |
人数 | 980 | 800 | …… | 495 | 107 |
可以看到,当需要查找某一年龄的人数时,直接查找相应的项即可。如查找99岁的老人数,则直接读出第99项即可。
地址 | A0 | A1 | …… | A99 | A100 |
年龄 | 1980 | 1981 | …… | 1999 | 2000 |
人数 | 980 | 800 | …… | 495 | 107 |
如果我们要统计的是80后出生的人口数,如上表所示,那么我们队出生年份这个关键字可以用年份减去1980来作为地址,此时f(key)=key-1980
这种哈希函数简单,并且对于不同的关键字不会产生冲突,但可以看出这是一种较为特殊的哈希函数,实际生活中,关键字的元素很少是连续的。用该方法产生的哈希表会造成空间大量的浪费,因此这种方法适应性并不强。[2]↑
此法仅适合于:地址集合的大小 = = 关键字集合的大小,其中a和b为常数。
2.数字分析法:
假设关键字集合中的每个关键字都是由 s 位数字组成 (u1, u2, …, us),分析关键字集中的全体,并从中提取分布均匀的若干位或它们的组合作为地址。
数字分析法是取数据元素关键字中某些取值较均匀的数字位作为哈希地址的方法。即当关键字的位数很多时,可以通过对关键字的各位进行分析,丢掉分布不均匀的位,作为哈希值。它只适合于所有关键字值已知的情况。通过分析分布情况把关键字取值区间转化为一个较小的关键字取值区间。
例2,要构造一个数据元素个数n=80,哈希长度m=100的哈希表。不失一般性,我们这里只给出其中8个关键字进行分析,8个关键字如下所示:
K1=61317602 K2=61326875 K3=62739628 K4=61343634
K5=62706815 K6=62774638 K7=61381262 K8=61394220
分析上述8个关键字可知,关键字从左到右的第1、2、3、6位取值比较集中,不宜作为哈希地址,剩余的第4、5、7、8位取值较均匀,可选取其中的两位作为哈希地址。设选取最后两位作为哈希地址,则这8个关键字的哈希地址分别为:2,75,28,34,15,38,62,20。
此法适于:能预先估计出全体关键字的每一位上各种数字出现的频度。
3.折叠法:
将关键字分割成若干部分,然后取它们的叠加和为哈希地址。两种叠加处理的方法:移位叠加:将分 割后的几部分低位对齐相加;边界叠加:从一端沿分割界来回折叠,然后对齐相加。
所谓折叠法是将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位),这方法称为折叠法。这种方法适用于关键字位数较多,而且关键字中每一位上数字分布大致均匀的情况。
折叠法中数位折叠又分为移位叠加和边界叠加两种方法,移位叠加是将分割后是每一部分的最低位对齐,然后相加;边界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
例4,当哈希表长为1000时,关键字key=110108331119891,允许的地址空间为三位十进制数,则这两种叠加情况如图:
移位叠加 边界叠加
8 9 1 8 9 1
1 1 9 9 1 1
3 3 1 3 3 1
1 0 8 8 0 1
+ 1 1 0 + 1 1 0
(1) 5 5 9 (3)0 4 4
图(2)由折叠法求哈希地址
用移位叠加得到的哈希地址是559,而用边界叠加所得到的哈希地址是44。如果关键字不是数值而是字符串,则可先转化为数。转化的办法可以用ASCⅡ字符或字符的次序值。
此法适于:关键字的数字位数特别多。
4.平方取中法
这是一种常用的哈希函数构造方法。这个方法是先取关键字的平方,然后根据可使用空间的大小,选取平方数是中间几位为哈希地址。
哈希函数 H(key)=“key2的中间几位”因为这种方法的原理是通过取平方扩大差别,平方值的中间几位和这个数的每一位都相关,则对不同的关键字得到的哈希函数值不易产生冲突,由此产生的哈希地址也较为均匀。
例5,若设哈希表长为1000则可取关键字平方值的中间三位,如图所示:
关键字 | 关键字的平方 | 哈希函数值 |
1234 | 1522756 | 227 |
2143 | 4592449 | 924 |
4132 | 17073424 | 734 |
3214 | 10329796 | 297 |
下面给出平方取中法的哈希函数
//平方取中法哈希函数,结设关键字值32位的整数
//哈希函数将返回key * key的中间10位
Int Hash (int key)
{
//计算key的平方
Key * = key ;
//去掉低11位
Key>>=11;
// 返回低10位(即key * key的中间10位)
Return key %1024;
}
此法适于:关键字中的每一位都有某些数字重复出现频度很高的现象
5.减去法
减去法是数据的键值减去一个特定的数值以求得数据存储的位置。
例7,公司有一百个员工,而员工的编号介于1001到1100,减去法就是员工编号减去1000后即为数据的位置。编号1001员工的数据在数据中的第一笔。编号1002员工的数据在数据中的第二笔…依次类推。从而获得有关员工的所有信息,因为编号1000以前并没有数据,所有员工编号都从1001开始编号。
6.基数转换法
将十进制数X看作其他进制,比如十三进制,再按照十三进制数转换成十进制数,提取其中若干为作为X的哈希值。一般取大于原来基数的数作为转换的基数,并且两个基数应该是互素的。
例Hash(80127429)=(80127429)13=8*137+0*136+1*135+2*134+7*133+4*132+2*131+9=(502432641)10如果取中间三位作为哈希值,得Hash(80127429)=432
为了获得良好的哈希函数,可以将几种方法联合起来使用,比如先变基,再折叠或平方取中等等,只要散列均匀,就可以随意拼凑。
7.除留余数法:
假设哈希表长为m,p为小于等于m的最大素数,则哈希函数为
h(k)=k % p ,其中%为模p取余运算。
例如,已知待散列元素为(18,75,60,43,54,90,46),表长m=10,p=7,则有
h(18)=18 % 7=4 h(75)=75 % 7=5 h(60)=60 % 7=4
h(43)=43 % 7=1 h(54)=54 % 7=5 h(90)=90 % 7=6
h(46)=46 % 7=4
此时冲突较多。为减少冲突,可取较大的m值和p值,如m=p=13,结果如下:
h(18)=18 % 13=5 h(75)=75 % 13=10 h(60)=60 % 13=8
h(43)=43 % 13=4 h(54)=54 % 13=2 h(90)=90 % 13=12
h(46)=46 % 13=7
此时没有冲突,如图8.25所示。
0 1 2 3 4 5 6 7 8 9 10 11 12
|
| 54 |
| 43 | 18 |
| 46 | 60 |
| 75 |
| 90 |
除留余数法求哈希地址
理论研究表明,除留余数法的模p取不大于表长且最接近表长m素数时效果最好,且p最好取1.1n~1.7n之间的一个素数(n为存在的数据元素个数)
8.随机数法:
设定哈希函数为:H(key) = Random(key)其中,Random 为伪随机函数
此法适于:对长度不等的关键字构造哈希函数。
实际造表时,采用何种构造哈希函数的方法取决于建表的关键字集合的情况(包括关键字的范围和形态),以及哈希表 长度(哈希地址范围),总的原则是使产生冲突的可能性降到尽可能地小。
9.随机乘数法
亦称为“乘余取整法”。随机乘数法使用一个随机实数f,0≤f<1,乘积f*k的分数部分在0~1之间,用这个分数部分的值与n(哈希表的长度)相乘,乘积的整数部分就是对应的哈希值,显然这个哈希值落在0~n-1之间。其表达公式为:Hash(k)=「n*(f*k%1)」其中“f*k%1”表示f*k 的小数部分,即f*k%1=f*k-「f*k」
例10,对下列关键字值集合采用随机乘数法计算哈希值,随机数f=0.103149002 哈希表长度n=100得图:
k | f*k | n*((f*k)的小数部分) | Hash(k) |
319426 | 32948.47311 | 47.78411 | 47 |
718309 | 74092.85648 | 86.50448 | 86 |
629443 | 64926.41727 | 42.14427 | 42 |
919697 | 84865.82769 | 83.59669 | 83 |
此方法的优点是对n的选择不很关键。通常若地址空间为p位就是选n=2p.Knuth对常数f的取法做了仔细的研究,他认为f取任何值都可以,但某些值效果更好。如f=(-1)/2=0.6180329...比较理想。
10.字符串数值哈希法
在很都情况下关键字是字符串,因此这样对字符串设计Hash函数是一个需要讨论的问题。下列函数是取字符串前10个字符来设计的哈希函数
Int Hash _ char (char *X)
{
int I ,sum
i=0;
while (i 10 && X[i])
Sum +=X[i++];
sum%=N; //N是记录的条数
}
这种函数把字符串的前10个字符的ASCⅡ值之和对N取摸作为Hash地址,只要N较小,Hash地址将较均匀分布[0,N]区间内,因此这个函数还是可用的。对于N很大的情形,可使用下列函数
int ELFhash (char *key )
{
Unsigned long h=0,g;
whie (*key)
{
h=(h<<4)+ *key;
key++;
g=h & 0 xF0000000L;
if (g) h^=g>>24;
h & =~g;
}
h=h % N
return (h);
}
这个函数称为ELFHash(Exextable and Linking Format ,ELF,可执行链接格式)函数。它把一个字符串的绝对长度作为输入,并通过一种方式把字符的十进制值结合起来,对长字符串和短字符串都有效,这种方式产生的位置不可能不均匀分布。
11.旋转法
旋转法是将数据的键值中进行旋转。旋转法通常并不直接使用在哈希函数上,而是搭配其他哈希函数使用。
例11,某学校同一个系的新生(小于100人)的学号前5位数是相同的,只有最后2位数不同,我们将最后一位数,旋转放置到第一位,其余的往右移。
新生学号 | 旋转过程 | 旋转后的新键值 |
5062101 | 5062101 | 1506210 |
5062102 | 5062102 | 2506210 |
5062103 | 5062103 | 3506210 |
5062104 | 5062104 | 4506210 |
5062105 | 5062105 | 5506210 |
如图
运用这种方法可以只输入一个数值从而快速地查到有关学生的信息。
在实际应用中,应根据具体情况,灵活采用不同的方法,并用实际数据测试它的性能,以便做出正确判定。通常应考虑以下五个因素 :
l 计算哈希函数所需时间 (简单)。
l 关键字的长度。
l 哈希表大小。
l 关键字分布情况。
l 记录查找频率
三.Hash处理冲突方法
通过构造性能良好的哈希函数,可以减少冲突,但一般不可能完全避免冲突,因此解决冲突是哈希法的另一个关键问题。创建哈希表和查找哈希表都会遇到冲突,两种情况下解决冲突的方法应该一致。下面以创建哈希表为例,说明解决冲突的方法。常用的解决冲突方法有以下四种:
通过构造性能良好的哈希函数,可以减少冲突,但一般不可能完全避免冲突,因此解决冲突是哈希法的另一个关键问题。创建哈希表和查找哈希表都会遇到冲突,两种情况下解决冲突的方法应该一致。下面以创建哈希表为例,说明解决冲突的方法。常用的解决冲突方法有以下四种:
1. 开放定址法
这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式:
Hi=(H(key)+di)% m i=1,2,…,n
其中H(key)为哈希函数,m 为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下三种:
l 线性探测再散列
dii=1,2,3,…,m-1
这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
l 二次探测再散列
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
l 伪随机探测再散列
di=伪随机数序列。
具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
例如,已知哈希表长度m=11,哈希函数为:H(key)= key % 11,则H(47)=3,H(26)=4,H(60)=5,假设下一个关键字为69,则H(69)=3,与47冲突。如果用线性探测再散列处理冲突,下一个哈希地址为H1=(3 + 1)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 + 2)% 11 = 5,还是冲突,继续找下一个哈希地址为H3=(3 + 3)% 11 = 6,此时不再冲突,将69填入5号单元,参图8.26 (a)。如果用二次探测再散列处理冲突,下一个哈希地址为H1=(3 + 12)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 - 12)% 11 = 2,此时不再冲突,将69填入2号单元,参图8.26 (b)。如果用伪随机探测再散列处理冲突,且伪随机数序列为:2,5,9,……..,则下一个哈希地址为H1=(3 + 2)% 11 = 5,仍然冲突,再找下一个哈希地址为H2=(3 + 5)% 11 = 8,此时不再冲突,将69填入8号单元,参图8.26 (c)。
0 1 2 3 4 5 6 7 8 9 10
|
|
| 47 | 26 | 60 | 69 |
|
|
|
|
(a) 用线性探测再散列处理冲突
0 1 2 3 4 5 6 7 8 9 10
|
| 69 | 47 | 26 | 60 |
|
|
|
|
|
(b) 用二次探测再散列处理冲突
0 1 2 3 4 5 6 7 8 9 10
|
|
| 47 | 26 | 60 |
|
| 69 |
|
|
(c) 用伪随机探测再散列处理冲突
图8.26开放地址法处理冲突
从上述例子可以看出,线性探测再散列容易产生“二次聚集”,即在处理同义词的冲突时又导致非同义词的冲突。例如,当表中i, i+1 ,i+2三个单元已满时,下一个哈希地址为i, 或i+1 ,或i+2,或i+3的元素,都将填入i+3这同一个单元,而这四个元素并非同义词。线性探测再散列的优点是:只要哈希表不满,就一定能找到一个不冲突的哈希地址,而二次探测再散列和伪随机探测再散列则不一定。
2. 再哈希法
这种方法是同时构造多个不同的哈希函数:
Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
3. 链地址法
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
例如,已知一组关键字(32,40,36,53,16,46,71,27,42,24,49,64),哈希表长度为13,哈希函数为:H(key)= key % 13,则用链地址法处理冲突的结果如图
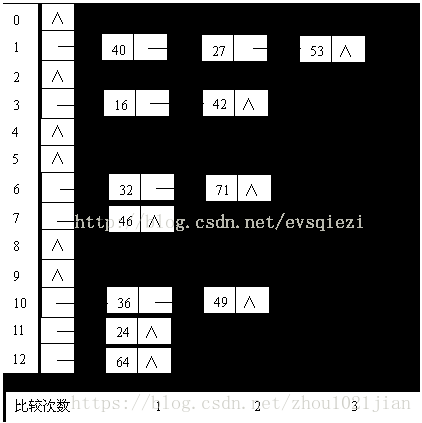
本例的平均查找长度 ASL=(1*7+2*4+3*1)=1.5
4.建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表














 22万+
22万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









