






最近看RNN和LSTM 的工作原理看了很多,也慢慢有了些体会。
先从输入输出介绍(大部分来自知乎)
例如这样一个数据集合,总共100条句子,每个句子20个词,每个词都由一个80维的向量表示。在lstm中,单个样本即单条句子输入下(shape是 [1 , 20, 80]),假如设定每一个time step的输入是一个词(当然这不一定,你也可以调成两个词或者更多个数的词),则在t0时刻是第一个时间步,输入x0则为代表一条句子(一个样本)中第1个词的80维向量,t1是第二个时间步,x1表示该句子中第2个词的80维向量,依次类推t19输入是最后一个词即第20个词的向量表示。
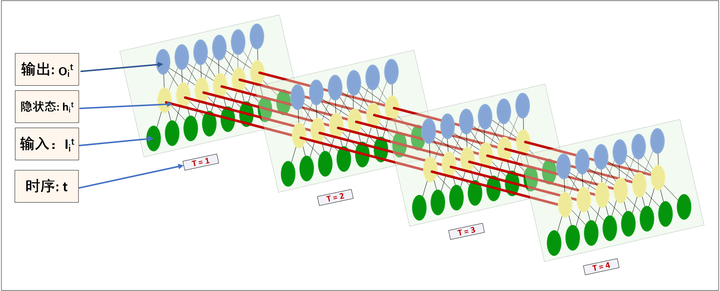
这里应该配上图,这个图就是RNN的一个模型,展示的是一个样例也就是一个句子怎么在模型中计算的
step1, raw text:
接触LSTM模型不久,简单看了一些相关的论文,还没有动手实现过。然而至今仍然想不通LSTM神经网络究竟是怎么工作的。……
step2, tokenize (中文得分词):
sentence1: 接触 LSTM 模型 不久 ,简单 看了 一些 相关的 论文 , 还 没有 动手 实现过 。
sentence2: 然而 至今 仍然 想不通 LSTM 神经网络 究竟是 怎么 工作的。
……
step3, dictionarize:
sentence1: 1 34 21 98 10 23 9 23
sentence2: 17 12 21 12 8 10 13 79 31 44 9 23
……
step4, padding every sentence to fixed length:
sentence1: 1 34 21 98 10 23 9 23 0 0 0 0 0
sentence2: 17 12 21 12 8 10 13 79 31 44 9 23 0
……
step5, mapping token to an embeddings:
sentence1:
![\left[ \begin{array}{ccc} 0.341 & 0.133 & 0.011 &…\\ 0.435 & 0.081 & 0.501 &…\\ 0.013 & 0.958 & 0.121 &…\\ … & … & … &… \end{array} \right ]](https://www.zhihu.com/equation?tex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+0.341+%26+0.133+%26+0.011+%26%E2%80%A6%5C%5C+0.435+%26+0.081+%26+0.501+%26%E2%80%A6%5C%5C+0.013+%26+0.958+%26+0.121+%26%E2%80%A6%5C%5C+%E2%80%A6+%26+%E2%80%A6+%26+%E2%80%A6+%26%E2%80%A6+%5Cend%7Barray%7D+%5Cright+%5D) ,每一列代表一个词向量,词向量维度自行确定;矩阵列数固定为time_step length。
,每一列代表一个词向量,词向量维度自行确定;矩阵列数固定为time_step length。
sentence2:
……
上面的矩阵,一列是一个词的向量表示,一共有句子长度个列
step6, feed into RNNs as input:
假设 一个RNN的time_step 确定为 ,则padded sentence length(step5中矩阵列数)固定为
。一次RNNs的run只处理一条sentence。每个sentence的每个token的embedding对应了每个时序
,则padded sentence length(step5中矩阵列数)固定为
。一次RNNs的run只处理一条sentence。每个sentence的每个token的embedding对应了每个时序
 的输入
的输入
 。一次RNNs的run,连续地将整个sentence处理完。
这里的i是样本的标号,也就是第几个句子,t就是当前时序,比如t=0的时候,i=0,输入的就是第一个句子第一个词的向量,t=1,i=0时,是第一个句子第二个词的向量,t=0,i=1,输入的时第二个句子第一个词的向量
。一次RNNs的run,连续地将整个sentence处理完。
这里的i是样本的标号,也就是第几个句子,t就是当前时序,比如t=0的时候,i=0,输入的就是第一个句子第一个词的向量,t=1,i=0时,是第一个句子第二个词的向量,t=0,i=1,输入的时第二个句子第一个词的向量
接触LSTM模型不久,简单看了一些相关的论文,还没有动手实现过。然而至今仍然想不通LSTM神经网络究竟是怎么工作的。……
step2, tokenize (中文得分词):
sentence1: 接触 LSTM 模型 不久 ,简单 看了 一些 相关的 论文 , 还 没有 动手 实现过 。
sentence2: 然而 至今 仍然 想不通 LSTM 神经网络 究竟是 怎么 工作的。
……
step3, dictionarize:
sentence1: 1 34 21 98 10 23 9 23
sentence2: 17 12 21 12 8 10 13 79 31 44 9 23
……
step4, padding every sentence to fixed length:
sentence1: 1 34 21 98 10 23 9 23 0 0 0 0 0
sentence2: 17 12 21 12 8 10 13 79 31 44 9 23 0
……
step5, mapping token to an embeddings:
sentence1:
sentence2:
……
上面的矩阵,一列是一个词的向量表示,一共有句子长度个列
step6, feed into RNNs as input:
假设 一个RNN的time_step 确定为
所以模型的输入层的维度就是词向量的维度(对一个样例,就是单个句子来说)(这些是我自己的理解,要是不对及时指正啊啊啊)
step7, get output:
看图,每个time_step都是可以输出当前时序 的隐状态
 ;但整体RNN的输出
;但整体RNN的输出
 是在最后一个time_step
是在最后一个time_step
 时获取,才是完整的最终结果。
时获取,才是完整的最终结果。
step8, further processing with the output:
我们可以将output根据分类任务或回归拟合任务的不同,分别进一步处理。比如,传给cross_entropy&softmax进行分类……或者获取每个time_step对应的隐状态 ,做seq2seq 网络……或者搞创新……
step7, get output:
看图,每个time_step都是可以输出当前时序
step8, further processing with the output:
我们可以将output根据分类任务或回归拟合任务的不同,分别进一步处理。比如,传给cross_entropy&softmax进行分类……或者获取每个time_step对应的隐状态
RNN与LSTM的区别
推荐几篇文章
https://blog.csdn.net/wangyangzhizhou/article/details/76651116
博主介绍的很详细,我就是看了这个才明白的















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









