







Hive和HBase是两个不同的大数据存储和处理系统,具有以下差异:
1、数据模型:Hive是基于Hadoop的关系型数据仓库,支持类SQL语言进行数据查询和处理,数据存储在Hadoop分布式文件系统中。HBase是一个分布式的列式NoSQL数据库,以键值对的方式存储数据,可以直接访问数据。
2、适用场景:Hive适用于那些需要对结构化数据进行查询和分析的场景,通常用于批处理分析,可以处理大量的数据。而HBase适用于需要高速查询和随机访问非结构化数据的场景,可以存储和处理大规模的非结构化数据。
3、数据操作:Hive支持基本的数据查询和处理,如聚合、筛选、连接等,但不支持数据的添加、删除或修改。而HBase支持数据的CRUD操作,可以插入、更新、删除或查询数据。
4、性能:由于Hive是基于MapReduce实现的,因此其性能相对较慢,不适用于需要实时数据查询的场景。而HBase可以提供实时的数据访问和查询,并具有高吞吐量和低延迟的特点。
5、数据一致性:由于HBase是基于分布式系统的,因此对于数据的一致性有一定的要求。在写入数据时,数据会被复制到多个节点上,并在后台进行一致性的处理,因此可能存在一定的延迟。而Hive对数据一致性没有要求,可以在批处理分析中满足数据分析的需求。
(一)相同点
1、HBase 和 Hive 都是架构在 Hadoop 之上,用 HDFS 做底层的数据存储,用 MapReduce 做
数据计算
(二)不同点
1、Hive 是建立在 Hadoop 之上为了降低 MapReduce 编程复杂度的 ETL 工具。
HBase 是为了弥补 Hadoop 对实时操作的缺陷
2、Hive 表是纯逻辑表,因为 Hive 的本身并不能做数据存储和计算,而是完全依赖 Hadoop
HBase 是物理表,提供了一张超大的内存 Hash 表来存储索引,方便查询
3、Hive 是数据仓库工具,需要全表扫描,就用 Hive,因为 Hive 是文件存储
HBase 是数据库,需要索引访问,则用 HBase,因为 HBase 是面向列的 NoSQL 数据库
4、Hive 表中存入数据(文件)时不做校验,属于读模式存储系统
HBase 表插入数据时,会和 RDBMS 一样做 Schema 校验,所以属于写模式存储系统
5、Hive 不支持单行记录操作,数据处理依靠 MapReduce,操作延时高
HBase 支持单行记录的 CRUD,并且是实时处理,效率比 Hive 高得多
1.二者区别
hive:
- Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能。
- Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
- hive可以认为是map-reduce的一个包装。hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。
hbase:
- HBase:HBase是Hadoop的数据库,一个分布式、可扩展、大数据的存储。
- hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作
- hbase可以认为是hdfs的一个包装。他的本质是数据存储,是个NoSql数据库;hbase部署于hdfs之上,并且克服了hdfs在随机读写方面的缺点。
2.二者联系
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
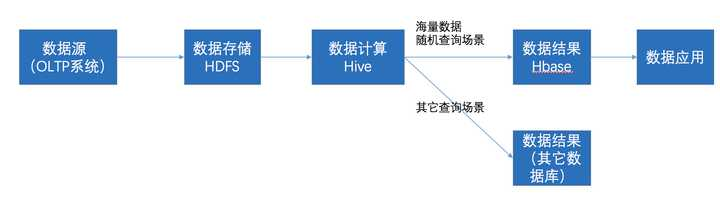
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
通过ETL工具将数据源抽取到HDFS存储;
通过Hive清洗、处理和计算原始数据;
HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
数据应用从HBase查询数据;















 2842
2842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









