







目录
0、Preview
一些 Cache 基本的内容,比如 “为什么需要 Cache”,“Cache 的组织形式”,“Cache 的映射形式”等,我已经在之前的文章《Cache 原理浅析》中叙述得比较清楚了,这里不再赘述,有兴趣的同学可以跳转观看一下,这里主要是补充一些 ARMv7-A 上的一些细节;
1、ARMv7-A Cache Architecture
《Cache 原理浅析》可以知道,Cache Line 是 Cache 的最小单位,为了寻找特定 Cache,在 Cache 结构中,ARM 将地址分为了几段,比如 32bits 的地址总线,ARM 将其分为了 3 段:
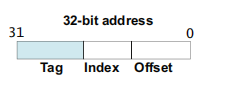
最高的一段叫做 Tag,中间的叫 Index,最后叫 Offset;
在一个多路组相关的 Cache 结构中,它的结构如下:
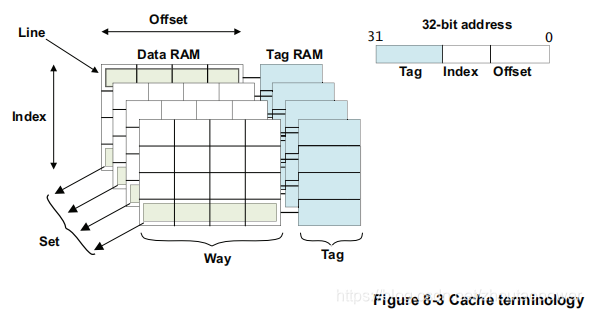
针对这个图,可以做如下理解:
1、这里的 Line,指的是一个 Cache Line,最小的缓存单位,可能很多字节(比如,64 Bytes);
2、可以看到,一个 Way,包含了 N 条 Cache Line(这里包含了 4 条),图中有 4 个 Way,也就是 4-Way associate 的含义;
3、每一个 Way 的同样位置的 4 条 Cache Line 组成一个 Set,具体分为了多少个 Set,这个要看 Cache 总共有多大,这里画了 4 个 Set;
4、因为 Cache 进行数据缓存,并不是按照 一个地址+一个数据(32bits 地址+数据),如果按照这样的结构来缓存,因为这样效率太低;实际上,它缓存的方式是一组一组来缓存,每一组用一个 Tag 进行表征;所以,每个 Cache Line 就有一个 Tag;
5、Index 用于表征一个 Way 中
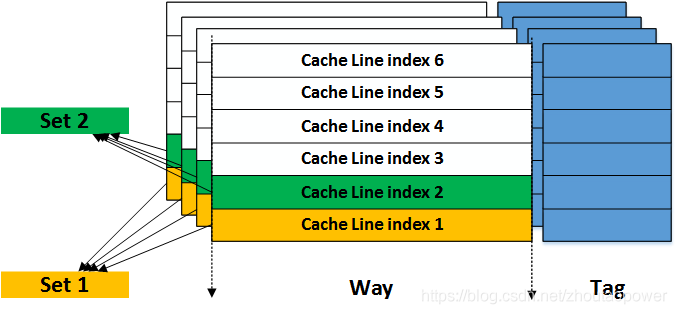
5、每个 Way 中,都对 Cache Line 进行编号,有 Index=1,2,3..n(Index=1表示 Cache Line 的编号即 line1,index=2表示 line2), 我们将在不同 way 中,Index 相同的叫成 set。
上面的结构如果用 C 语言来表示的话:
Way = Cache[tag];
Cache Line = Way[Index];
Data = Cache Line[Offset]
举个真实的例子:
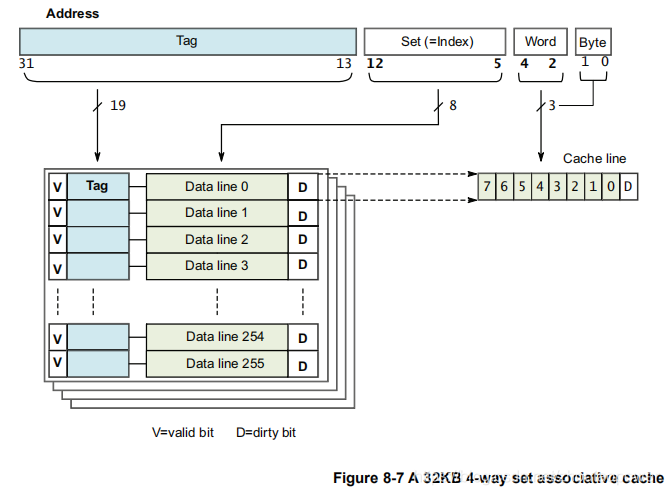
假如我们有一个 Cache Line = 32Bytes,4路 Way 的 组织方式,Cache=32KBytes。
Per Way = (32KBytes / 32KBytes) / 4 Way= 256 Cache Line/Way;
前面说过,一个 Way 中的 Cache Line 是 Index 来索引的,256 个 Cache Line/Way 的话,就要 5 个 bits 来表示;
一个 Cache Line 是 32Bytes,那么就是 8 个 Word,使用 3 个 bits 表示即可;
剩余的高位,作为 Tag 的形式存在:
既然以地址来进行查找 Cache 的,那么我们到底是用虚拟地址还是物理地址呢?三种方式:
1、早期的 ARM 处理器,如 ARM720T 或 ARM926EJ-S 处理器使用虚拟地址提供 Index 和 Tag。 这有一个优点,即 CPU 不需要虚拟到物理地址转换就可以进行缓存查找。 缺点是,每当进行进程切换(虚拟地址映射表发生改变),Cache 中的虚拟地址就不能再用了,导致性能下降,现在这种方式已经淘汰。
2、使用物理地址来查找 Cache(我们叫它 PIPT),那么这么做很明显解决了第一种的缺点(因为是以物理地址进行 Cache 的,不管映射表怎么变,物理地址不会变)。但是由引入了一个缺点:每次进行查表的时候,都需要到MMU去进行地址转换,这样增加了查找cache需要的时间,效率明显没有采用虚拟地址的高。注:这种方法,依赖MMU,即MMU关闭,Cache 就必须关闭;
3、是第 1 种和第 2 种的折中处理,将这个查找过程分为两步,Tag 用物理地址表示,Index 用虚拟地址的,我们叫它 VIPT(Virtually Indexed, Physically Tagged)。那么怎么实现呢?首先,由于 Cache 控制器和 MMU 是两个独立模块,因此通过 MMU 去查找 Tag 和通过 Index 去 Cache 查找 Way 是相互独立的即可以同时运行。即当用 Index 去 Cache 查找 Set(上面有解释,即 Index 相同,但处于不同 Way 的一组集合)的同时也在用虚拟地址去 MMU 找物理地址的 Tag,当从cache找到一组set(line[way])的时候(因为只提供了index,因此cache control不知道到底是哪个way,所以返回每个包含index的way),此时MMU中也查到了物理tag,然后再用该物理tag去匹配返回的set,最后获取到对应的 cache line。常用CPU情况如下。
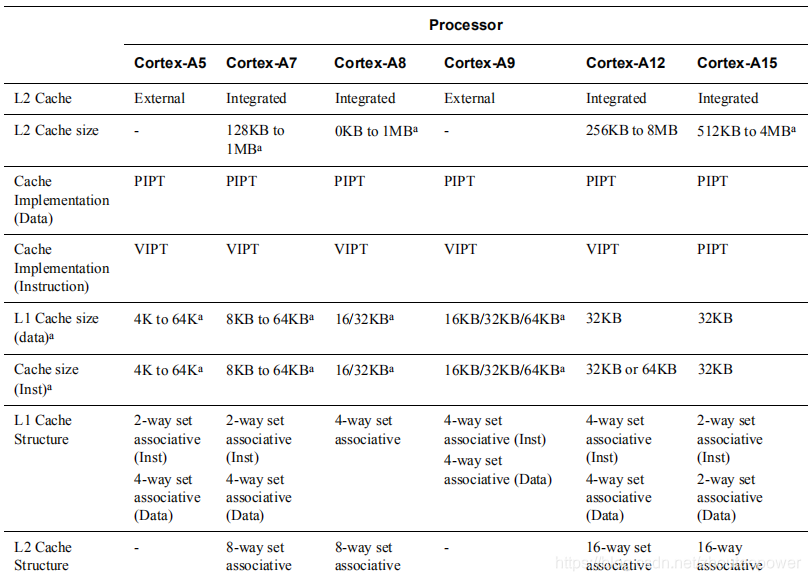
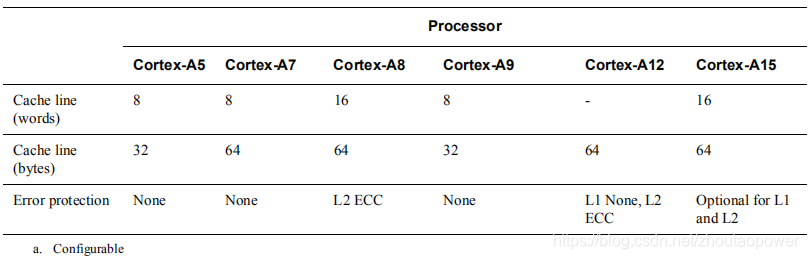
可能到这里有人会问了,混合使用物理地址和虚拟地址不会有问题吗?毕竟虚拟地址在进程发生变动的时候是会不断变化的。不不不,理论上是不会有问题的,为什么呢?我们知道我们的虚拟映射表了,我们的映射表一般是以4K为一个page,即4k对齐,不管虚拟地址怎么发生变化,一个page内的偏移是不变的。要寻址一个4k大小我们需要[11:0]共12个bit来提供支持,即在MMU当中,虚拟地址的低12位和物理地址的低12位是相同的。假如我们用的是一个16kb大小,含有4个way,每个line 32bytes的cache,那么通过计算[4:0]用于cache的offset定位,[11:5]则用于cache的index定位。如上所说,虚拟地址和物理地址的[11:0]是相同的,因此index用虚拟地址就不会有影响。但是话又说回来,如果我们的cache大小超过了16k,加入为32kb呢?那么我们以32KB,含有4个way,每个line 32bytes的cache来说,[4:0]用于offset定位,[12:0]用于index定位,那么问题来了,由于虚拟地址和物理地址仅仅是[11:0]相同,那么第13位在发生切换后,就可能会出现0/1两个值,意味着一个物理地址可能会同时占用2个cache line,即两个副本, 这样就会容易引发cache一致性的问题。针对于这种cache alias问题,目前的方案是由操作系统来保证,对于同一物理地址在不同进程空间的虚拟地址,他们的虚拟地址的差一定是cache way大小的整数倍,也就是说他们的第13位一定是相同的。同时已经有些cpu厂商在开发监视模块,试图在硬件层面解决类似的同步问题。同理对于64kb的cache也采用同样的方法。
2、ARMv7-A Cache policies
在 Cache 操作策略中可以做出许多不同的选择。
2.1、Allocation Policy
第一种,CPU读数据时。只有当读取的时候,发现cache miss,才从cache中申请一个line去缓存该数据。写的时候,不申请,直接写入下一级。
第二种,写和读时。只要访问时,不管读或者写,发生了cache miss都去申请一个cache line。
2.2、Replacement Policy
当 Cache miss 的时候,Cache 替换策略:
第一种,Round-robin 或者循环替换策略;
第二种,Random 替换,Cache 存满并且出现 Cache miss,如果来了一条新的,则随机找一个 Cache Line 被替换;
第三种,LRU(Least Recently Used) 算法替换,方法如名字,当 Cache 存满了后,如果来了一条新的,则选择最近最少使用的被替换;
2.3、Write Policy
第一种,Write-Back 模式:写数据时,只向 Cache写入数据,并标记 Cache 为 Dirty,然后在合适的时机将数据更新到主存;
第二种,Write-Through 模式:写数据时,Cache 和主存都要写一份;
3、ARMv7-A Cache Registers
和 Cache 相关的寄存器控制,首先就是 CP15 的 SCTLR 系统控制寄存器:

bit[2] 是控制 Cache enable 的
bit[12] 是控制指令 Cache enable 的
获取 Cache 的 Type,刷 Cache 等操作寄存器,等在分析 Linux Kernel 的时候,在对着代码解读;
这里需要注意的是,访问 CP15 协处理器的寄存器,通过 MRC/MCR 特殊指令;
参考:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









