







1. 数据源
- item相关信息, tag 相关信息, item与tag历史打标数据
2. 数据分析
- 3k标签占90%的样本
- 选择标签数量样本大于100的标签作为模型的输出,可支持标签数量:1838,业务覆盖率约90%
3. 数据处理
- 脏数据处理:剃掉没有对应类目的标签
- 剃掉出现频次较低的标签(基于标签统计频次)
4. 数据训练格式
- train.csv
text_a : item名称
text_b: 对应类目信息 (text_a, text_b 都加上,增加语义信息的的学习)
label : 标签id, 多个标签id用“/”进行分割。 进入训练阶段,处理为 one-hot形式,长度为label_num
id: itemid
5. 模型选择
网络结构:
-
robert ecoder + dnn + Focal loss
-
loss: Focal loss /ASL
-
Focal loss: 软标签, 忽略易分样本, 加强错分样本的,重点挖掘困难负样本, 当正样本预测概率较高时,则对样本影响越小,当负样本预测概率较小时,对样本影响较小。
-
实际样本集合中,困难样本对应的正样本也很少。

-
ASL:非对称的loss,ASL(Asymmetric Loss)
(1) 将positive samples和negative samples解耦,并赋予它们独立的衰减因子(exponential decay factors)
(2) 通过平移negative samples的概率函数(称 probability shifting),来达到忽略简单negative samples的目的。平移的尺度是一个超参(所以称 hard thresholding)
(3) 达到忽略容易分标签,以及错分标签样本
(4) ASL对CE loss的改装,将正样本损失和负样本损失进行解耦,就体现在将L拆分为 L+ 和 L−。同时,focal loss也可以使用L+ 和 L−来表示。其中, p = σ(z),当γ = 0,focal loss == BCE loss。 当 γ > 0 时,表示简单负样本的权重被降低(对越小的p,pγ 越小,L−越小,L越接近0),loss更倾向于关注困难样本(p比较大的样本)。
(5) 对于focal loss,有一个trade-off:当γ较大时,L+也被抑制了。为此,对focal loss解耦正负样本的衰减因子,得到公式(4):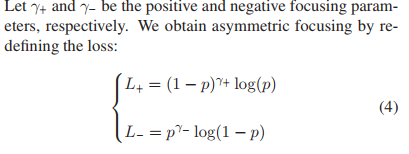 (6) 由于我们更关心正样本的贡献,所以,总是令:γ− > γ+。(注意:ASL的分析,都省略了α,α用于表示正负样本数量的不平衡因子)ASL的概率平移.
(6) 由于我们更关心正样本的贡献,所以,总是令:γ− > γ+。(注意:ASL的分析,都省略了α,α用于表示正负样本数量的不平衡因子)ASL的概率平移.
(7) 在上述的focal loss中,γ的确可以抑制简单负样本,但是它做得不够彻底。ASL对其进行一个概率平移,以彻底忽略简单负样本。
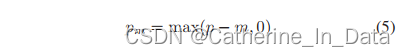
m ≥ 0,是一个超参。把公式(5)作用到L-上,得到:
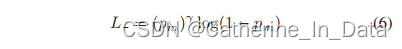
下面是设置 γ- = 2,m = 0.2 时的loss曲线:
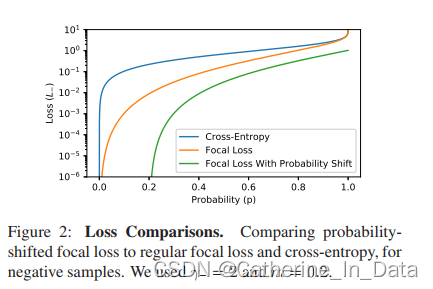
它表示,当p<m,即p<0.2时,L- == 0,由此可见,概率平移完全抑制了简单负样本。 m:论文中也称 asymmetric probability margin。
6. bert 预训练模型
https://github.com/huggingface/transformers
https://github.com/pytorch/fairseq
https://github.com/brightmart/roberta_zh
7. Multi-label开源代码:
https://cloud.tencent.com/developer/article/1449734
https://www.giters.com/isaacueca/Bert-Multi-Label-Text-Classification
https://colab.research.google.com/github/rap12391/transformers_multilabel_toxic/blob/master/toxic_multilabel.ipynb#scrollTo=uDLZmEC_oKo3
https://github.com/javaidnabi31/Multi-Label-Text-classification-Using-BERT/blob/master/multi-label-classification-bert.ipynb
8. 模型效果评估
- 业务关注正确标签是否被召回
- 标签共显示20个,算法侧提供标签相关性的份,人工进行二次标注
- 每个item给到标签中位数为2, 大部分为1-3个,最多6个。
- 不同二分类阈值,对结果准确率影响那个较大。
- 召回接近0.95, 基本上正确标签都可以拉取到。
9. 优化方向:
- 继续探索label样本不均衡问题
- 改进网络结构
- 基于item类目信息,所小标签范围后再预测
- 数据增强
10. 遇到最难的问题:
- label 不平衡
- loss 尝试focal loss,ASL
- 不同频次label权重不一样,增大频次较小label的样本权重














 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









