







Field 类:文档对象中的属性域值,属性域值由三部分构成:名称(name)、类型(type)和值类型(value)。值类型(value)主要分为三大类:一类是文本值类型(text)[(String, Reader or pre-analyzed TokenStream)]、一类是二进制类型(binary)[{byte[]}]、一类是数值类型(numeric)[{ Number}].
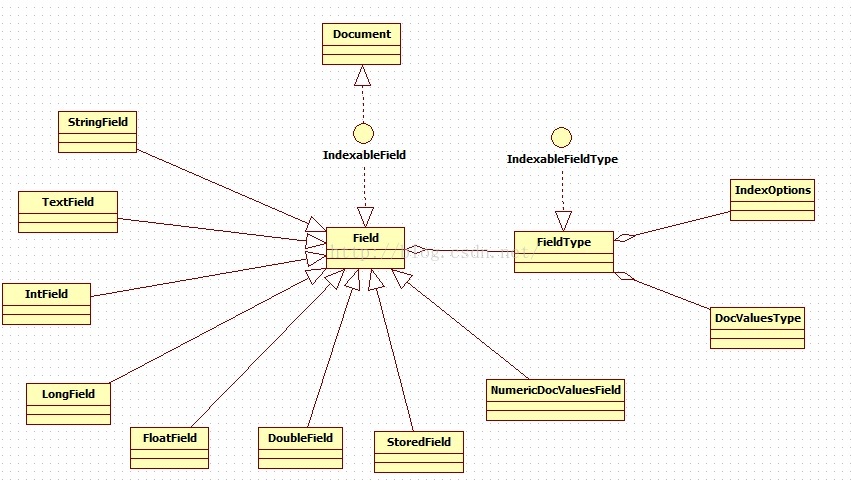
Field 父子关联拓扑图
Field 类构造函数描述
protected Field(String name, FieldType type) :创建一个无初始值的field.
public Field(String name, Reader reader, FieldType type):使用Reader而不是String对象来表示域值。在这种情况下域值不会被存储,并且该域值一直用于分析和索引。具体实现请参考TextField子类。
public Field(String name, TokenStream tokenStream, FieldType type):使用TokenStream而不是String对象来表示域值。在这种情况下域值不会被存储,并且该域值一直用于分析和索引。具体实现请参考TextField子类。
public Field(String name, byte[] value, FieldType type):使用byte[]来表示域值,不能被索引。
public Field(String name, byte[] value, int offset, int length, FieldType type):使用byete[]来表示域值,并且指定起始位置和长度,不能索引。
Field 子类描述
StringField :支持索引但不分词,索引字符串的值,主要适用于"地址值"、"编号值"等其他的取值,主要用于排序和访问字段缓存。
TextField:支持索引和分词,没有term存储。主要适用于“内容”取值。
IntField:支持索引,主要用于范围过滤和排序,通过(NumericRangQuery、SortFiled.Type.Int).
LongField:支持索引,主要用于范围过滤和排序,通过(NumericRangQuery、SortFiled.Type.Long).
FloatField:支持索引,主要用户范围过滤和排序,通过(NumericRangQuery、SortFiled.Type.Float)
DoubleField:支持索引,主要用户范围过滤和排序,通过(NumericRangQuery、SortFiled.Type.Double)
StoredField:域值存储到索引,以便查询的时候进行展示。
NumericDocValueField:每个文档存储一个long值,用于排序和值检索。
FieldType 类相关属性说明:
1.private boolean indexed; 对field是否进行索引操作.
2.private boolean tokenized;是否使用分析器将域值分解成独立的语汇单元流。该属性仅当indexed()为ture时有效.
3.private boolean stored;是否存储field的值。如果true,原始的字符串值全部被保存在索引中,并可以由IndexReader类恢复。该选项对于需要展示搜索结果的一些域很有用(如URL,标题等)。如果为false,则索引中不存储field的值,通常用来索引大的文本域值。如Web页面的正文。
4.private boolean storeTermVectors;当lucene建立起倒排索引后,默认情况下它会保存所有必要的信息实施Vector Space Model。该Model需要计算文档中出现的term数,以及他们出现的位置。该属性仅当indexed为true时生效。他会为field建立一个小型的倒排索引。
5.private boolean storeTermVectorOffsets;表示是否存储field的token character的偏移量到 term vectors向量中。
6.private boolean storeTermVectorPositions;表示是否存储field中token的位置到term vectors 向量中。
7.private boolean storeTermVectorPayloads;是否存储field中token的比重到term vectors中。
8.private boolean omitNorms;是否要忽略field的加权基准值,如果为true可以节省内存消耗,但在打分质量方面会有更高的消耗,另外你也不能使用index-time 进行加权操作。
9.private IndexOptions indexOptions;描述什么可以被记录到倒排索引当中。
DOCS_ONLY:仅documents被索引,term的频率和位置都将被忽略。针对field的短语或有关位置的查询都将抛出异常。
DOCS_AND_FREQS:documents和term的频率被索引,term的位置被忽略。这样可以正常打分,但针对field的短语或有关位置的查询都将抛出异常。
DOCS_AND_FREQS_AND_POSITIONS:这是一个全文检索的默认设置,打分和位置检索都支持。
DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS:索引字符相对位置的偏移量。
10.private DocValuesType docValueType;DocValues 的类型,如果非空,field的值将被索引成docValues.
NUMERIC:数字类型
BINARY:二进制类型
SORTED:只保存不同的二进制值 byte[]
SORTED_SET.
11.private boolean frozen; 阻止field属性未来可能的变更,该属性通常在FieldType 属性已经被设置后调用。是为了防止无意识的变更。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









