






一、前言
业务使用HBase已经有一段时间了,期间也反馈了很多问题,其中反馈最多的是HBase是否支持SQL查询和二级索引,由于HBase在这两块上目前暂不支持,导致业务在使用时无法更好的利用现有的经验来查询HBase。虽然HBase本身不支持SQL,但业界还是有现成的方案来支持,如Hive、Impala、Phoenix等。众多方案各有各的优势,本文主要对Phoenix作一个大概的介绍。
Phoenix中文翻译为凤凰, 其最早是Salesforce的一个开源项目,Salesforce背景是一个搞ERP的,ERP软件一个很大的特点就是数据库操作,所以能搞出一个数据库中间件也是很正常的。而后,Phoenix成为Apache基金的顶级项目。
Phoenix具体是什么呢,其本质是用Java写的基于JDBC API操作HBase的开源SQL引擎。它有如下几个功能特性:
我觉得值得关注的几个特性主要有以下几块:
- 通过JDBC API实现了大部分的java.sql接口,包括元数据API
- DDL支持:通过CREATE TABLE、DROP TABLE及ALTER TABLE来添加/删除
- DML支持:用于逐行插入的UPSERT VALUES,用于相同或不同表之间大量数据传输的UPSERT SELECT,用于删除行的DELETE
- 事务支持:通过客户端的批处理实现的有限的事务支持(beta测试中)
- 二级索引支持:
- 遵循ANSI SQL标准
当前使用Phoenix的公司有很多,如下图所示:
对于我们公司来说,虽然HBase用得多,但用Phoenix的比较少。从自己测试来看,Phoenix确实还存在各种不稳定,如下面描述的几点问题:
- 最新版本对HBase、Hadoop等有严格版本控制,对于已经用上HBase的业务来说要升级HBase版本适配Phoenix代价太大
- 与HBase强相关,作为HBase中的一个组件启动,HBase元数据容易遭到破坏
- 官方提供的创建索引方法,容易导致插入失败,查询失败,程序崩溃等问题
我觉得Phoenix总体思路还是很不错的,但本身太冒进,急于集成新功能,但现有的功能所存在的问题却并未有很好的解决方案,导致版本很多,但没有一个版本能放心在生产环境使用。下面关注一下Phoenix的整体设计思路。
二、Phoenix架构
上面说到,Phoenix是以JDBC驱动方式嵌入到HBase中的,在部署时只有一个包,直接放HBase的lib目录,逻辑构架如下:
从图中可看出,每个RS结点上,都会有一个Phoenix协处理器来处理每个表、每个region的数据,应用端通过Phoneix客户端与HBase客户端打交道,从而实现Sql化访问HBase数据。下面先来说下Coprocessor。
2.1 Coprocessor
HBase的协处理器主要受Google BigTable的影响,具体可参考Dean-Keynote-Ladis2009-page 66-67。 对于HBase来说,引入Coprocessor也是为了提供更好的并行计算能力,而无需依赖于Hadoop的MapReduce。同时,基于Coprocessor,可以更好的实现二级索引、复杂过滤规则、权限访问控制等更接地气的特性。Coprocessor有两种类型,Observer和EndPoint。
前者Observer,类似于RDBMS的触发器,主要作用于RegionServer服务端,通过重载Coprocessor框架的Upcall函数插入用户自己的逻辑,这些逻辑只有在固定的事件发生时才会被触发调用执行,主要有三类hook接口:RegionObserver、WALObserver和MasterObserver。RegionObserver提供了一些数据层操作事件的hook,如Put、Get、Delete和Scan等,在每个操作发生或结束时,会触发调用一些前置的Hook(pre+操作,如preGet)或后置的Hook(post+操作,如postGet);WALObserver提供了WAL相关的Hook;MasterObserver提供了HMaster相关的Hook。
后者EndPoint类似于RDBMS的存储过程,主要作用于客户端,客户端可以调用这些EndPoint执行一段Server端代码,并将Server端代码结果返回给客户端进一步处理,如常见聚合操作,找一张大表某个字段的最大值,如果不用Coprocesser则只能全表扫描,在客户端遍历所有结果找出最大值,且只能利用有限的客户端资源进行迭代计算,无法利用上HBase的并发计算能力;如果用了Coprocessor,则client端可在RegionServer端执行统计每个Region最大值的逻辑,并将Server端结果返回客户端,再找出所有Server端所返回的最大值中的最大值得到最终结果,很明显,这种方式尽量将统计执行下放到Server端,Client端只执行一些最后的聚合,大幅提高了统计效率;还有一个很常见的需求可能就是统计表的行数,其逻辑和上面一样,具体可参考Coprocessor Introduction,在这里就不展开了,后面有机会针对Coprocessor单独展开介绍。
2.2 Phoenix 实现原理
Phoenix的SQL实现原理主要也是基于一系列的Scan操作来完成,Scan是HBase的批量扫描过程。这一系列的Scan操作也是分散到各台RegionServer上通过Coprocessor来完成。主要用到的是RegionObserver,通过RegionObserver在postScannerOpen Hook中将RegionScanner替换成支持聚合操作的定制化Scanner,在真正执行聚合时,会通过自定的Scan属性传递给RegionScanner,在这个Scan中也可加入一些过滤规则,尽量减少返回Client的结果。
2.3 Phoenix 数据模型
Phoenix在数据模型上是将HBase非关系型形式转换成关系型数据模型 ,如下图所示

对于Phoenix来说,HBase的rowkey会被转换成primary key,column family如果不指定则为0否则字段名会带上,qualifier转换成表的字段名,如下是创建一个Phoenix表的例子,以创建表test为例,主键为id即为HBase的rowkey, column family为i, qualifier为name和age。
create table "test" ("id" varchar(20) primary key,"i"."name" varchar(20) ,"i"."age" varchar(20));Phoenix还支持组合primary key,即由多个字段联合组成主键,对于组合主键来说,在HBase底层会把主键的多个字段组合成rowkey显示,其它字段为HBase的qualifier显示。如上面test表,假设id和name为主键,创建表语句又变成:
create table "test" ("id" varchar(20), "name" varchar(20) ,"i"."age" varchar(20),constraint pk PRIMARY KEY("id","name"));这样,假设插入一条数据:如下所示
upsert into "test" values ('1','a','23');在HBase中,rowkey即为"1a", i:age 为 23。这里,可能大家对双引号有点疑问,对于Phoenix来说,加了引号的话,不管是表还是字段名,会变成大小写敏感,不加的话,会统一转换成大写字母。
2.4 Phoenix所支持的语法
目前Phoenix已经支持关系型数据库的大部分语法,如下图所示:

具体语法用法可参考Phoenix官网,写得比较详细。
三、 Phoenix二级索引
我相信,二级索引这个特性应该是大部分用户引入Phoenix主要考虑的因素之一。HBase因其历史原因只支持rowkey索引,当使用rowkey来查询数据时可以很快定位到数据位置。现实中,业务查询需求条件往往比较复杂,带有多个查询字段组合,如果用HBase查的话,只能全表扫描进行过滤,效率很低。而Phoenix支持除rowkey外的其它字段的索引创建,即二级索引,查询效率可大幅提升。
3.1 索引类别
3.1.1 Covered Indexes
从字面上可理解为覆盖索引,什么意思呢,即索引表中就包含你想要的全部字段数据,这样就只需要通过访问索引表而无需访问主表就能得到数据。创建方式如下:
create index my_index on test (v1) include(v2);当执行select v2 from test where v1='...'时,就只会查找索引表数据,不会去主表扫描。
3.1.2 Global Indexes
全局索引适用于读多写少的场景。全局索引在写数据时会消耗大量资源,所有对数据的增删改操作都会更新索引表,而索引表是分布在各个结点上的,性能会受到影响。好处就是,在读多的场景下如果查询的字段用到索引,效率会很快,因为可以很快定位到数据所在具体结点region上,对于写性能就很慢了,因为每写一次,需要更新所有结点上的索引表数据。创建方式如下:
create index my_index on test (v1);如果执行`select v2 from test where v1='...', 实际是用不上索引的,因为v2不在索引字段中,对于全局索引来说,如果查询的字段不包含在索引表中,则还是会去全表扫描主表。
3.1.3 Local Indexes
局部索引适用于写多读少场景,和全局索引类似,Phoenix会在查询时自动选择是否使用索引。如果定义为局部索引,索引表数据和主表数据会放在同一regionserver上,避免写操作时跨节点写索引表带来的额外开销(如Global Indexes)。当使用局部索引查询时,即使查询字段不是索引字段,索引表也会正常使用,这和Global Indexes是有区别的。在4.8版本之前,所有局部索引数据存放在一个单独的共享表中,4.8之后是存储在主表的一个独立的列族中。因为是局部索引,所以在client端查询使用索引时,需要扫描每个结点上的索引表以得到数据所在具体region位置,当region多时,查询时耗会很高,所以查询性能比较低,适合读少写多场景。创建局部索引方式:
create local index my_index on test (v1);3.2 Mutable Indexing 和Immutable Indexing
3.2.1 IMMutable Indexing
不可变索引主要创建在不可变表上,适用于数据只写一次不会有Update等操作,在什么场景下会用到不可变索引呢,很经典的时序数据:write once read many times。在这种场景下,所有索引数据(primary和index)要么全部写成功,要么一个失败全都失败返回错误给客户端。不可变索引用到场景比较少,下面是创建不可变索引的方式:
create table test (pk VARCHAR primary key,v1 VARCHAR, v2 VARCHAR) IMMUTABLE_ROWS=true;即在创建表时指定IMMUTABLE_ROWS参数为true,默认这个参数为false。如果想把不可变索引改为可变索引,可用alter修改:
alter table test set IMMUTABLE_ROWS=false;3.2.2 Mutable Indexing
可变索引意思是在修改数据如Insert、Update或Delete数据时会同时更新索引。这里的索引更新涉及WAL,即主表数据更新时,会把索引数据也同步更新到WAL,只有当WAL同步到磁盘时才会去更新实际的primary/index数据,以保证当中间任何一个环节异常时可通过WAL来恢复主表和索引表数据。
四、性能
在官网,有作一个性能测试,主要是将Phoenix和Hive、Impala作一个对比。
先来看下和Hive的性能对比,测试基准如下:
select count(1) from table over 10M and 100M rows. Data is 5 narrow columns. Number of Region Servers: 4 (HBase heap: 10GB, Processor: 6 cores @ 3.3GHz Xeon)
测试结果:
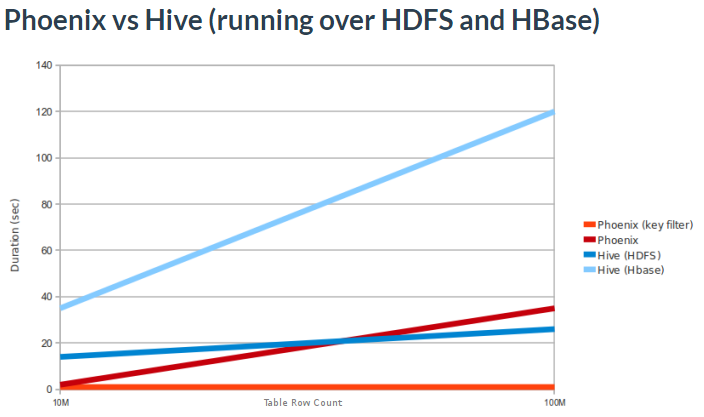
从图中可看出,带有Key过滤的Phoenix耗时最少,不带Key过滤的Phoenix和基于HDFS的Hive性能差不多,直接基于HBase的Hive性能最差。
再来看下和Impala的对比,测试基准如下:
select count(1) from table over 1M and 5M rows. Data is 3 narrow columns. Number of Region Server: 1 (Virtual Machine, HBase heap: 2GB, Processor: 2 cores @ 3.3GHz Xeon)测试结果:
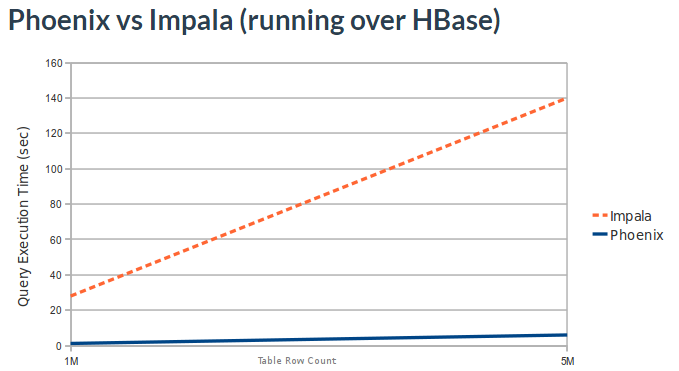
从图中可看出,Impala执行时间比Phoenix长很多,原因大概有几点:Impala基于内存进行并行计算,容易内存吃紧,对HBase和HDFS的支持也还远远不够,性能比较差。
我在自己的HBase测试集群也作了下测试,主要测试数据插入和一些SQL操作的查询时耗。测试集群如下:
先来测试下插入100万记录的测试基准,如下所示:
- 1.创建基本表,表主键由4个字段组成,HOST字段称为
First PK,DOMAIN为Second PK, 依此类推,SPLIT ON指定8个分区。
CREATE TABLE IF NOT EXISTS %s (HOST CHAR(2) NOT NULL,
DOMAIN VARCHAR NOT NULL,
FEATURE VARCHAR NOT NULL,
DATE DATE NOT NULL,
USAGE.CORE BIGINT,
USAGE.DB BIGINT,
STATS.ACTIVE_VISITOR INTEGER
CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE))
SPLIT ON ('CSGoogle','CSSalesforce','EUApple','EUGoogle','EUSalesforce','NAApple','NAGoogle','NASalesforce')
- 2.插入100万行记录
- 3.执行如下查询条件测试
Query # 1 - Count - SELECT COUNT(1) FROM PERFORMANCE_1000000;
Query # 2 - Group By First PK - SELECT HOST FROM PERFORMANCE_1000000 GROUP BY HOST;
Query # 3 - Group By Second PK - SELECT DOMAIN FROM PERFORMANCE_1000000 GROUP BY DOMAIN;
Query # 4 - Truncate + Group By - SELECT TRUNC(DATE,'DAY') DAY FROM PERFORMANCE_1000000 GROUP BY TRUNC(DATE,'DAY');
Query # 5 - Filter + Count - SELECT COUNT(1) FROM PERFORMANCE_1000000 WHERE CORE<10;测试结果如下:
- 插入100万条记录耗时70s
- Query #1 耗时1.032s
- Query #2 耗时0.025s
- Query #3 耗时0.615s
- Query #4 耗时0.608s
- Query #5 耗时1.026s
具体结果如下:
csv columns from database.
CSV Upsert complete. 1000000 rows upserted
Time: 69.672 sec(s)
COUNT(1)
----------------------------------------
1000000
Time: 1.032 sec(s)
HO
--
CS
EU
NA
Time: 0.025 sec(s)
DOMAIN
----------------------------------------
Apple.com
Google.com
Salesforce.com
Time: 0.615 sec(s)
DAY
-----------------------
2018-01-28 00:00:00.000
2018-01-29 00:00:00.000
2018-01-30 00:00:00.000
2018-01-31 00:00:00.000
2018-02-01 00:00:00.000
2018-02-02 00:00:00.000
2018-02-03 00:00:00.000
2018-02-04 00:00:00.000
2018-02-05 00:00:00.000
2018-02-06 00:00:00.000
2018-02-07 00:00:00.000
2018-02-08 00:00:00.000
2018-02-09 00:00:00.000
Time: 0.608 sec(s)
COUNT(1)
----------------------------------------
20209
Time: 1.026 sec(s)还作了下三种不同数量级下的性能对比,作了5种SQL查询操作对比,如上测试基准第3条所描述的查询条件,结果如下:

从结果看,随着数量级的增加,查询时耗也随之增加,有一个例外,就是当用First PK索引字段作聚合查询时,用时相差不大。总的来说,Phoenix在用到索引时查询性能会比较好。那对于Count来说,如果不用Phoenix,用HBase自带的Count耗时是怎样的呢,测了一下,HBase Count 100万需要33s, 500万需要139s,1000万需要284s,性能还是很差的。对于大表来说基本不能用Count来统计行数,还得依赖于基于Coprocessor机制来统计。
从上面测试来看下,Phoenix的性能不能说最好,也存在各种问题,就如开篇说的,版本不稳定,BUG过多,容易影响集群稳定性。
五、总结
总的来说,目前并没有一种很完美的方案来解决SQL查询、二级索引问题,都或多或少存在各种问题。不过HBase的Coprocessor是个好东西,很多功能可以基于此特性进行二次开发,后续可以深入研究一下。
六、参考
[1] https://community.hortonworks.com/articles/61705/art-of-phoenix-secondary-indexes.html
[2] https://github.com/forcedotcom/phoenix/wiki/Secondary-Indexing














 7472
7472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









