






内存对齐原理
原理
关于C结构体的存储中,存在关于内存对齐的机制,下面以一个结构体为例,说明内存对齐的原理。
struct S1{
int a;
unsigned char b;
long c;
int d;
char e;
char f;
char* g;
};
struct S1 s1;
s1.a = 0x01;
s1.b = 0x02;
s1.c = 0x1000;
s1.d = 0x10;
s1.e = 0x04;
s1.f = 0x08;
s1.g = NULL;
该结构体在内存中的存储方式如下:
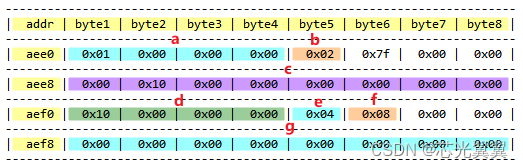
结构体成员a的地址为0xaee0 ~ 0xaee3,共占4个字节。
成员b的地址为0xaee4,共占1个字节。但紧随其后的3个字节是不可被使用的。
成员c的地址为0xaee8 ~ 0xaeef,共占8个字节。
成员d的地址为0xaf0 ~ 0xaf3,共占4个字节。
成员e的地址为0xaf4,占1个字节。
成员f的地址为0xaf5,占1个字节。但紧随其后的2个字节是不可使用的。
成员g的地址为0xaf8 ~ 0xaff,共占8个字节。
默认情况下的对齐方式是按结构体成员的类型中最长的那个作为基准。如在上述struct S1结构体中,最长的类型就是long和char*,占8个字节。因此其它所有成员都得按8个字节对齐。但它又不是强行将每一个成员都扩充至8个字节长度,而是扩充与压缩多措并举。首先将成员a扩充至8字节,但因int类型仅需4个字节即可,剩余的4个字节不应被浪费,而它后面的成员b所需要的字节数又少于多出的字节数,因此成员b就可以紧随a之后存储数据。如上图所示。在处理好成员a和成员b后仍有3个字节被空闲,但之后的成员c所需的字节数大于剩余的空间,无法合并,故而重新开僻一个8字节空间用于存储成员c。剩下的成员也依此类推。
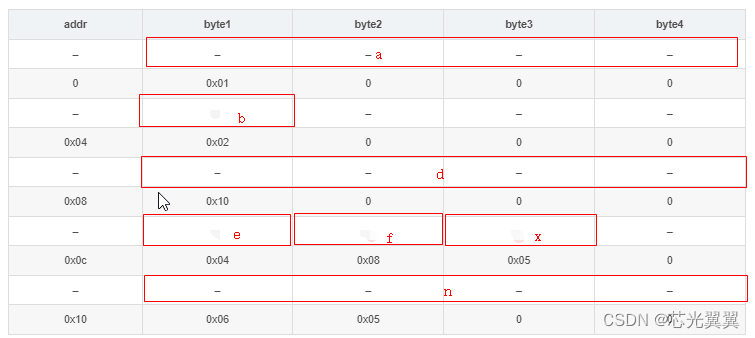
示例
struct S1{
int a;
unsigned char b;
int d;
char e;
char f;
char x;
int n;
};
s1.a = 0x01;
s1.b = 0x02;
s1.d = 0x10;
s1.e = 0x04;
s1.f = 0x08;
s1.x = 0x05;
s1.n = 0x0506;
修改内存对齐的方式
linux默认就是按最长类型作为对齐基准字节数,但我们可以通过关键字"#pragma param(*)"来修改。若我们将对齐字节数修改为1,则结构体在内存中就是普通类型变量的组合,该是多少字节就是多少字节。
#pragma pack() //动态调整,以成员类型最长的字节作为基准数
#pragma pack(1) //以1字节作为对齐基准数。即不对齐。
#pragma pack(4) //以4字节作为对齐基准数。















 1208
1208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









