










欢迎关注《汽车软件技术》公众号,回复关键字获取资料。
1. 简介
粒子滤波是一种滤波算法。
基本原理:随机选取预测域的 N N N 个点,称为粒子。以此计算出预测值,并算出在测量域的概率,即权重,加权平均就是最优估计。之后按权重比例,重采样,进行下次迭代。
此算法存在的问题是:粒子数量越多,计算越精确,但计算量也会增加,且随着迭代,有些粒子权重变得很小,导致粒子枯竭。
| 滤波算法 | 适用范围 |
|---|---|
| 卡尔曼滤波 | 线性高斯分布 |
| 粒子滤波 | 非线性,非高斯分布 |
2. 概念
生成一系列 x t x_t xt 的假设,保留概率最大的,传播到 x t + 1 x_{t+1} xt+1。保留最大概率 x t + 1 x_{t+1} xt+1,传播到 x t + 2 x_{t+2} xt+2,依此类推。
3. 算法
3.1 初始化
在预测值空间内随机选取 N N N 个粒子 x 1 i x_1^i x1i,并分配权重 w i w_i wi: x 1 i ∼ p ( x 1 ) x_1^i\sim{p}(x_1) x1i∼p(x1), w i = 1 N w_i=\frac1{N} wi=N1,式中 i = 1 , . . . , N i=1,...,N i=1,...,N。
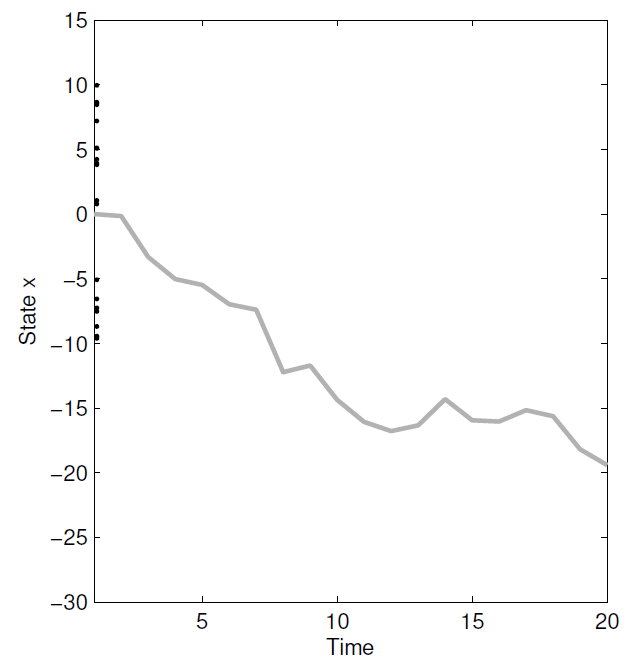
3.2 迭代
按照以下顺序,循环执行, t = 1 , . . . , T t=1,...,T t=1,...,T。
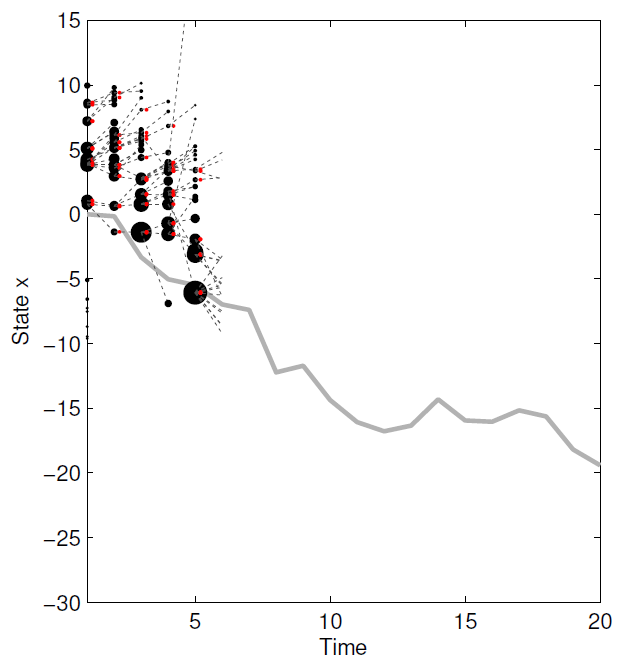
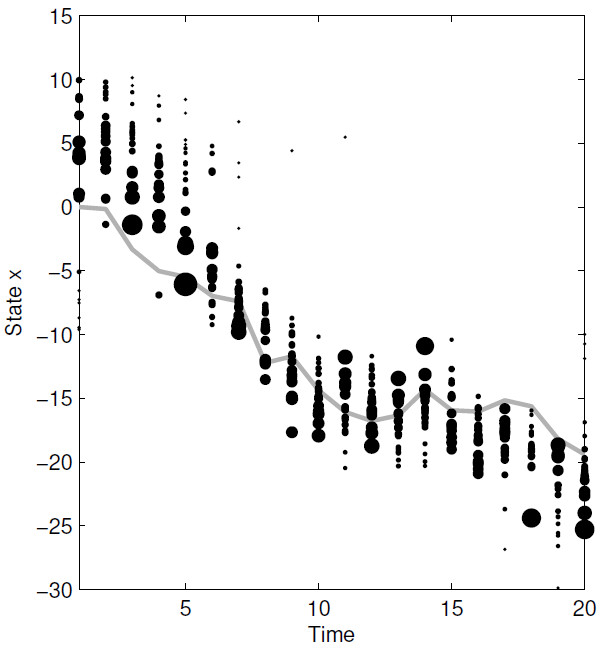
1.估算每个粒子的权重 w t i = g ( y t ∣ x t i , u t ) w_t^i=g(y_t|x_t^i,u_t) wti=g(yt∣xti,ut)。下图黑色圆点面积越大,权重越大。
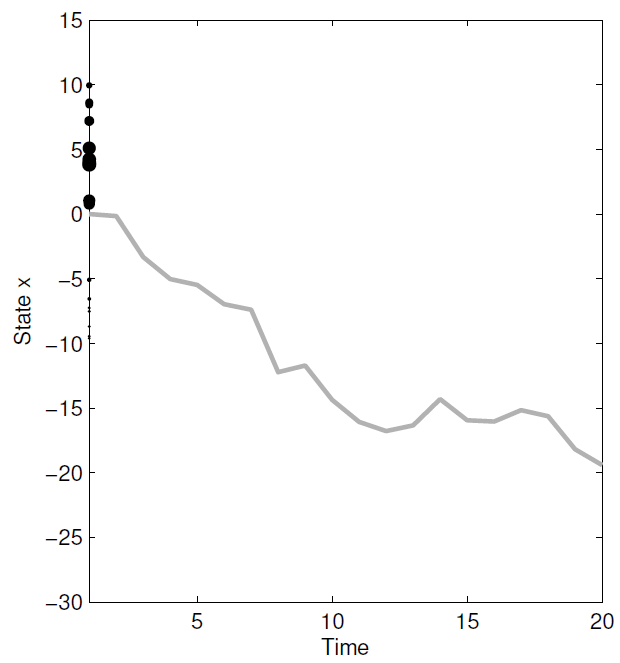
2.计算估计值
加权求平均。
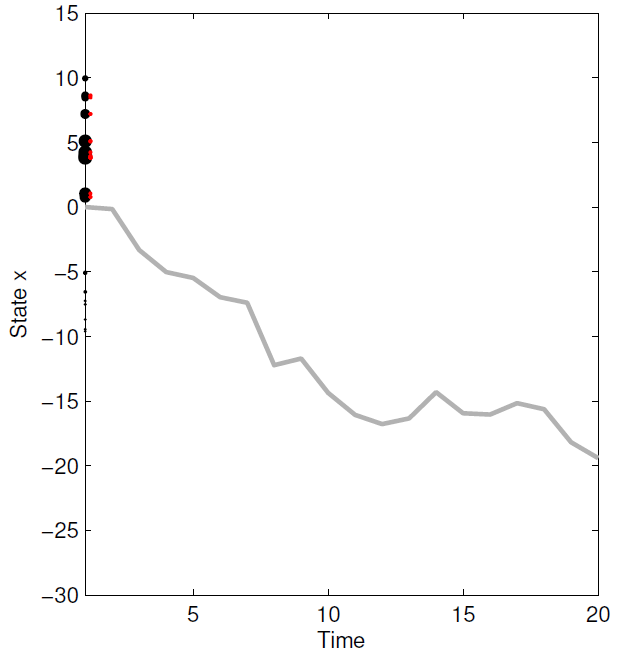
3.从 { x t i , w t i } i = 1 N \{x_t^i,w_t^i\}_{i=1}^N {xti,wti}i=1N 重采样 { x t i } i = 1 N \{x_t^i\}_{i=1}^N {xti}i=1N。下图红色圆点是新粒子。
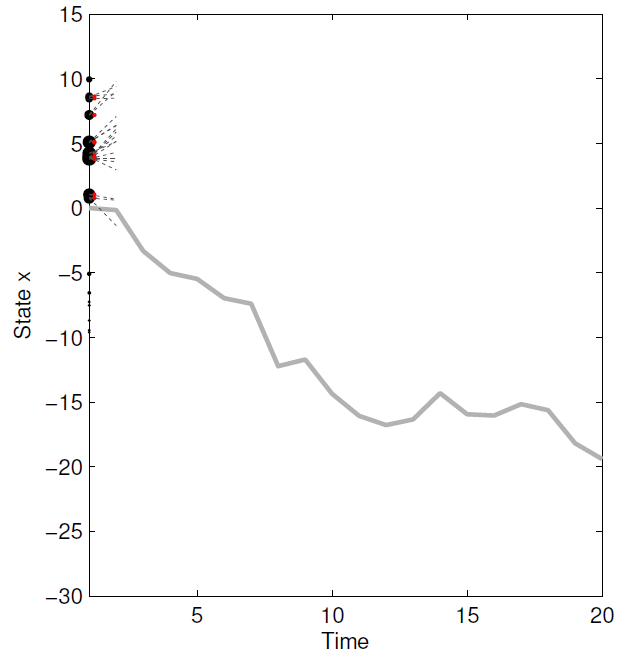
4.通过采样 f ( ⋅ ∣ x t − 1 i , u t − 1 ) f(\cdot|x_{t-1}^i,u_{t-1}) f(⋅∣xt−1i,ut−1) 传播 x t i x_t^i xti。
3.2.1 代码
用Matlab代码描述如下
X(:,1) = random(i_dist,N,1);
w(:.1) = ones(N,1)/N;
for t =1:T
w(:,t) = pdf(m_dist,y(t)-g(x(:,t));
w(:,t) = w(:,t)/sum(w(:,t));
Resample x(:,t)
x(:,t+1) = f(x(:,t),u(t))+random(t_dist,N,1);
end
3.2.2 结果
在 t = 5 t=5 t=5 时刻:
最终输出:
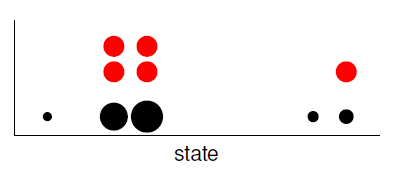
3.3 重采样(resampling)
- 使用 N N N 个红色相同大小的点表示 N N N 个不同大小的黑色点。黑色表示上次计算的权重,红色表示下次采样的点。从图中可以看出,当权重越高时,下次被选中的概率更高。
Matlab代码如下:
v = rand(N,1);
wc = cumsum(w(:,t);
[ ,ind1] = sort([v:wc]);
ind = find(ind1<=N)-(0:N-1)';
x(:,t)=x(ind,t);
w(:,t)=ones(N,1)./N;
3.4 权重
通过前期的测量,可以得到一个pdf(probability density function,概率密度函数),用于权重计算。权重计算:
w t i ∝ w t − 1 i p ( y t ∣ x t i ) p ( x k i ∣ x t − 1 i ) q ( x t i ∣ x t − 1 i , y i ) w_t^i\varpropto{w}_{t-1}^i\frac{p(y_t|x_t^i)p(x_k^i|x_{t-1}^i)}{q(x_t^i|x_{t-1}^i,y_i)} wti∝wt−1iq(xti∣xt−1i,yi)p(yt∣xti)p(xki∣xt−1i)
4. 计算复杂度
理论上,粒子滤波计算复杂度是 O ( N T n x 2 ) \mathcal{O}(NTn_x^2) O(NTnx2),其中 N N N 是粒子数量, T T T 是迭代次数, n x n_x nx 是状态数量。而卡尔曼滤波是 O ( T n x 3 ) \mathcal{O}(Tn_x^3) O(Tnx3)。
5. 例子
状态方程如下:
x k = x k − 1 2 + 25 x k − 1 1 + x k − 1 2 + 8 cos ( 1.2 ( k − 1 ) ) + v k x_k=\frac{x_{k-1}}{2}+\frac{25x_{k-1}}{1+x_{k-1}^2}+8\cos(1.2(k-1))+v_k xk=2xk−1+1+xk−1225xk−1+8cos(1.2(k−1))+vk
y k = x k 2 20 + n k y_k=\frac{x_k^2}{20}+n_k yk=20xk2+nk
使用python实现:
import numpy as np
import matplotlib.pyplot as plt
def estimate(particles, weights):
"""returns mean and variance of the weighted particles"""
mean = np.average(particles, weights=weights)
var = np.average((particles - mean) ** 2, weights=weights)
return mean, var
def simple_resample(particles, weights):
N = len(particles)
cumulative_sum = np.cumsum(weights)
cumulative_sum[-1] = 1. # avoid round-off error
rn = np.random.rand(N)
indexes = np.searchsorted(cumulative_sum, rn)
# resample according to indexes
particles[:] = particles[indexes]
weights.fill(1.0 / N)
return particles, weights
x = 0.1 # 初始真实状态
x_N = 1 # 系统过程噪声的协方差(由于是一维的,这里就是方差)
x_R = 1 # 测量的协方差
T = 75 # 共进行75次
N = 100 # 粒子数,越大效果越好,计算量也越大
V = 2 # 初始分布的方差
x_P = x + np.random.randn(N) * np.sqrt(V)
x_P_out = [x_P]
# plt.hist(x_P,N, normed=True)
z_out = [x ** 2 / 20 + np.random.randn(1) * np.sqrt(x_R)] # 实际测量值
x_out = [x] # 测量值的输出向量
x_est = x # 估计值
x_est_out = [x_est]
# print(x_out)
for t in range(1, T):
x = 0.5 * x + 25 * x / (1 + x ** 2) + 8 * np.cos(1.2 * (t - 1)) + np.random.randn() * np.sqrt(x_N)
z = x ** 2 / 20 + np.random.randn() * np.sqrt(x_R)
# 更新粒子
# 从先验p(x(k) | x(k - 1))中采样
x_P_update = 0.5 * x_P + 25 * x_P / (1 + x_P ** 2) + 8 * np.cos(1.2 * (t - 1)) + np.random.randn(N) * np.sqrt(x_N)
z_update = x_P_update ** 2 / 20
# 计算权重
P_w = (1 / np.sqrt(2 * np.pi * x_R)) * np.exp(-(z - z_update) ** 2 / (2 * x_R))
P_w /= np.sum(P_w)
# 估计
x_est, var = estimate(x_P_update, P_w)
# 重采样
x_P, P_w = simple_resample(x_P_update, P_w)
# 保存数据
x_out.append(x)
z_out.append(z)
x_est_out.append(x_est)
x_P_out.append(x_P)
# 显示粒子轨迹、真实值、估计值
t = np.arange(0, T)
x_P_out = np.asarray(x_P_out)
for i in range(0, N):
plt.plot(t, x_P_out[:, i], color='gray')
plt.plot(t, x_out, color='lime', linewidth=2, label='true value')
plt.plot(t, x_est_out, color='red', linewidth=2, label='estimate value')
plt.legend()
plt.show()
显示真实值、估计值和粒子轨迹:

6. 附录
6.1 中英文对照表
| 英文 | 中文 |
|---|---|
| Particle Filter | 例子滤波 |
| Probability Density Function | 概率密度函数 |
| Resample | 重采样 |
| State Space | 状态空间 |














 9437
9437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









