







 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
1.1 计算机视觉概念
1.1.1 什么是计算机视觉
- 定义:计算机视觉(Computer vision)是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等,用计算机处理成为更适合人眼观察或传送给仪器检测的图像。
比如下图,做到的不仅仅是检测到图像前景中有四个人、一条街道和几辆车。除了这些基本信息,人类还能够看出图像前景中的人正在走路,其中一人赤脚,我们甚至知道他们是谁。我们可以理性地推断出图中人物没有被车撞击的危险,白色的大众汽车没有停好。人类还可以描述图中人物的穿着,不止是衣服颜色,还有材质与纹理。人类能够理解和描述图像中的场景。

披头士专辑《艾比路》的封面
区分计算机视觉与其相关领域
计算机视觉,图像处理,图像分析,机器人视觉和机器视觉是彼此紧密关联的学科。计算机视觉的研究很大程度上针对图像的内容。如果你翻开带有上面这些名字的教材,你会发现在技术和应用领域上他们都有着相当大部分的重叠。这表明这些学科的基础理论大致是相同的,甚至让人怀疑他们是同一学科被冠以不同的名称。然而,各研究机构,学术期刊,会议及公司往往把自己特别的归为其中某一个领域,于是各种各样的用来区分这些学科的特征便被提了出来。下面将给出一种区分方法,尽管并不能说这一区分方法完全准确。
- 图像处理
图像处理旨在处理原始图像以应用某种变换。其目标通常是改进图像或将其作为某项特定任务的输入,而计算机视觉的目标是描述和解释图像。例如,降噪、对比度或旋转操作这些典型的图像处理组件可以在像素层面执行,无需对图像整体具备全面的了解。
- 机器视觉
主要是指工业领域的视觉研究,例如自主机器人的视觉,用于检测和测量的视觉。这表明在这一领域通过软件硬件,图像感知与控制理论往往与图像处理得到紧密结合来实现高效的机器人控制或各种实时操作。
1.1.2 计算机视觉公司以及领域分析
为什么学习计算机视觉
- 1、市场大
人类有 70-80% 的信息来源于视觉。相比语音场景的单一,CV 可以做的事情更多。计算机视觉在这不到一年的时间里已经遍地开花,地铁的安防摄像头、火车站飞机场的人脸识别闸机、智能手机的人脸识别解锁与支付功能……不知不觉中,计算机视觉技术“渗透”到了人们生活的方方面面。
- 2、创业公司、资本多
2017 年称得上中国“独角兽”企业的公司已达 164 家,这其中包括了 7 家人工智能企业,而计算机视觉企业就在其中占了四个名额,他们分别是:旷视科技、商汤科技、云从科技与依图科技。计算机视觉在这一年获得超过 230 亿元的投资,在中国人工智能领域的投资当中占比超过三分之一。
计算机视觉应用被越来越多的公司部署,用于回答业务问题或提升产品性能。它们或许已经成为人们日常生活的一部分,你甚至都没有注意到它。
1.1.2.1 计算机视觉公司
国内做的好的公司
1、旷视科技北京旷视科技有限公司成立于2012年11月,公司专注于人脸识别技术和相关产品应用研究,面向开发者提供服务,能提供一整套人脸检测、人脸识别、人脸分析以及人脸3D技术的视觉技术服务,主要通过提供云端API、离线SDK、以及面向用户的自主研发产品形式,将人脸识别技术广泛应用到互联网及移动应用场景中。
旷视的核心 AI 技术应用早已拓展到了手机行业,基于核心的深度学习和计算机视觉技术推出人脸支付、人脸识别解锁、人像光效、人像背景虚化、视频美化、3D Animoji 等一系列移动端 AI 产品,以满足不同手机厂商在人脸解锁、图像增强、相机增强、智能图像和视频处理上的需求,在不到一年的时间内已经与华为、小米、vivo、OPPO 等国内头部手机企业实现深度合作。
2、Sense Time商汤科技商汤集团是一家科技创新公司,致力于引领人工智能核心“深度学习”技术突破,构建人工智能、大数据分析行业解决方案。在人工智能产业兴起的大背景下,商汤集团凭借在技术、人才、专利上超过十年的积累,迅速成为了人工智能行业领军企业之一。商汤科技已与国内外 700 多家公司和机构建立合作,涵盖智慧城市、智能手机、互动娱乐及广告、汽车、金融、零售、教育、医疗、地产等多个行业。
其它每个领域的代表公司:
智能驾驶:佑驾创新、驭势科技、格林深瞳、图森未来;
智能安防:商汤科技、格灵深瞳、旷视科技、速感科技、阅面科技、依图科技、极视角;
智能医疗:商汤科技、依图科技;
智能家居:速感科技、依图科技;智慧金融:格灵深瞳、旷视科技、商汤科技、依图科技;
智能硬件:云天励飞、速感科技、阅面科技、依图科技
智慧商业:商汤科技、极视角、旷视科技、码隆科技、图普科技、云天励飞
娱乐:旷视科技、图漾信息、图普科技
计算机视觉领域尤其复杂,它拥有大量的实际应用。从电商到传统行业,各种类型和规模的公司现在都可以利用计算机视觉的强大能力,这是依赖于人工智能和机器学习(更具体地说是计算机视觉)的创新所带来的利好。
1.1.2.2 应用方向
国内人工智能产业中的计算机视觉领域的公司数量已达 300多家。涵盖各个领域、场景。下面我们就来看看,计算机视觉影响的典型场景。
- 目前 CV 公司比较集中的技术赛道有:人脸识别、自动驾驶、医疗图像等,但目前而言,商业化落地最快的还是人脸识别及其业务相关的一些技术,比如银行会用到人脸和自然场景下的 OCR(文字识别),还有浸入式大数据风控,安防会用到人脸、人体、车辆与大数据分析等。
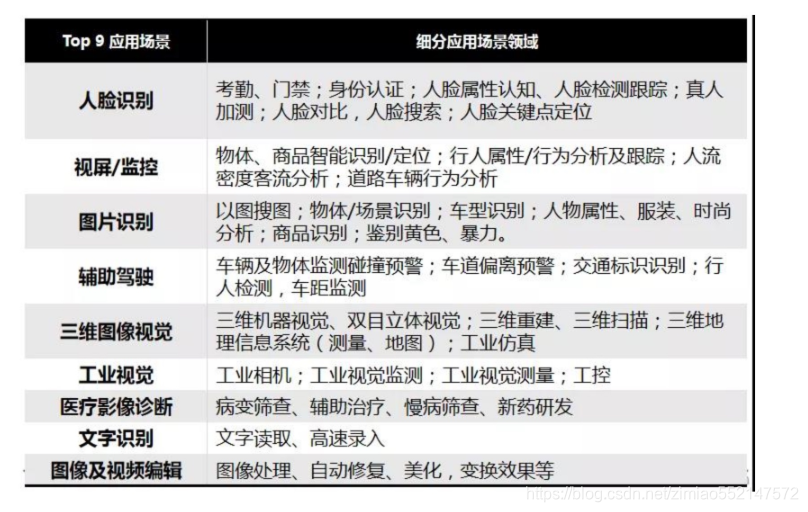
注:计算机视觉还在很多如互联网领域、手机行业都会有应用场景,识别与认证、AI 摄影、3D 视觉、视频处理。
1、行为追踪
实体零售店利用计算机视觉算法和摄像头,了解顾客及其行为。计算机视觉算法能够识别人脸,确定人物特征,如性别或年龄范围。此外,零售店还可以利用计算机视觉技术追踪顾客在店内的移动轨迹,分析其移动路线,检测行走模式,并统计零售店店面受到行人注意的次数。

添加视线方向检测后,零售店能够回答这一重要问题:将店内商品放在哪个位置可以提升消费者体验,最大化销售额。计算机视觉还是开发防盗窃机制的强大工具。人脸识别算法可用于识别已知的商店扒手,或检测出某位顾客将商品放入自己的背包。
2、医疗行业
在医疗行业中,现有计算机视觉应用的数量非常庞大。毫无疑问,医疗图像分析是最著名的例子,它可以显著提升医疗诊断流程。此类系统对 MRI 图像、CT 扫描图像和 X 光图像进行分析,找出肿瘤等异常,或者搜索神经系统疾病的症状。在很多情况下,图像分析技术从图像中提取特征,从而训练能够检测异常的分类器。但是,一些特定应用需要更细化的图像处理。
例如,对结肠镜检查图像进行分析时,分割图像是必要的,这样才能找出肠息肉,防止结直肠癌。
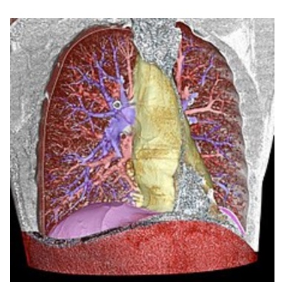
胸腔 3D 渲染 CT 扫描图像的体分割。(图源:https://en.wikipedia.org/wiki/Image_segmentation)
上图是观察胸腔元素所需的图像分割结果。该系统分割每个重要部分并着色:肺动脉(蓝色)、肺静脉(红色)、纵膈(黄色)和横膈(紫色)。目前大量此类应用已经投入使用,如估计产后出血量、量化冠状动脉钙化情况、在没有 MRI 的情况下测定人体内的血流量。
但是,医疗图像并非计算机视觉在医疗行业中唯一的用武之地。比如,计算机视觉技术为视障人士提供室内导航帮助。这些系统可以在楼层平面图中定位行人和周围事物等,以便实时提供视觉体验。视线追踪和眼部分析可用于检测早期认知障碍,如儿童自闭症或阅读障碍,这些疾病与异常注视行为高度相关。
4、自动驾驶
你是否思考过,自动驾驶汽车如何「看」路?计算机视觉在其中扮演核心角色,它帮助自动驾驶汽车感知和了解周围环境,进而恰当运行。计算机视觉最令人兴奋的挑战之一是图像和视频目标检测。这包括对不同数量的对象进行定位和分类,以便区分某个对象是交通信号灯、汽车还是行人,如下图所示:
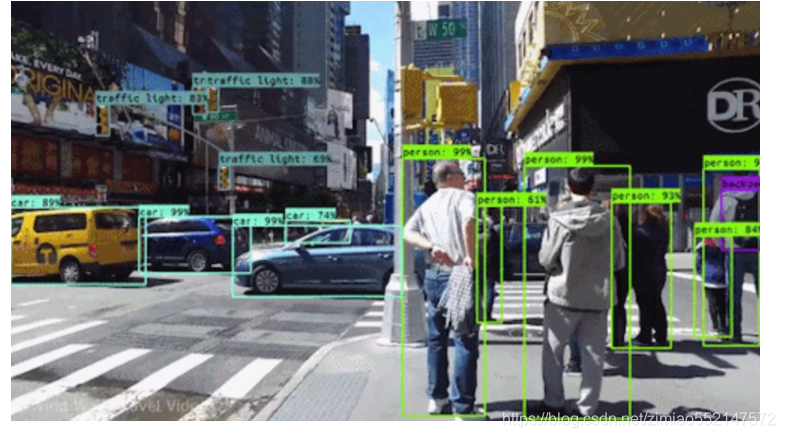
此类技术,加上对来自传感器和/或雷达等来源的数据进行分析,使得汽车能够看见。
1.1.2.3 行业案例
这里给商汤公司的应用解决方案系列图:比如说商汤公司做的一些计算机视觉方案:https://www.sensetime.com/Service/。

智慧零售

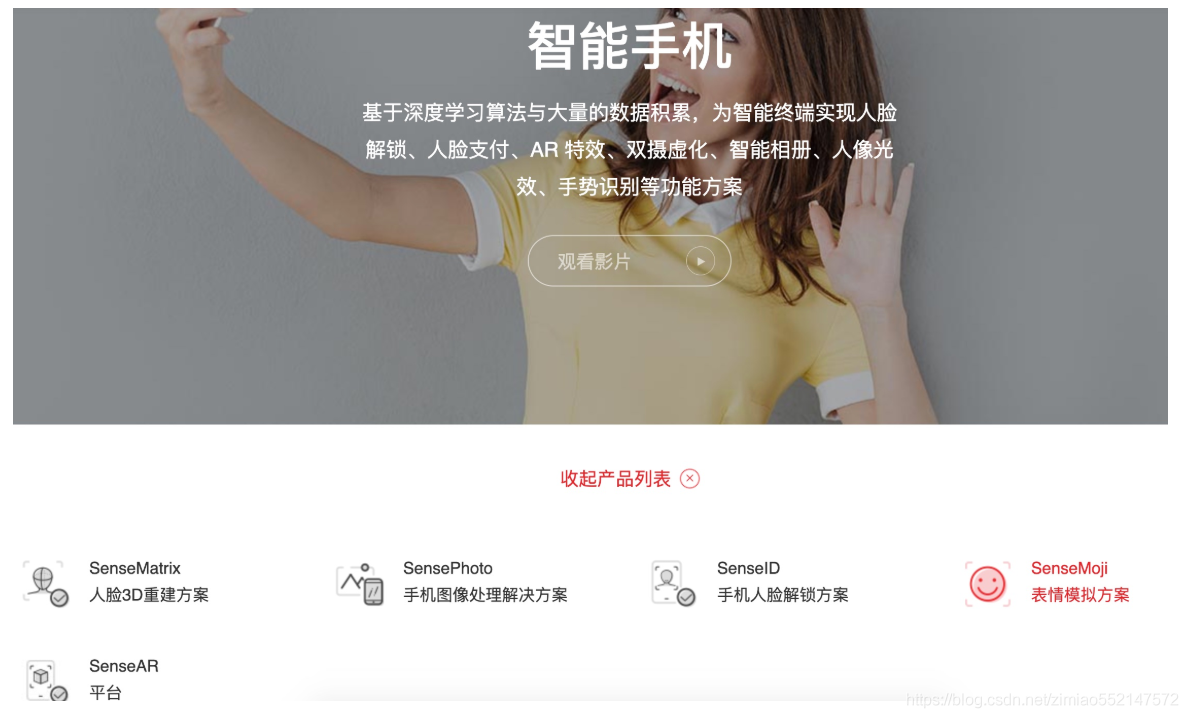
智能手机
进行人脸识别、AR特效、图片处理等等功能,同样也可以在各种APP中应用。
视觉搜索引擎
Yahoo 仅支持关键词搜索,搜索结果同样不错,如下图所示。
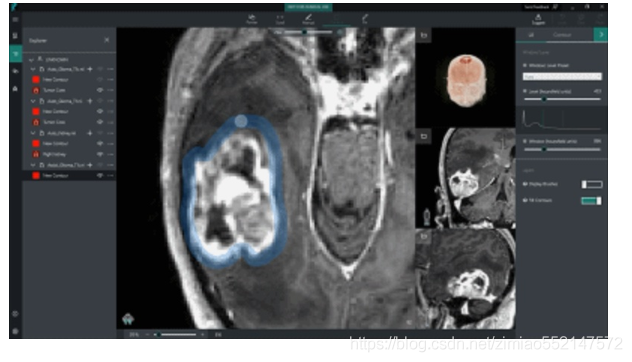
微软 InnerEye
在医疗行业中,微软的 InnerEye 是帮助放射科医生、肿瘤专家和外科医生处理放射图像的宝贵工具。其主要目的是从恶性肿瘤的 3D 图像中准确识别出肿瘤。基于计算机视觉和机器学习技术,InnerEye 输出非常详细的肿瘤 3D 建模图像。以上截图展示了 InnerEye 创建的对脑部肿瘤的完整 3D 分割。从上述视频中,你可以看到专家控制 InnerEye 工具,指引它执行任务,InnerEye 像助手一样运行。
特斯拉 Autopilot
特斯拉 Autopilot 技术提供非常方便的自动驾驶功能。这并不是全自动驾驶系统,而是可在特定路段上驾驶汽车的驾驶助手。特斯拉汽车装有:八个全景摄像头提供 250 米范围内的 360 度图像、超声波传感器用于检测对象、雷达用来处理周围环境信息。
1.1.3 总结
- 计算机视觉定义
- 计算机视觉公司与应用场景
1.2 计算机视觉任务
1.2.1 计算机视觉发展历程
- 1、1963年,Larry Roberts发表了(可能是)CV领域的第一篇专业论文,用以对简单几何体进行边缘提取和三维重建。1966年,麻省理工学院(MIT)发起了一个夏季项目,目标是搭建一个机器视觉系统,完成模式识别(pattern recognition)等工作。
- 从现在来看,当时的目标确实定的过大,以至于到了50多年后的今天为止,即使CV领域有了数以千计的科学工作者,仍然无法建立起整个机器视觉系统。
-
2、七十年代,同样是在MIT,学者David Marr发表的著作《Vision》从严谨又长远的角度给出了CV的发展方向和一些基本算法,其中不乏现在为人熟知的“图层”的概念、边缘提取、三维重建等。
- 整个60年代到80年代,虽然CV的概念已经提出了20年,但是与“识别”相关的工作进展得并不顺利。除了上述些许学者们点燃的星星之火,很难看到太多突破性的方法和文献。因此人们开始思考:如果图像识别太困难了,那为什么不先试试图像分割呢?
-
3、1999年David Lowe提出了尺度不变特征变换(SIFT, Scale-invariant feature transform)目标检测算法,用于匹配不同拍摄方向、纵深、光线等图片中的相同元素。
- (1)2001年,在互联网泡沫的大背景下,CV领域却发展得风生水起,并再次取得重大突破性进展:Paul Viola和Michael Johns使用Adaboost算法实现了实时性的人脸检测。而这一技术仅在5年后就被富士胶片公司(Fujifilm)用于产品中——首个带有实时人脸检测功能的照相机。
- (2)同一时期,Lazbnik, Schmid 和 Ponce等人提出了空间金字塔匹配算法(SPM, Spatial Pyramid Matching),具有开创性地将图片进行分块和特征提取,以验证图片间的相似度。Dalal和Triggs等人提出了进行人物识别的HoG特征(Histogram of Gradient)。2009年,Felzenswalb, McAllester和Ramanan等人提出了可变形部件模型(DPM, Deformable Parts Model)。
- 4、随着互联网的不断发展,学习计算机视觉可用的图片资源越来越多
- (1)Everingham等人在2006年至2012年间搭建了一个大型图片数据库,供机器识别和训练,称为PASCAL Visual Object Challenge,该数据库中有20种类别的图片,每种图片数量在一千至一万张不等。
- (2)后来Li Fei-fei等人搭建了图像数据库ImageNet,总计两万两千种类别,和一千四百余万张图片。通过训练ImageNet所给出的数据集,识别错误率正逐年下降,并在2015年就已经低于了正常人类的错误率。图中值得注意的是,在2012年,识别错误率突然下降了近10个百分点,这得益于卷积神经网络(CNN,Convolutional Neural Network)的运用,或者更为大家所知晓的概念就是——深度学习(Deep Learning)。CNN在识别错误率上远低于同年的其他模型,这标志着以深度学习为核心的CV时代正式开启。
1.2.2 典型的计算机视觉任务
计算机视觉基于大量不同任务,并组合在一起实现高度复杂的应用。计算机视觉中最常见的任务是图像和视频识别,涉及确定图像包含的不同对象。
-
四大主要任务
- 图像分类
- 目标检测
- 目标分割
- 目标追踪
-
1、图像分类
计算机视觉中最知名的任务可能就是图像分类了,它对给定图像进行分类。我们看一个简单的二分类例子:我们想根据图像是否包含旅游景点对其进行分类。假设我们为此任务构建了一个分类器,并提供了一张图像(见下图)。
我们要得出这张建筑图片是否是埃菲尔铁塔。

- 2、目标检测
- 目标检测通常是从图像中输出单个目标的Bounding Box(边框)以及标签
我们想象一个同时包含定位和分类的动作,对一张图像中的所有感兴趣对象重复执行该动作,这就是目标检测。该场景中,图像中的对象数量是未知的。因此,目标检测的目标是找出图像中的对象,并进行分类。

在这个密集图像中,我们可以看到计算机视觉系统识别出大量不同对象:汽车、人、自行车,甚至包含文本的标志牌。这个问题对人类来说都算困难的。一些对象只显示出一部分,因为它们有一部分在图像外,或者彼此重叠。此外,相似对象的大小差别极大。目标检测的一个直接应用是计数,它在现实生活中应用广泛,从计算收获水果的种类到计算公众集会或足球赛等活动的人数,不一而足。
- 3、语义分割(Semantic Segmentation)
我们可以把实例分割看作是目标检测的下一步。它不仅涉及从图像中找出对象,还需要为检测到的每个对象创建一个尽可能准确的掩码。

你可以从上图中看到,实例分割算法为四位披头士成员和一些汽车创建掩码(不过该结果并不完整,尤其是列侬)。
还有实例分割与语义分割有所不同,物体分割不仅需要对图像中不同的对象进行分类,而且还需要确定它们之间的界限、差异和关系。
- 4、目标追踪
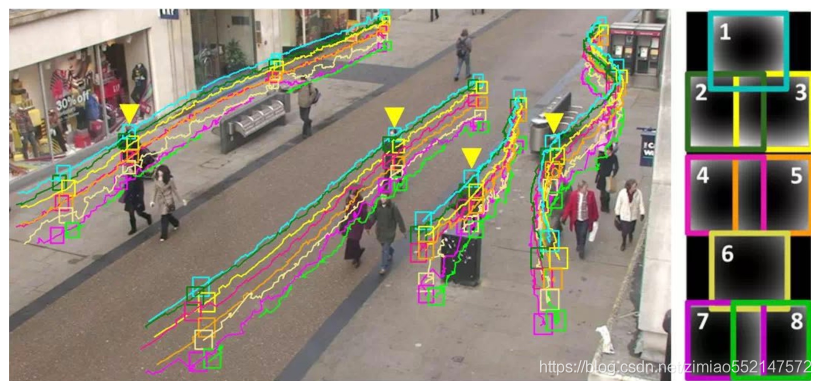
目标追踪旨在追踪随着时间不断移动的对象,它使用连续视频帧作为输入。该功能对于机器人来说是必要的,以守门员机器人举例,它们需要执行从追球到挡球等各种任务。目标追踪对于自动驾驶汽车而言同样重要,它可以实现高级空间推理和路径规划。类似地,目标追踪在多人追踪系统中也很有用,包括用于理解用户行为的系统(如零售店的计算机视觉系统),以及在游戏中监控足球或篮球运动员的系统。
- 其他任务技术:
- 图像标注 (Image Captioning)
- 图像标注是一项引人注目的研究领域,它的研究目的是给出一张图片,你给我用一段文字描述它。(根据图片生成描述文字)
- 图像生成(Image Generator):文字转图像
- 超分辨率、风格迁移、着色
- 超分辨率指的是从低分辨率对应物估计高分辨率图像的过程,以及不同放大倍数下图像特征的预测,这是人脑几乎毫不费力地完成的。最初的超分辨率是通过简单的技术,如bicubic-interpolation和最近邻。在商业应用方面,克服低分辨率限制和实现“CSI Miami”风格图像增强的愿望推动了该领域的研究。
- 风格转换:作为一个主题,一旦可视化是相当直观的,比如,拍摄一幅图像,并用不同的图像的风格特征呈现。
- 着色:是将单色图像更改为新的全色版本的过程。最初,这是由那些精心挑选的颜色由负责每个图像中的特定像素的人手动完成的。2016年,这一过程自动化成为可能,同时保持了以人类为中心的色彩过程的现实主义的外观。
- 行为识别
- 行为识别的任务是指在给定的视频帧内动作的分类,以及最近才出现的,用算法预测在动作发生之前几帧的可能的相互作用的结果。
- 人体姿势估计
- 人体姿势估计试图找出人体部位的方向和构型。 2D人体姿势估计或关键点检测一般是指定人体的身体部位,例如寻找膝盖,眼睛,脚等的二维位置。
- 图像标注 (Image Captioning)
注:在基础课程部分会着重介绍分类、检测、分割、追踪几种任务,也是计算机视觉关键的任务。在后面案例或者项目中中会基于基础阶段介绍的算法来进行讲解其热门他方向(如人脸识别、关键点检测等)
1.2.3 总结
- 计算机视觉发展历程
- 计算机视觉的任务















 7600
7600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











