







 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
BATCH_SIZE大小设置对训练耗时的影响:
1.如果当设置BATCH_SIZE等于训练样本时,比如训练样本有512个,设置BATCH_SIZE=512,那么一次BATCH_SIZE=512的批量数据进行训练时,
会计算BATCH_SIZE=512个样本的反向传播,求出512个样本的梯度累计和,然后使用该梯度累计和进行一次权重参数更新。
2.如果当设置BATCH_SIZE等于1时,,比如训练样本有512个,设置BATCH_SIZE=1,那么一次BATCH_SIZE=1的批量数据进行训练时,
会计算BATCH_SIZE=1个样本的反向传播,求出1个样本的梯度,然后使用该梯度进行一次权重参数更新,
那么当所有512个样本都完成训练时,一共进行了512次反向传播(梯度计算),512次参数更新。
3.结论:
1.显然BATCH_SIZE设置越大,那么所有训练样本数据完成一次训练(完成一个epoch)要进行的参数更新次数会更少,
那么训练耗时更短,BATCH_SIZE设置越小,一个epoch训练完所有样本数据要进行的参数更新次数会更多,
因此训练耗时更长。
2.当然训练耗时也和你所选取的优化算法是全批量梯度下降BGD、随机梯度下降SGD、小批量梯度下降Mini-batch GD(MBGD)有关。
4.每个批量数据训练都要执行的代码流程
# 设置优化器初始梯度为0
optimizer.zero_grad()
# 模型输入一个批次数据, 获得输出
output = model(text)
# 根据真实标签与模型输出计算损失
loss = criterion(output, label)
# 将该批次的损失加到总损失中
train_loss += loss.item()
# 误差反向传播
loss.backward()
# 参数进行更新
optimizer.step()3.1 深度学习优化算法
深度学习难以在大数据领域发挥最大效果的一个原因是,在巨大的数据集基础上进行训练速度很慢。而优化算法能够帮助我们快速训练模型,提高计算效率。接下来我么就去看有哪些方法能够解决我们刚才遇到的问题或者类似的问题。
3.1.1 优化算法
- 优化的目标在于降低训练损失,只关注最小化目标函数上的表现
深度学习问题中,我们通常会预先定义一个损失函数。有了损失函数以后,我们就可以使用优化算法试图将其最小化。在优化中,这样的损失函数通常被称作优化问题的目标函数(objective function)。依据惯例,优化算法通常只考虑最小化目标函数。
3.1.1.1优化遇到的挑战
- 局部最优
- 梯度消失
3.1.1.2 局部最优
- 定义:对于目标函数f(x),如果f(x)在x上的值比在x邻近的其他点的值更小,那么f(x)可能是一个局部最小值(local minimum)。如果f(x)在x上的值是目标函数在整个定义域上的最小值,那么f(x)是全局最小值(global minimum)。
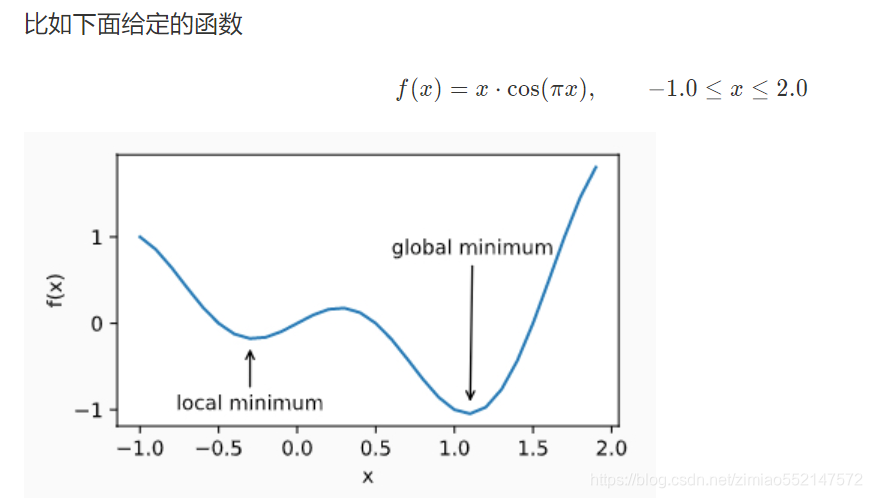
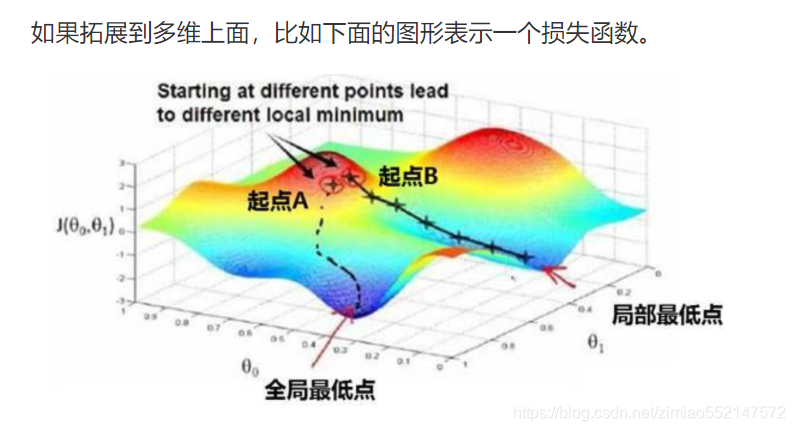
当一个优化问题的数值解在局部最优解附近时,由于目标函数有关解的梯度接近或变成零,最终迭代求得的数值解可能只令目标函数局部最小化而非全局最小化。
3.1.1.3 鞍点与海森矩阵(Hessian Matric)
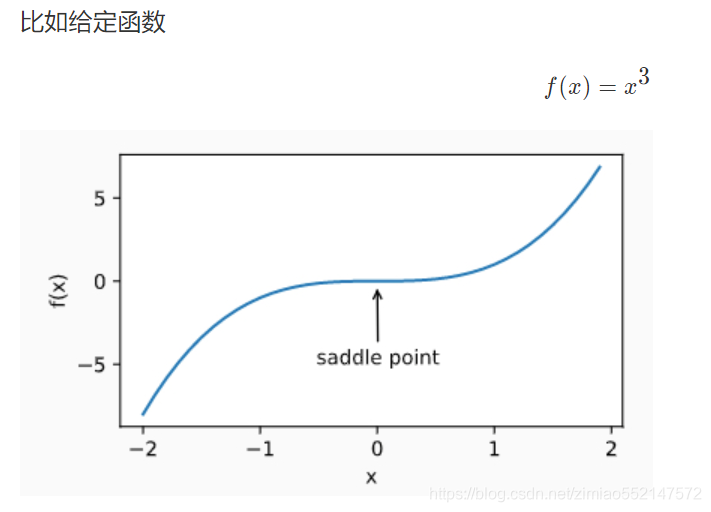
刚刚我们提到,梯度接近或变成零可能是由于当前解在局部最优解附近造成的。事实上,另一种可能性是当前解在鞍点(saddle point)附近。
- 鞍点(saddle)是函数上的导数为零,但不是轴上局部极值的点。通常梯度为零的点是上图所示的鞍点,而非局部最小值。减少损失的难度也来自误差曲面中的鞍点,而不是局部最低点。
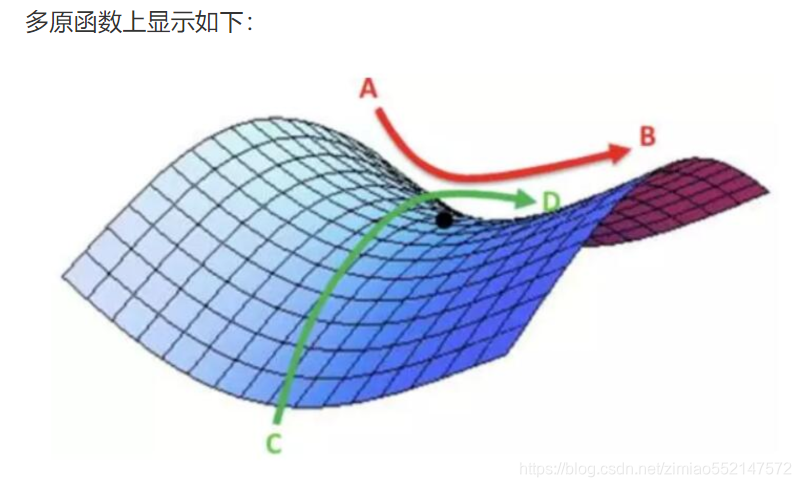
上图中,目标函数在CD方向是一个局部最大值,但是在AB方向是一个局部最小值。所有当某个函数在梯度为0的位置上可能是局部最小之、局部最大值或者鞍点。
- 条件:
- 当函数的海森矩阵在梯度为零的位置上的特征值全为正时,该函数得到局部最小值。
- 当函数的海森矩阵在梯度为零的位置上的特征值全为负时,该函数得到局部最大值。
- 当函数的海森矩阵在梯度为零的位置上的特征值有正有负时,该函数得到鞍点。
为什么海森矩阵判断?
回想一下我们是如何处理一元函数求极值问题的。例如,f(x)=x^2,我们会先求一阶导数,即f′(x)=2x,某点处的一阶导数一定等于 0。但这仅是一个必要条件,而非充分条件。对于f(x)=x^2来说,函数的确在一阶导数为零的点取得了极值,但是对于f(x)=x^3来说,显然只检查一阶导数是不足以下定论的。
海森矩阵:
- 海森矩阵最早于19世纪由德国数学家Ludwig Otto Hesse提出,并以其名字命名。利用黑塞矩阵可判定多元函数的极值问题。
- 一个多元函数的二阶偏导数构成的方阵

3.1.1.4 梯度消失
为什么会造成我们的损失函数难优化,其实有个原因就是因为激活函数存在使得函数计算梯度时候遇到梯度消失问题。在梯度函数上出现的以指数级递增或者递减的情况分别称为梯度爆炸或者梯度消失。
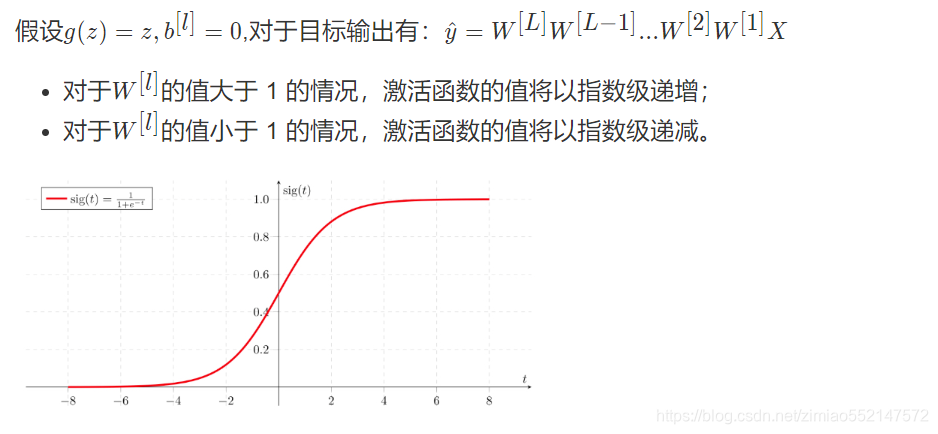
在计算梯度时,根据不同情况梯度函数也会以指数级递增或递减,导致训练导数难度上升,梯度下降算法的步长会变得非常小,需要训练的时间将会非常长。
解决办法有多种形式
通常会结合一些形式一起进行
- Mini梯度下降法
- 梯度下降算法的优化
- 初始化参数策略
- 学习率衰减
3.1.2 批梯度下降算法(Batch Gradient Descent)
- 定义:批梯度下降法(btach),即同时处理整个训练集。
其在更新参数时使用所有的样本来进行更新。对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候,处理速度就会比较慢。
所以换一种方式,每次处理训练数据的一部分进行梯度下降法,则我们的算法速度会执行的更快。
3.1.2.1 Mini-Batch Gradient Descent
- 定义:Mini-Batch 梯度下降法(小批量梯度下降法)每次同时处理固定大小的数据集。
不同
- 种类:
- mini-batch 的大小为 1,即是随机梯度下降法(stochastic gradient descent)
使用 Mini-Batch 梯度下降法,对整个训练集的一次遍历(epoch)只做 mini-batch个样本的梯度下降,一直循环整个训练集。
3.1.2.2 批梯度下降与Mini-Batch梯度下降的区别
batch梯度下降法和Mini-batch 梯度下降法代价函数的变化趋势如下:
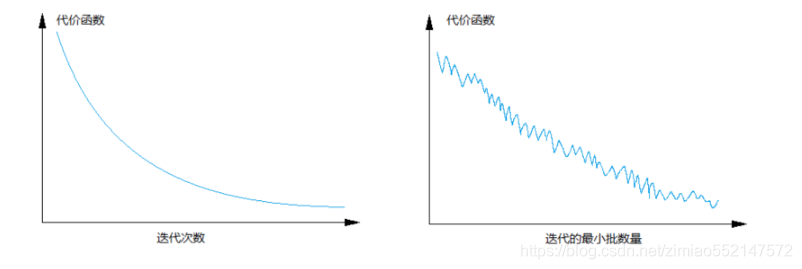
那么对于梯度下降优化带来的影响
3.1.2.3 梯度下降优化影响
- batch 梯度下降法:
- 对所有 m 个训练样本执行一次梯度下降,每一次迭代时间较长,训练过程慢;
- 相对噪声低一些,成本函数总是向减小的方向下降。
- 随机梯度下降法(Mini-Batch=1):
- 对每一个训练样本执行一次梯度下降,训练速度快,但丢失了向量化带来的计算加速;
- 有很多噪声,需要适当减小学习率,成本函数总体趋势向全局最小值靠近,但永远不会收敛,而是一直在最小值附近波动。
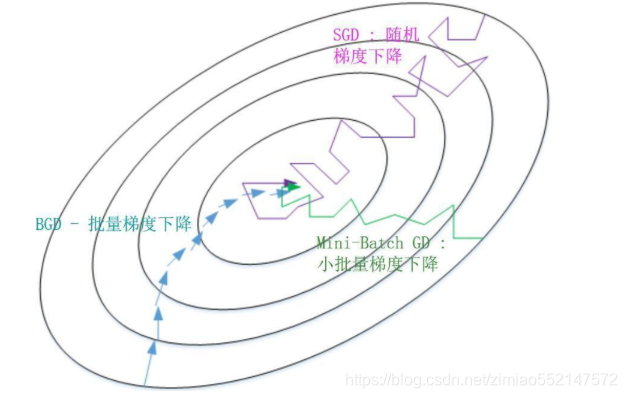
因此,选择一个合适的大小进行 Mini-batch 梯度下降,可以实现快速学习,也应用了向量化带来的好处,且成本函数的下降处于前两者之间。
















 2579
2579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











