







基本概念
>将中文或者英文分成一个个关键字,
用于倒排索引
分词类型:(下面会详细介绍)
ik_smart 最少切分
ik_max_word 最细粒度切分
下载安装
本人使用的是docker进行下载安装(真的很方便)
先进入es容器,
输入
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.0/elasticsearch-analysis-ik-7.6.0.zip
注意版本号要和es一致!!!
安装完成后查看是否成功:

测试
在kibana按照如下命令运行
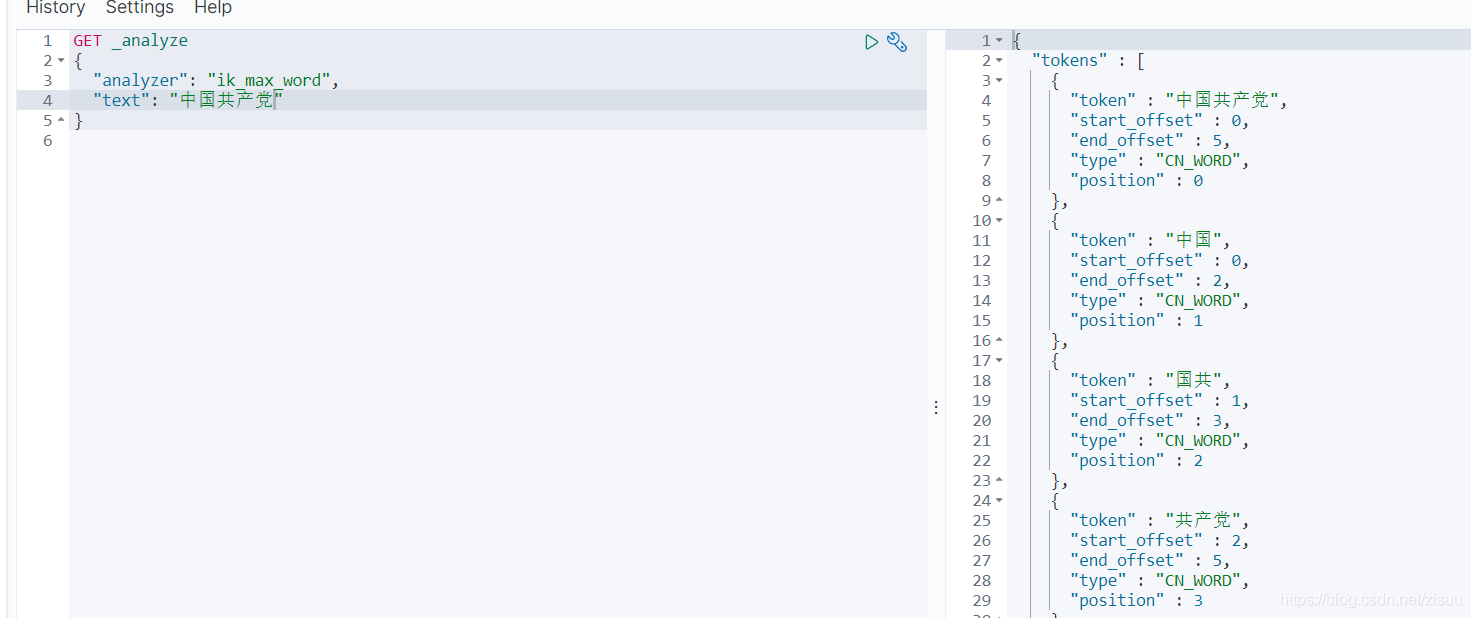
分词方法:
- ik_max_word
会将文本做最细粒度的拆分,所谓最细粒度划分,就是穷奇可能,将一句话分成尽可能多的单词
- ik_smart
会将文本做最粗粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」
具体运行结果如下:
ik_smart版本:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "国歌",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 1
}
]
}
ik_max_word:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "国歌",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 9
}
]
}















 9345
9345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









