







一、顶点着色器和像素着色器
之前一直不理解“顶点着色器--每个顶点都执行一次,像素着色器是每个像素执行一次”这句话。今天终于理解加深了!
一个很简单的例子:
假设我们要通过glsl画出如下图:

这个要用glsl实现其实很简单,这是一个矩形,就是用两个直角三角形拼接出来的。
按照最普通的模式,两个三角形,总共6个顶点,所以我们需要在opengl端把各个顶点的位置都定义好,然后把这6个顶点传递给vs即可。
顶点定义如下:(注意,opengl中描述顶点顺序采用的是逆时针!)
float[] vertices =
{
-0.5f, 0.5f, 0f,
-0.5f, -0.5f, 0f,
0.5f, -0.5f, 0f,
//right top trianle
0.5f, -0.5f, 0f,
0.5f, 0.5f, 0f,
-0.5f, 0.5f, 0f
};这样就很好理解了。
二、索引数组
如上,我们画两个三角形,用了6个float顶点,可以明显的看到第一行和最后一行重复了,第三行和第四行(忽略掉注释行)重复了,也就是有两个顶点重复了。索引数组就是通过使用索引来降低数据的重复率,提高opengl程序的性能。
如果用index buffer来实现同样的一个渲染效果,我们会这么做:
之前的两个三角形,顶点是这样的:
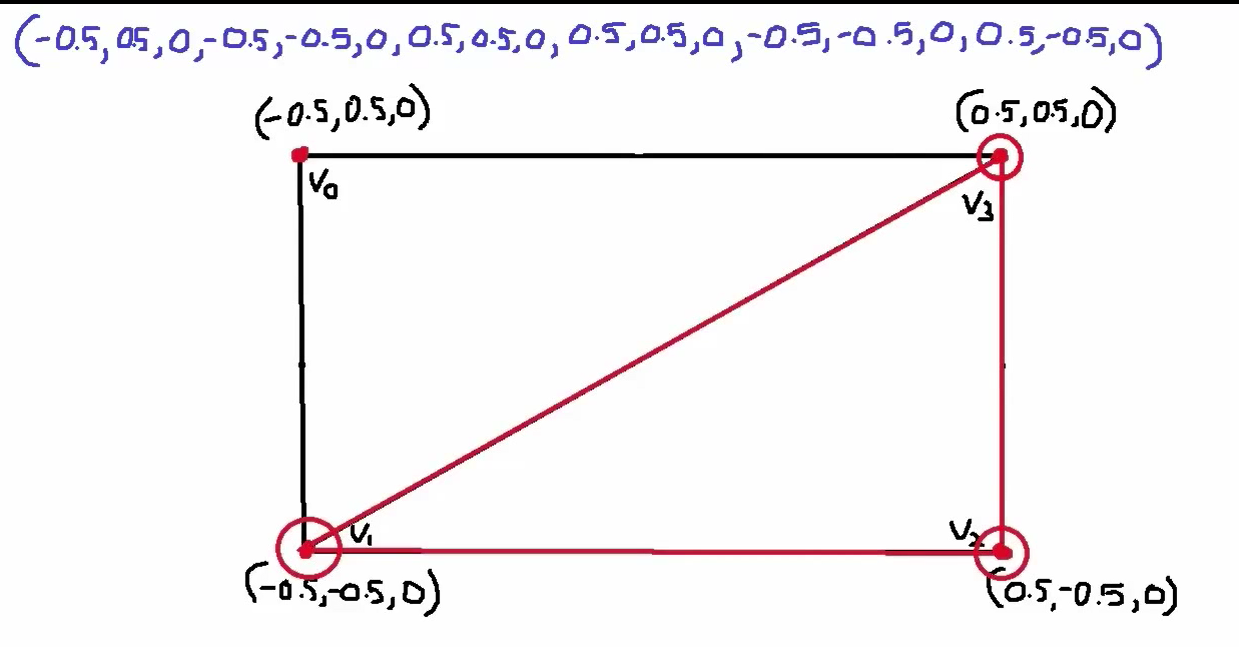
如上图,最上面一行是没使用索引数组时给出的6个顶点。
使用索引数组的话,我们只需要先给出v0,v1,v2,v3四个坐标,然后给出一个索引数组来说明这四个顶点之间是如何连接的即可,分别用整形数字0~3来表示v0~v3四个顶点,按照逆时针方向来规定顶点的顺序,所以这里我们需要的索引数组是:0,1,3,3,1,2。
也就是说,如果我们用index buffer的方式,需要一个基本顶点数据和一个索引数组这两个东西。
两种方法的比较:
如果不使用索引数组,那么需要6 * 3 = 18个float数据。
如果使用索引数组,那么需要4 * 3 + 6 = 12个float数据+6个整形数据。
这样看好像差不多,其实不然,因为我们这个例子很简单。
因为当需求大的时候,通常一个顶点包含的数据更多:3个float表示位置+3个float表示法线坐标+2个float表示纹理坐标 = 8个float。如果还是渲染这个矩形,那么一共6个顶点,所以需要8*6 = 48个float数据,按照java中一个float = 4 byte,所以这里一共需要48*4=192byte。
而用索引数组方法的话,需要:8*4+6=32个float数据+6个整形数据 = 32 * 4 + 6 * 4(一个int=4byte) = 152byte。
法一的数据量是法二的接近1.3倍!

如果是更加复杂的模型,如果不用索引数组的方法来做渲染的话,那会更加恐怖!
结论:越是复杂的模型,场景,就越是要用索引数组的方式来表示顶点之间的连接。















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









