






kettle安装部署和使用
2.1 kettle安装地址
官网地址
https://community.hitachivantara.com/docs/DOC-1009855
下载地址
https://sourceforge.net/projects/pentaho/files/Data%20Integration/
2.2 Windows下安装使用
2.2.1 概述
在实际企业开发中,都是在本地环境下进行kettle的job和Transformation开发的,可以在本地运行,也可以连接远程机器运行
2.2.2 安装
1) 安装jdk
2) 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可
3) 双击Spoon.bat,启动图形化界面工具,就可以直接使用了
2.2.3 案例
1) 案例一 把stu1的数据按id同步到stu2,stu2有相同id则更新数据
(1)在mysql中创建两张表
mysql> create database kettle;
mysql> use kettle;
mysql> create table stu1(id int,name varchar(20),age int);
mysql> create table stu2(id int,name varchar(20));
(2)往两张表中插入一些数据
mysql> insert into stu1 values(1001,’zhangsan’,20),(1002,’lisi’,18), (1003,’wangwu’,23);
mysql> insert into stu2 values(1001,’wukong’);
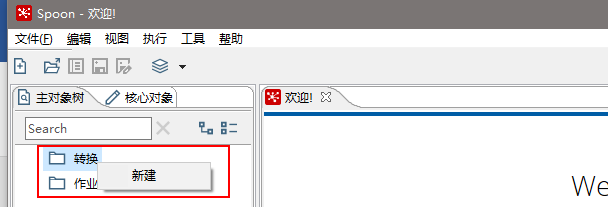
(3)在kettle中新建转换
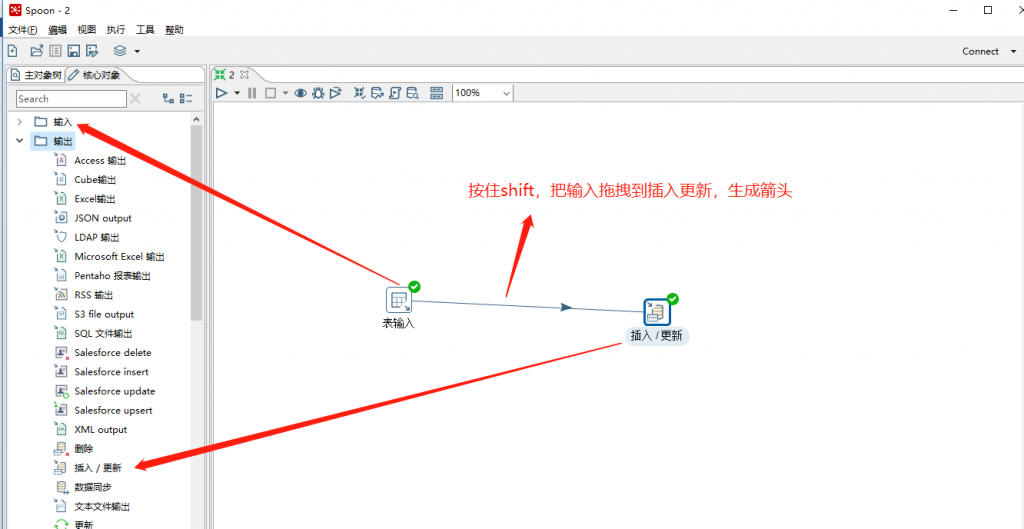
(4)分别在输入和输出中拉出表输入和插入/更新
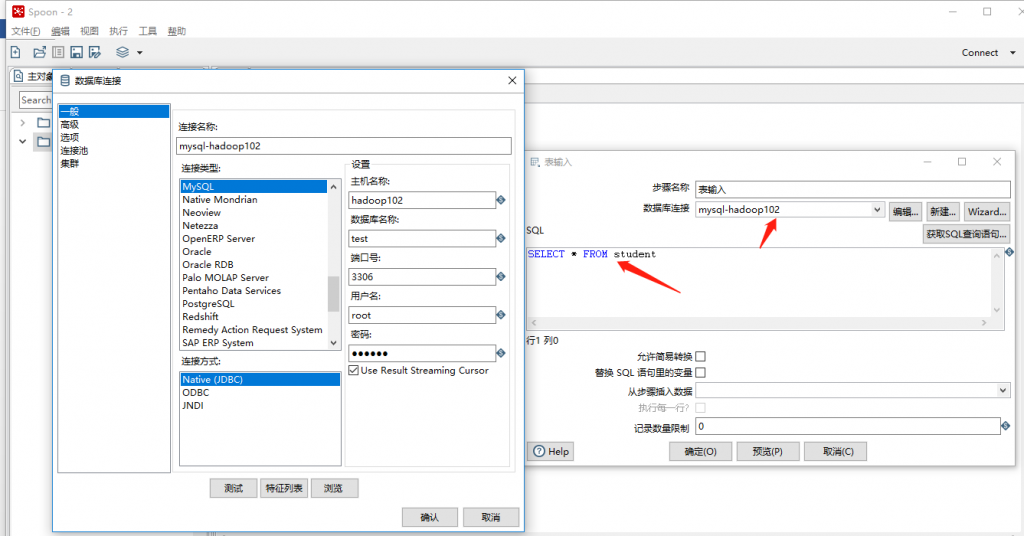
(5)双击表输入对象,填写相关配置,测试是否成功
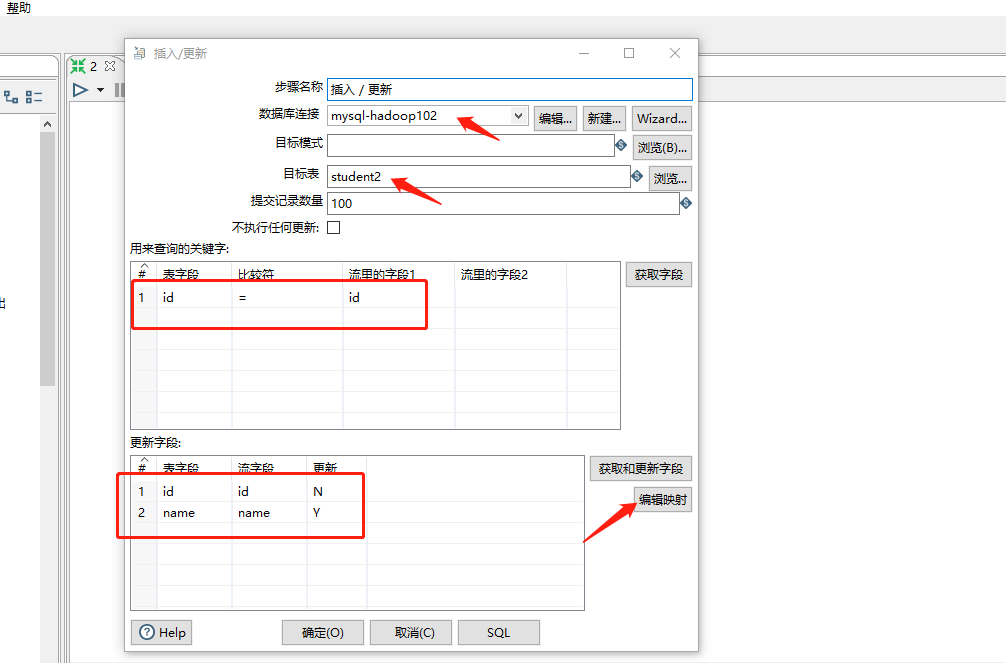
(6)双击 更新/插入对象,填写相关配置
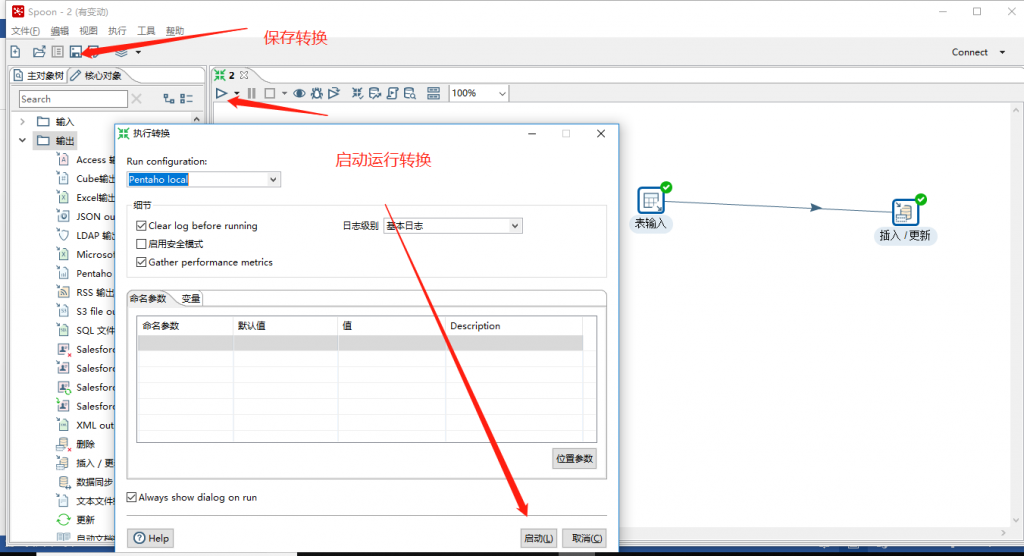
(7)保存转换,启动运行,去mysql表查看结果
注意:如果需要连接mysql数据库,需要要先将mysql的连接驱动包复制到kettle的根目录下的lib目录中,否则会报错找不到驱动。
2) 案例2:使用作业执行上述转换,并且额外在表student2中添加一条数据
(1)新建一个作业
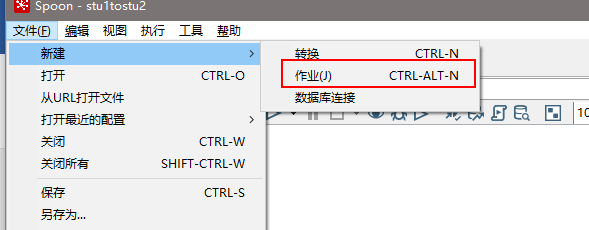
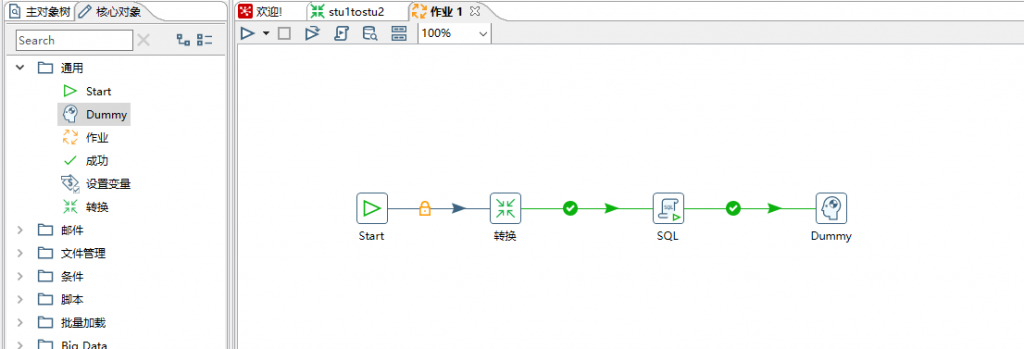
(2) 按图示拉取组件
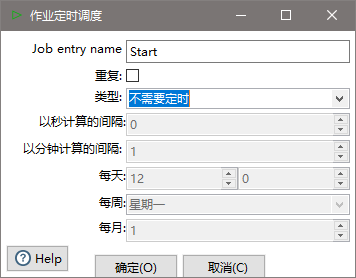
(3)双击Start编辑Start
(4)双击转换,选择案例1保存的文件
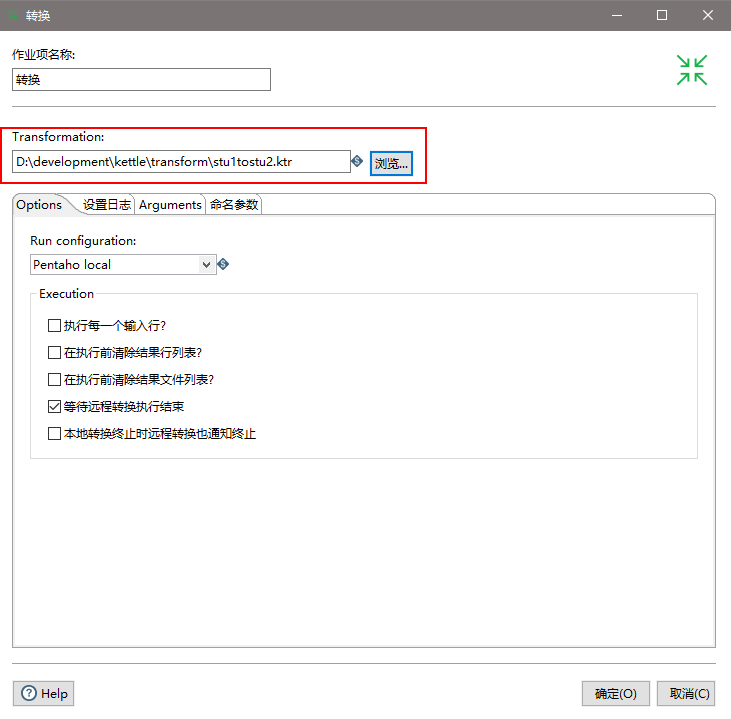
(5)双击SQL,编辑SQL语句
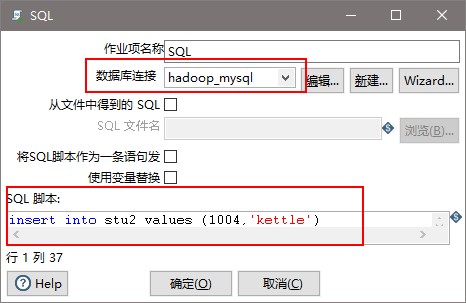
(6)保存执行
3)案例3:将hive表的数据输出到hdfs
(1)因为涉及到hive和hbase的读写,需要修改相关配置文件。
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
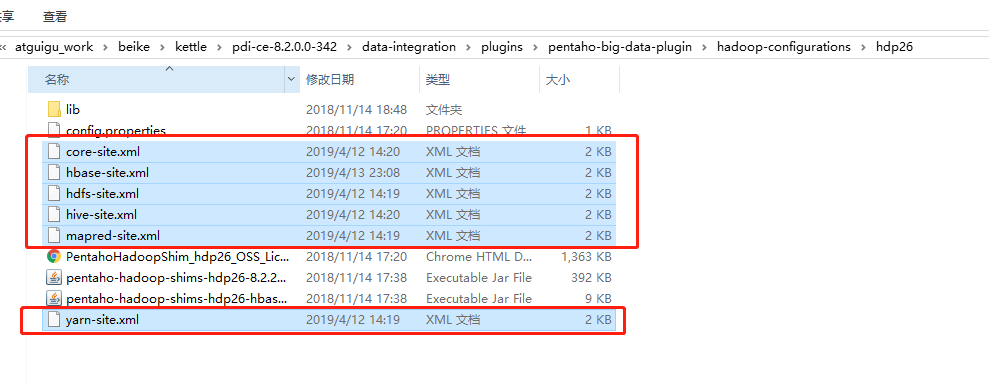
(2)启动hdfs,yarn,hbase集群的所有进程,启动hiveserver2服务
[atguigu@hadoop102 ~]$ /opt/module/hadoop-2.7.2/sbin/start-all.sh
开启HBase前启动Zookeeper
[atguigu@hadoop102 ~]$ /opt/module/hbase-1.3.1/bin/start-hbase.sh
[atguigu@hadoop102 ~]$ /opt/module/hive/bin/hiveserver2
(3)进入beeline,查看10000端口开启情况
[atguigu@hadoop102 ~]$ /opt/module/hive/bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://hadoop102:10000(回车)
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: atguigu(输入atguigu)
Enter password for jdbc:hive2://hadoop102:10000:(直接回车)
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000>(到了这里说明成功开启10000端口)
(4)创建两张表dept和emp
CREATE TABLE dept(deptno int, dname string,loc string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’;
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’;
(5)插入数据
insert into dept values(10,’accounting’,’NEW YORK’),(20,’RESEARCH’,’DALLAS’),(30,’SALES’,’CHICAGO’),(40,’OPERATIONS’,’BOSTON’);
insert into emp values
(7369,’SMITH’,’CLERK’,7902,’1980-12-17′,800,NULL,20),
(7499,’ALLEN’,’SALESMAN’,7698,’1980-12-17′,1600,300,30),
(7521,’WARD’,’SALESMAN’,7698,’1980-12-17′,1250,500,30),
(6)按下图建立流程图
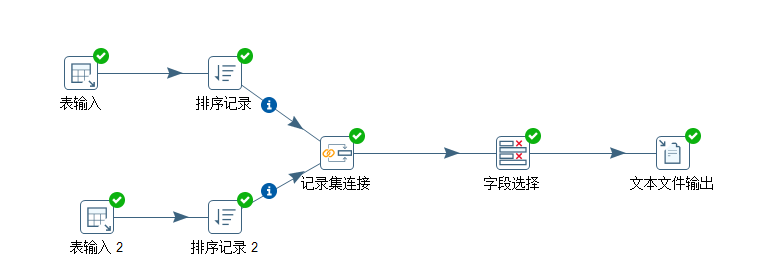
(7566,’JONES’,’MANAGER’,7839,’1980-12-17′,2975,NULL,20);
(7)设置表输入,连接hive
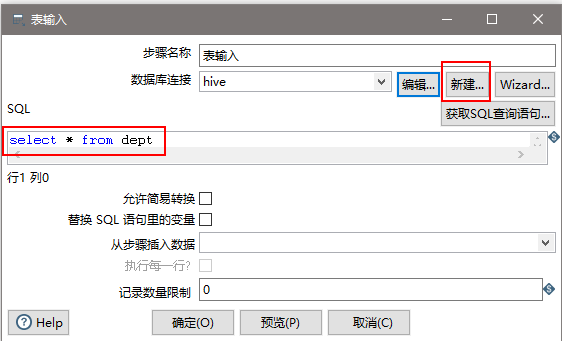
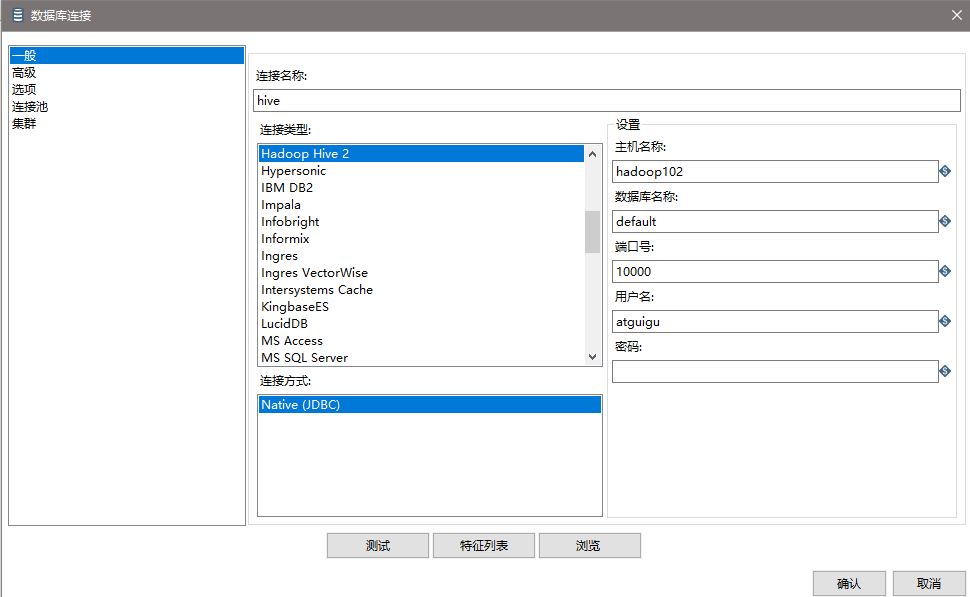
(8)设置排序属性
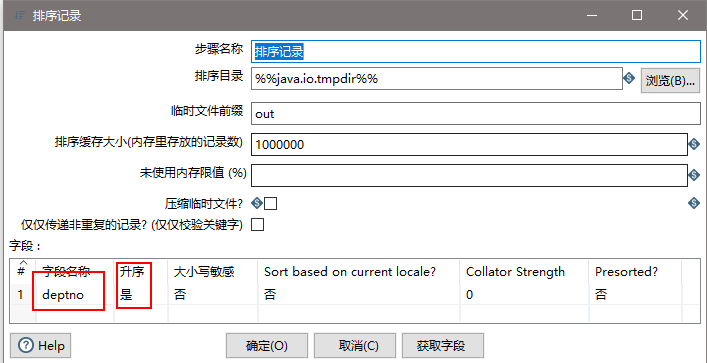
(9)设置连接属性
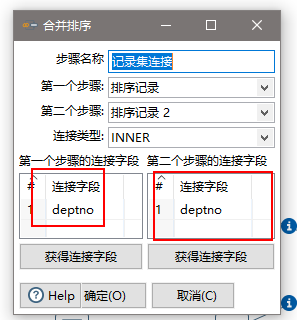
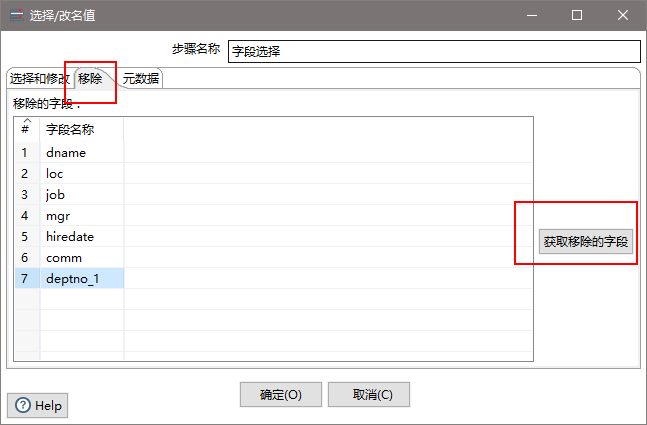
(10)设置字段选择
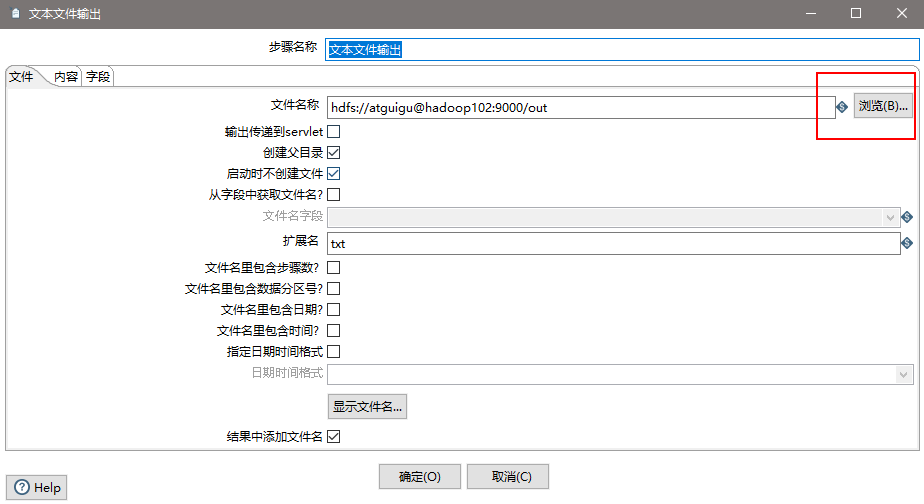
(11)设置文件输出
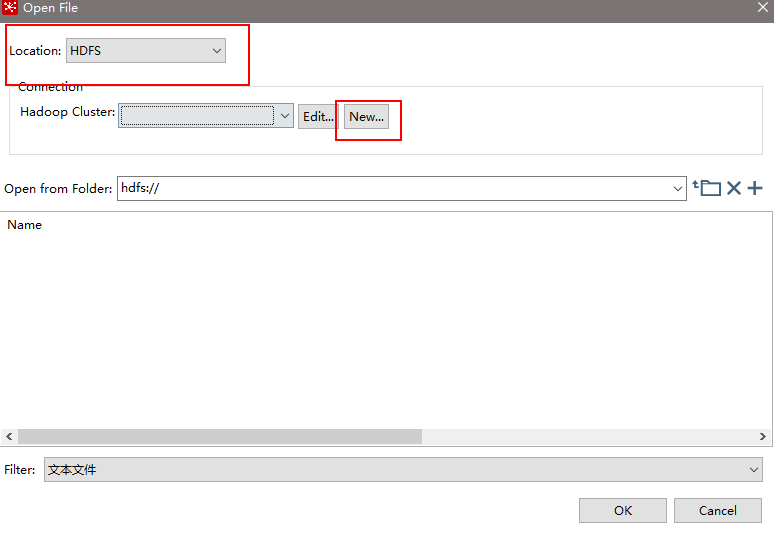
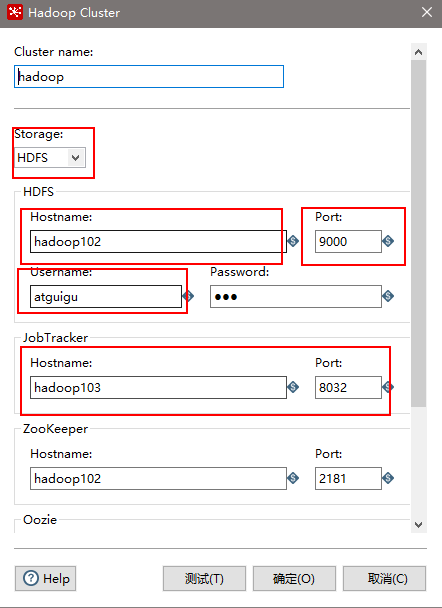
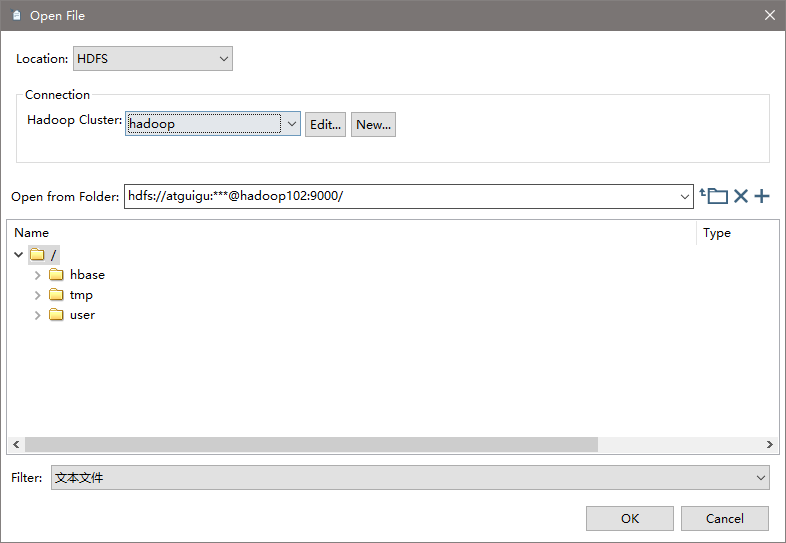
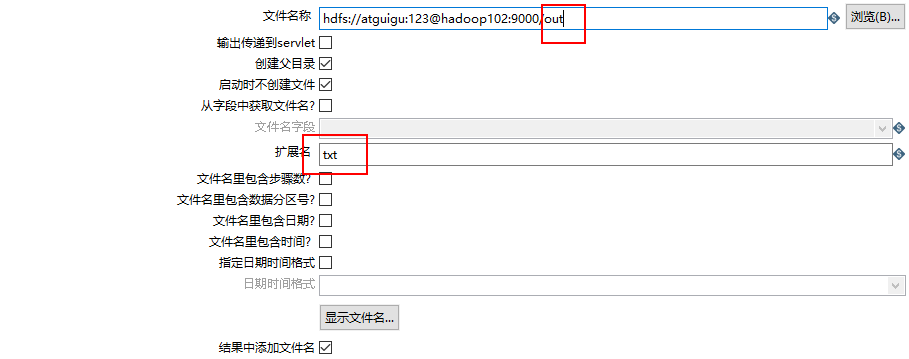
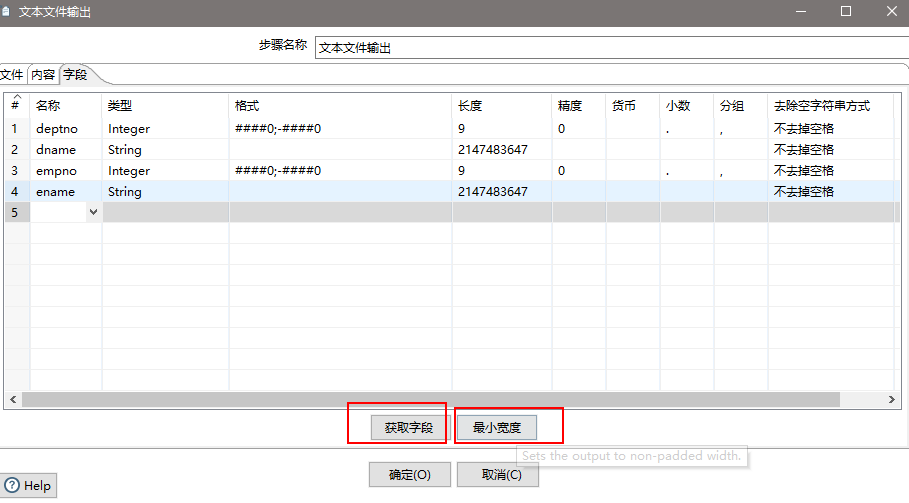
(12)保存并运行查看hdfs
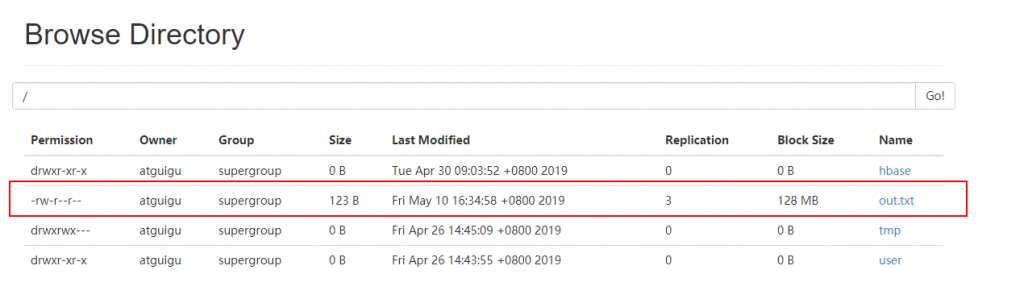
4)案例4:读取hdfs文件并将sal大于1000的数据保存到hbase中
(1) 在HBase中创建一张表用于存放数据
[atguigu@hadoop102 ~]$ /opt/module/hbase-1.3.1/bin/hbase shell
hbase(main):004:0> create ‘people’,’info’
(2)按下图建立流程图

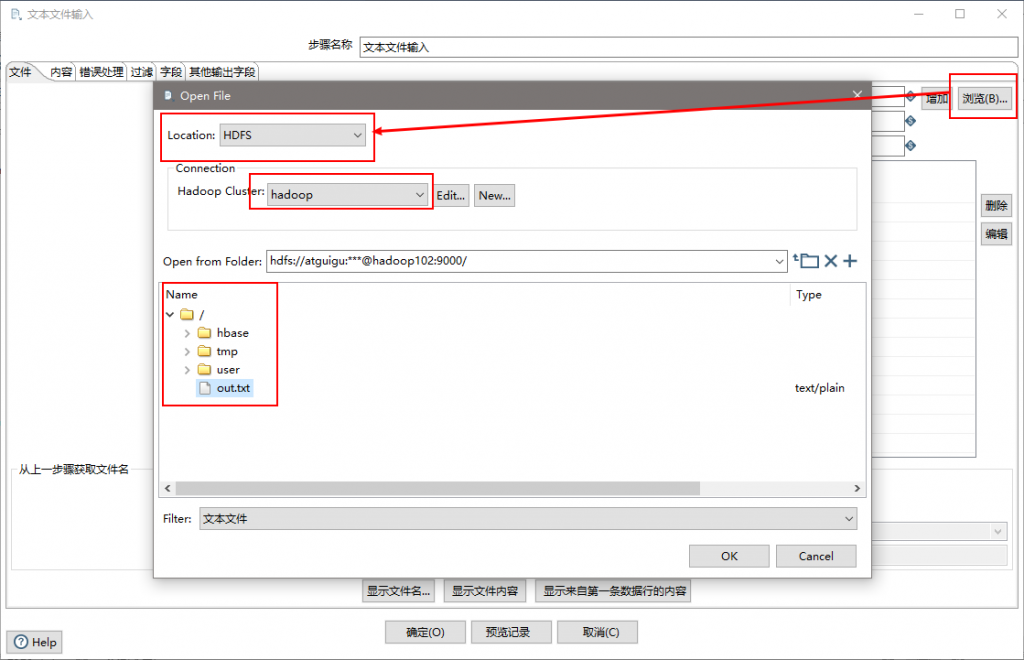
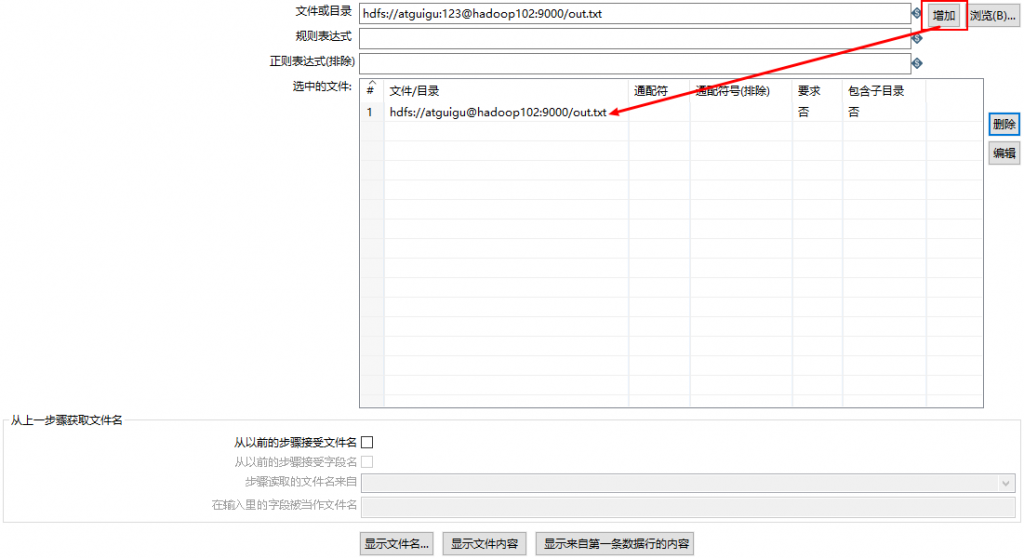
(3)设置文件输入,连接hdfs
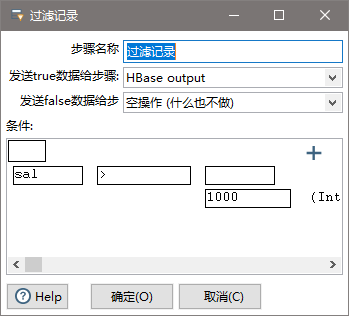
(4)设置过滤记录
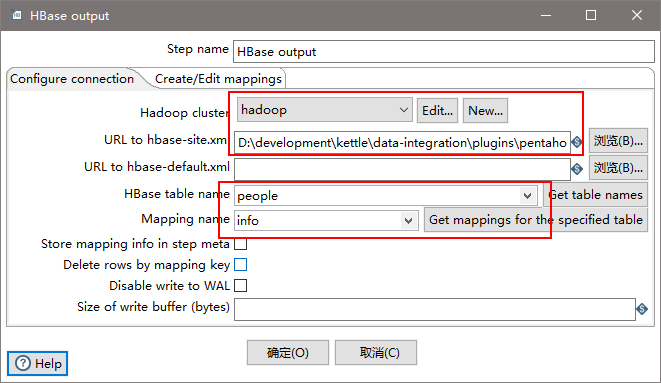
(5)设置HBase output
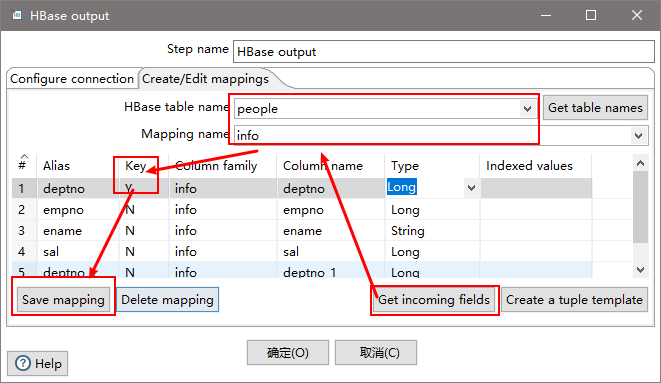
注意:若报错没有权限往hdfs写文件,在Spoon.bat中第119行添加参数
“-DHADOOP_USER_NAME=atguigu” “-Dfile.encoding=UTF-8”














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









