







reference:http://www.klayge.org/wiki/index.php/%E5%BB%B6%E8%BF%9F%E6%B8%B2%E6%9F%93
本文主要描述了自己实现延迟渲染下的透明物体渲染机制的过程。
方案探索
前提是已经实现了基本的延迟渲染框架,但还没有支持透明物体的渲染。最近打算开始进行这一项工作。
目前接触到的一个比较常见的做法是,使用延迟渲染+前向渲染结合的方式。也就是说,透明物体依然走传统的前向渲染的方式。这就意味着需要把延迟渲染计算各种复杂光照等代码在前向渲染里重新实现一遍。
首先,我们需要明确一个问题,为什么延迟渲染不适用于透明物体:延迟渲染只计算了离视野最近的物体像素,并对其进行光照计算和着色。因此,这会导致:
● 透明物体和不透明物体重叠时,半透明物体在后,仅渲染透明物体,效果正确。
● 透明物体和不透明物体重叠时,半透明物体在前,仅渲染半透明物体,效果错误。
● 透明物体之间重叠时,仅渲染最前面的半透明物体,效果错误。
此处参考了引用文章给出的透明渲染方案,概括而言,就是使用延迟渲染的框架,分别渲染不透明物体,透明物体背面,透明物体正面,再把三者按照alpha合并。
在这种情况下,我们可以基本保证第二种情况的正确;而对于第三种情况而言,根据前面的描述,由于延迟渲染仅对离相机最近的像素进行光照/着色计算,我们依然只能计算(特别地,若最近的像素透明度为0,我们忽略这一像素)最近物体的光照。
对于后者描述的情况,采取的解决方案是写入G-Buffer时仅混合物体颜色,在延迟渲染过程中,依然只计算最近物体的光照,但把混合后的颜色作为最近物体的基本颜色进行光照计算。
这就相当于假设后面物体的光没有透过半透明物体,但我们知道,之所以能看见物体,就是因为物体反射的光进入了我们的眼睛,所以这实际上是不可能的,极端的例子就是当物体完全透明的时候,我们依然会按照这个看不见的物体来计算光照。
通过这种方法,我们就得到了一个实现比较简单,性能消耗较低,效果大致上还说得过去的半透明效果。
具体实现
参考引用中的思路,我也简单设计了一下我的透明渲染框架,整个流程大致概括如下:
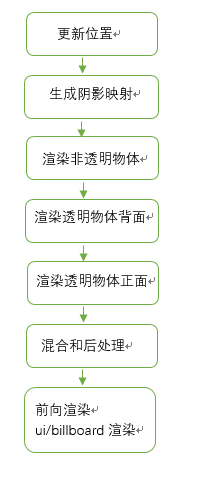
渲染队列
为了控制不同物体的渲染,引入了渲染队列机制。目前设定了如下选项:背景、默认、透明测试、叠加、透明混合(单面)、透明混合(双面)。定义如下:
enum ERenderQueue
{
ERQ_Background,
ERQ_Default,
ERQ_AlphaTest,
ERQ_Overlay,
ERQ_Transparent,
ERQ_Transparent_TwoSide,
ERQ_Num
};

使用较为简单的数据结构来维护:
vector<unordered_set<Object*>> renderQueue;
list<pair<Object*, bool>> transparentObjs;
// first : object, second : isTwoSideTransparent我们通过如下函数修改物体在渲染队列中的位置:
void ObjectInfo::SetRenderQueue(Object* obj, int renderPriority)
{
if(!obj)
{
return;
}
if(obj->renderPriority == renderPriority)
{
return;
}
bool bTransparentDirty = false;
// 1: erase the old obj
if(obj->renderPriority == ERQ_Transparent || obj->renderPriority == ERQ_Transparent_TwoSide)
{
bool bTwoSide = obj->renderPriority == ERQ_Transparent_TwoSide;
auto it = find(transparentObjs.begin(), transparentObjs.end(),make_pair(obj, bTwoSide));
if(it != transparentObjs.end())
{
transparentObjs.erase(it);
bTransparentDirty = true;
}
}
else if(obj->renderPriority >= 0)
{
size_t id = static_cast<size_t>(obj->renderPriority);
renderQueue[id].erase(obj);
}
// 2: insert the new obj
if(renderPriority == ERQ_Transparent || renderPriority == ERQ_Transparent_TwoSide)
{
bool bTwoSide = renderPriority == ERQ_Transparent_TwoSide;
transparentObjs.push_back({obj, bTwoSide});
bTransparentDirty = true;
}
else
{
size_t id = static_cast<size_t>(renderPriority);
renderQueue[id].insert(obj);
}
// 3: update renderpriority
obj->renderPriority = renderPriority;
// 4: check update sort
if(bTransparentDirty)
{
SortTransparentObjs();
}
}
写入帧缓冲与混合
首先,我们利用延迟渲染框架分别渲染不透明物体,透明物体背面,透明物体正面之后,将会得到三个屏幕大小的纹理。此我们需要分配一个屏幕大小的帧缓冲用于写入纹理。由于这三个过程是独立的(非同时进行的),因此每个过程可以共用同一个帧缓存。
对于已有的三张纹理,我们可以有很多种方法实现混合操作:要么在写入帧缓冲的时候,与颜色缓冲区中已有的颜色自行计算混合,输出计算后的颜色,之后,将纹理绘制到屏幕大小的四边形上即可;要么使用系统自带的glEnable(GL_BLEND),但后者似乎有一个弊端,就是在有多个缓冲区的时候,会对所有缓冲区都进行blend操作,无法单独控制每个通道的开关。
半透明混合
在绘制的过程中,我们完整地执行三次延迟渲染的操作。在第一次绘制不透明物体时,无需任何特殊操作;第二次绘制透明物体背面时,我们开启正面剔除,关闭深度写入;第三次绘制透明物体正面时,我们开启背面剔除,关闭深度写入。
同理,由于这几个过程是独立的,我们也可以共享G-Buffer对应的空间,而无需额外分配帧缓冲。这意味着我们无需浪费3倍的带宽和内存,就能直接在延迟渲染中引入透明渲染机制。但需要注意的是,切换过程中,G-Buffer中的颜色是可以清除的,但我们必须保留深度数据(或者以其它方式记录正确的深度),避免深度测试出错:

即使我们侥幸绕过了前向渲染,在不引入次序无关透明度算法的情况下,我们依然需要进行排序,以获得正确的效果。假设我们使用如下的计算公式:
glBlendFunc(GL_SRC_ALPHA , GL_ONE_MINUS_SRC_ALPHA);默认情况下,混合计算时不会考虑物体的先后顺序,它只会将当前写入的像素和即将写入的像素按照公式计算,在src和dst对调的时候,计算得到的颜色大概率是不正确的。因此,我们需要先绘制距离相机远的物体,再绘制距离相机近的物体。
最为基础的方式,是将物体视为质点,根据这一位置,按照它在视图空间的z值对透明物体进行排序。这里我们实际上忽略了物体本身的复杂度,如果物体较为复杂,一般的方法是将其拆分为多个组件进行渲染。
bool transparentCmp(const pair<Object*, bool>& data1, const pair<Object*, bool>& data2)
{
Object* obj1 = data1.first;
Object* obj2 = data2.first;
const QMatrix4x4& viewMat = Camera::Inst()->GetViewMatrix();
QVector4D pos1 = viewMat * QVector4D(obj1->position.x, obj1->position.y, obj1->position.z, 1.0f);
QVector4D pos2 = viewMat * QVector4D(obj2->position.x, obj2->position.y, obj2->position.z, 1.0f);
return pos1.z()/pos1.w() < pos2.z()/pos2.w();
}
void ObjectInfo::SortTransparentObjs()
{
transparentObjs.sort(transparentCmp);
}
在这种情况下,我们需要在渲染队列变化/相机视图矩阵变化的时候更新排序,是一个比较消耗性能的过程:
















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









