







一、实验数据与使用的网络
所谓样本不平衡,就是指在分类问题中,每一类对应的样本的个数不同,而且差别较大。这样的不平衡的样本往往使机器学习算法的表现变得比较差。那么在CNN中又有什么样的影响呢?作者选用了CIFAR-10作为数据源来生成不平衡的样本数据。
CIFAR-10是一个简单的图像分类数据集。共有10类(airplane,automobile,bird,cat,deer,dog, frog,horse,ship,truck),每一类含有5000张训练图片,1000张测试图片。
CIFAR-10样例如图:
训练时,选择的网络是这里的CIFAR-10训练网络和参数(来自Alex Krizhevsky)。这个网络含有3个卷积层,还有10个输出结点。
 训练时,选择的网络是
训练时,选择的网络是之所以不选用效果更好的CNN网络,是因为我们的目的是在实验时训练很多次进行比较,而不是获得多么好的性能。而这个CNN网络因为比较浅,训练速度比较快,比较符合我们的要求。
二、类别不平衡数据的生成
直接从原始CIFAR-10采样,通过控制每一类采样的个数,就可以产生类别不平衡的训练数据。如下表所示:这里的每一行就表示“一份”训练数据。而每个数字就表示这个类别占这“一份”训练数据的百分比。
 这里的每一行就表示“一份”训练数据。而每个数字就表示这个类别占这“一份”训练数据的百分比。
这里的每一行就表示“一份”训练数据。而每个数字就表示这个类别占这“一份”训练数据的百分比。Dist. 1:类别平衡,每一类都占用10%的数据。
Dist. 2、Dist. 3:一部分类别的数据比另一部分多。
Dist. 4、Dist 5:只有一类数据比较多。
Dist. 6、Dist 7:只有一类数据比较少。
Dist. 8: 数据个数呈线性分布。
Dist. 9:数据个数呈指数级分布。
Dist. 10、Dist. 11:交通工具对应的类别中的样本数都比动物的多
对每一份训练数据都进行训练,测试时用的测试集还是每类1000个的原始测试集,保持不变。
三、类别不平衡数据的训练结果
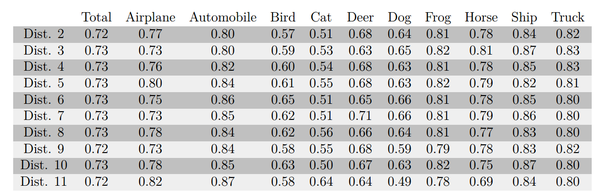
以上数据经过训练后,每一类对应的预测正确率如下:
第一列Total表示总的正确率,下面是每一类分别的正确率。
 第一列Total表示总的正确率,下面是每一类分别的正确率。
第一列Total表示总的正确率,下面是每一类分别的正确率。从实验结果中可以看出:
- 类别完全平衡时,结果最好。
- 类别“越不平衡”,效果越差。比如Dist. 3就比Dist. 2更不平衡,效果就更差。同样的对比还有Dist. 4和Dist. 5,Dist. 8和Dist. 9。其中Dist. 5和Dist. 9更是完全训练失败了。
四、过采样训练的结果
作者还实验了“过采样”(oversampling)这种平衡数据集的方法。这里的过采样方法是:对每一份数据集中比较少的类,直接复制其中的图片增大样本数量直至所有类别平衡。
再次训练,进行测试,结果为:
可以发现过采样的效果非常好,基本与平衡时候的表现一样了。
 可以发现过采样的效果非常好,基本与平衡时候的表现一样了。
可以发现过采样的效果非常好,基本与平衡时候的表现一样了。过采样前后效果对比,可以发现过采样效果非常好:

五、总结
CNN确实对训练样本中类别不平衡的问题很敏感。平衡的类别往往能获得最佳的表现,而不平衡的类别往往使模型的效果下降。如果训练样本不平衡,可以使用过采样平衡样本之后再训练。
这确实是一个“经验主义”的结论,但多少给我们平常训练CNN模型带来一些启发和帮助。
http://blog.csdn.net/sinat_26917383/article/details/75890859














 2376
2376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









