




如何使用 Ollama 的 API 来创建模型
查询 Blob(Binary Large Object)是否存在
简介
Ollama 提供了一个 RESTful API,允许开发者通过 HTTP 请求与 Ollama 服务进行交互。这个 API 覆盖了所有 Ollama 的核心功能,包括模型管理、运行和监控。本篇将介绍如何调用 Ollama 的 RESTful API 来创建模型。
创建模型
端点:
POST /api/create我们可以从另一个模型、safetensors 目录、GGUF 文件创建模型。如果要从 safetensors 目录或 GGUF 文件创建模型,在此之前必须把各个文件的Blob(Binary Large Object)推送到服务器,然后在请求中的 files 字段中填入其的 blob 关联的文件名和 SHA256 摘要。
参数:
- model:要创建的模型的名称,即 ollama list 当中看到的名字
- from(可选):指的是现有模型的名称,可以是已经在 ollama 当中创建的,也可以是存在于官方当中的模型,如果本地没有会自动去官方库当中搜索下载
- files(可选):这是一个字典,key 为模型的文件名,value 为文件对应的 SHA256 摘要,用于指定用于创建模型的 blob
- adapters(可选):这是一个字典,key 为 LORA 适配器的文件名,value 为文件对应的 SHA256 摘要,把 LORA 适配器应用到基础模型上,实现模型的高效微调
- template(可选):用于定义模型的提示模板
- license(可选):遵循的许可协议相关信息
- system(可选):系统提示
- parameters(可选):这是一个字典,key 为模型参数名,value 为具体的模型参数值,根据这些参数可以对模型进行微调,这些模型参数有 temperature(温度,控制生成文本的随机性和创造性)、top_k(固定挑选最高概率候选词的数量)、top_p(也称核采样,可动态调整候选词的数量)、max_tokens(限制模型生成文本的最大长度)等
- messages(可选):这是一个列表,用于创建对话场景,可以保留以往的聊天记录
- stream(可选):如果设置为 false,响应将作为单个响应对象返回,而对象流
- quantize(可选):量化类型,用于控制非量化模型的量化规模,例如可从高精度数据类型(例如,float32、float16)转换为低精度数据类型(例如,int8)
不同量化类型及推荐:
目前量化的类型有 q2_K、q3_K_L、q3_K_M、q3_K_S、q4_0、q4_1、q4_K_M、q4_K_S、q5_0、q5_1、q5_K_M、q5_K_S、q6_K、q8_0;推荐把非量化版本的模型量化为 q4_K_M 或 q8_0,这两个类型的量化可以在减少内存占用的同时保留较好的性能。
创建模型的示例
一、创建新模型
从现有的模型(在 ollama list 或者在官方库当中的模型)当中创建新模型。
请求:
curl http://localhost:11434/api/create -d '{
"model": "mario",
"from": "llama3.2",
"system": "You are Mario from Super Mario Bros."
}'响应:
{"status":"using existing layer sha256:dde5aa3fc5ffc17176b5e8bdc82f587b24b2678c6c66101bf7da77af9f7ccdff"}
{"status":"using existing layer sha256:966de95ca8a62200913e3f8bfbf84c8494536f1b94b49166851e76644e966396"}
{"status":"using existing layer sha256:fcc5a6bec9daf9b561a68827b67ab6088e1dba9d1fa2a50d7bbcc8384e0a265d"}
{"status":"using existing layer sha256:a70ff7e570d97baaf4e62ac6e6ad9975e04caa6d900d3742d37698494479e0cd"}
{"status":"creating new layer sha256:941b69ca7dc2a85c053c38d9e8029c9df6224e545060954fa97587f87c044a64"}
{"status":"using existing layer sha256:56bb8bd477a519ffa694fc449c2413c6f0e1d3b1c88fa7e3c9d88d3ae49d4dcb"}
{"status":"writing manifest"}
{"status":"success"}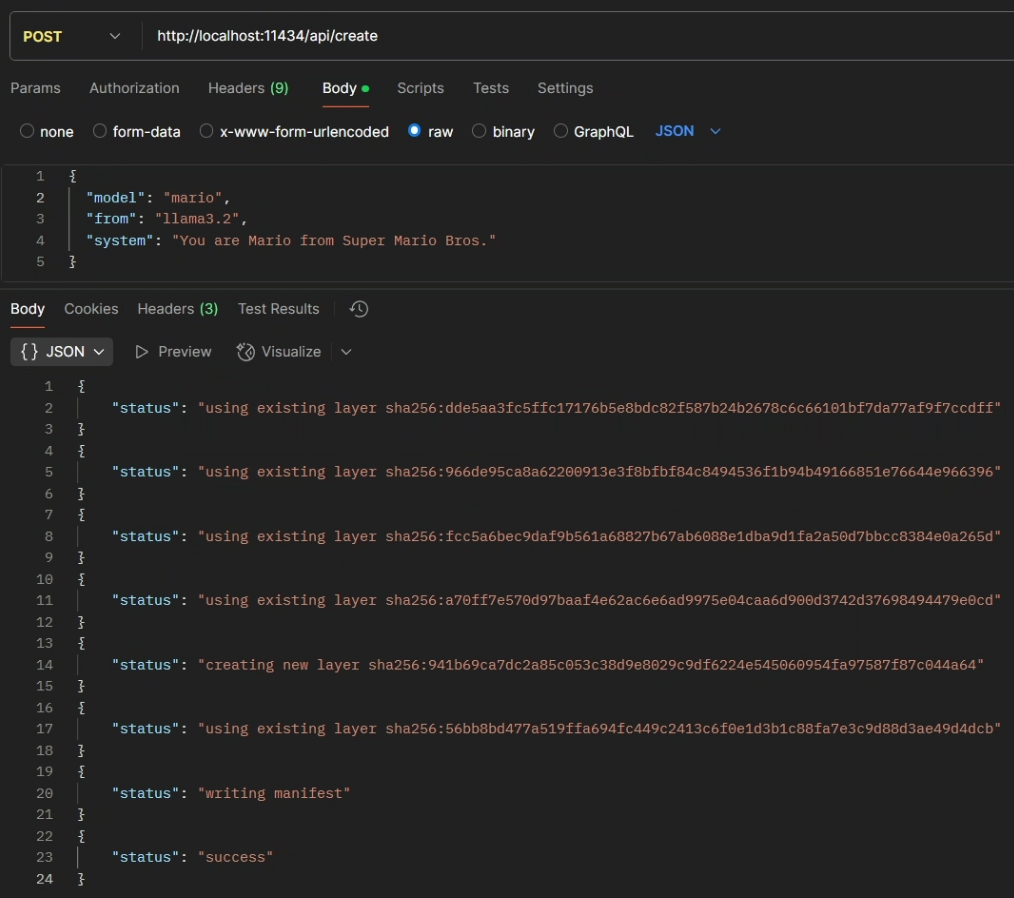
二、量化一个未量化的完整模型
量化模型是一个从高到低的过程,需要先拥有一个高精度的模型,例如,float32、float16 这类高精度模型,本例将会把 llama3.1:8b-instruct-fp16 版本量化为 q4_K_M。
请求:
curl http://localhost:11434/api/create -d '{
"model": "llama3.1:8b-q4_K_M",
"from": "llama3.1:8b-instruct-fp16",
"quantize": "q4_K_M"
}'响应:
{"status":"quantizing F16 model to Q4_K_M"}
{"status":"creating new layer sha256:52006a88ba4cacaab4e6cd53e470402bdd83dc71c99f88623bfecbd42128f011"}
{"status":"using existing layer sha256:948af2743fc78a328dcb3b0f5a31b3d75f415840fdb699e8b1235978392ecf85"}
{"status":"using existing layer sha256:0ba8f0e314b4264dfd19df045cde9d4c394a52474bf92ed6a3de22a4ca31a177"}
{"status":"using existing layer sha256:56bb8bd477a519ffa694fc449c2413c6f0e1d3b1c88fa7e3c9d88d3ae49d4dcb"}
{"status":"writing manifest"}
{"status":"success"}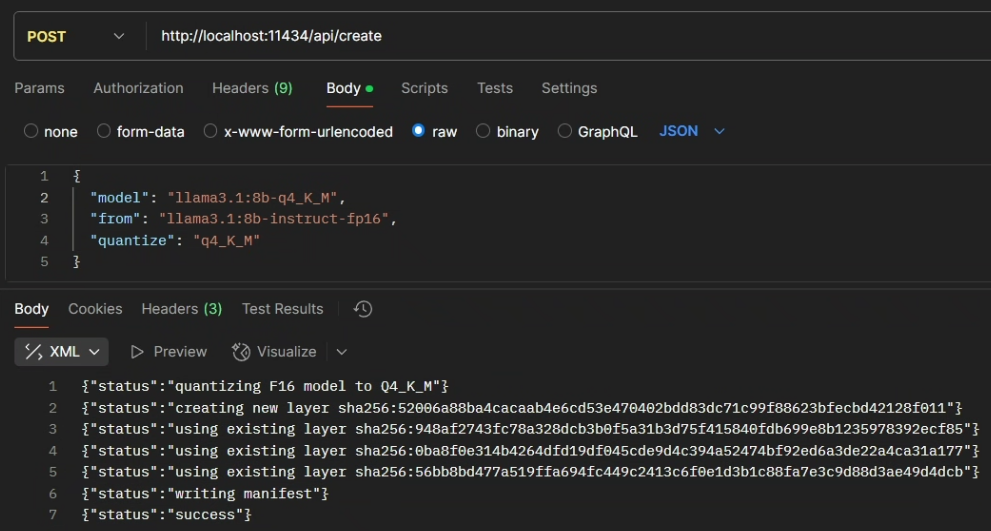
三、从 GGUF 文件创建模型
从 GGUF 文件创建模型需要使用 files 字段,需要把 GGUF 文件的文件名作为 key,GGUF 文件的 SHA256 摘要作为 value 填入 files 字段中。在此之前需要先把 Blob 推送到服务器中,用于完整性验证。
请求:
curl http://localhost:11434/api/create -d '{
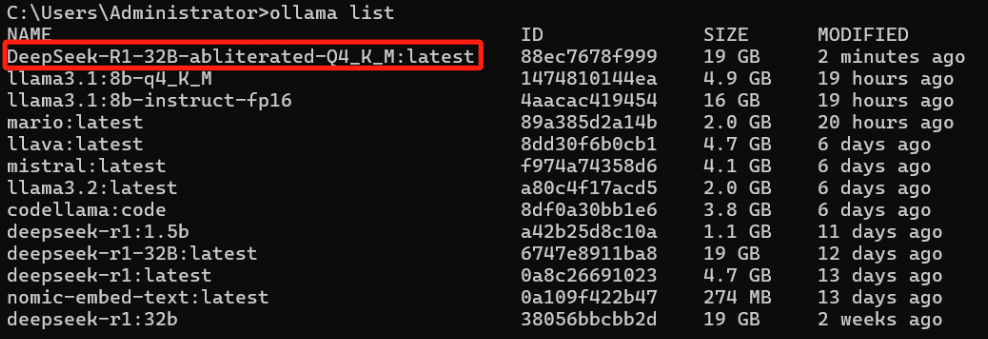
"model": "DeepSeek-R1-32B-abliterated-Q4_K_M",
"files": {
"test.gguf": "sha256:4de296cf59ba595f8695084cd4e0215784baa1c6b02ee9fc26a250be08b7b6a3"
}
}'响应:
{"status":"parsing GGUF"}
{"status":"using existing layer sha256:4de296cf59ba595f8695084cd4e0215784baa1c6b02ee9fc26a250be08b7b6a3"}
{"status":"writing manifest"}
{"status":"success"}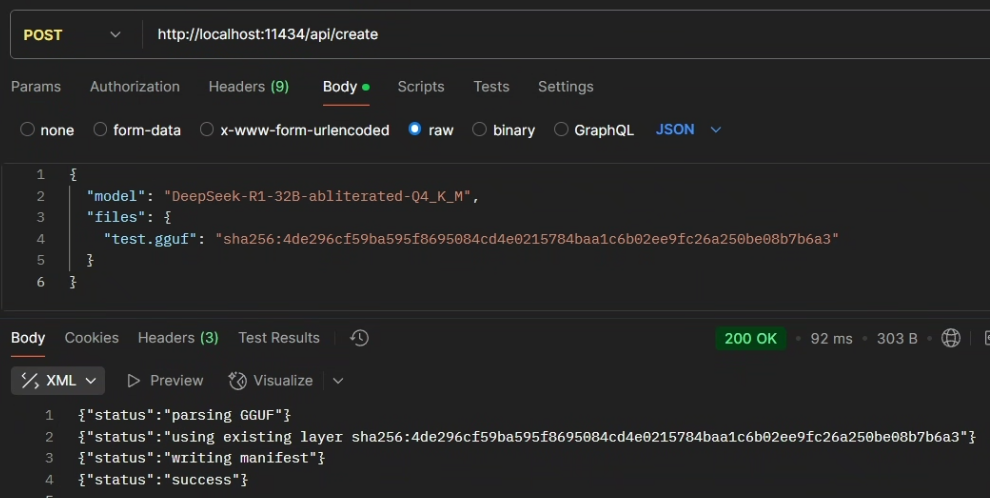
四、从 Safetensors 目录创建模型
与 GGUF 文件创建模型类似,Safetensors 目录创建模型都需要使用 files 字段,key 和 value 分别为 Safetensors 目录中文件的文件名和相应文件的 SHA256 摘要。同样的在调用该 API 之前需要先将每一个文件生成 Blob 推送到服务器中,这些文件会保存在 cache 当中,在服务器重启之后才会清除。
请求:
在发送请求前需要先为每个文件进行哈希得到它们的 SHA256 摘要,我们用 Python 来实现这一操作,代码如下
import hashlib
import os,re
dir_path = r'E:\ChatAI\DeepSeek-R1-Distill-Qwen-1.5B'
list_files = os.listdir(dir_path)
matched_files = []
for file_name in list_files:
if re.search(".*\\.json",file_name) or re.search(".*\\.safetensors",file_name):
matched_files.append(file_name)
try:
for file_name in matched_files:
file_path = os.path.join(dir_path,file_name)
sha256_hash = hashlib.sha256() # 新的文件要清空一下上一个文件传入的哈希
# 以二进制模式打开文件
with open(file_path, "rb") as file:
# 分块读取文件内容,避免一次性加载大文件到内存中
for byte_block in iter(lambda: file.read(4096), b""):
# 更新哈希对象
sha256_hash.update(byte_block)
print("%s: %s" %(file_name,sha256_hash.hexdigest()))
except FileNotFoundError:
print(f"文件 {file_path} 未找到。")
except Exception as e:
print(f"发生错误: {e}")
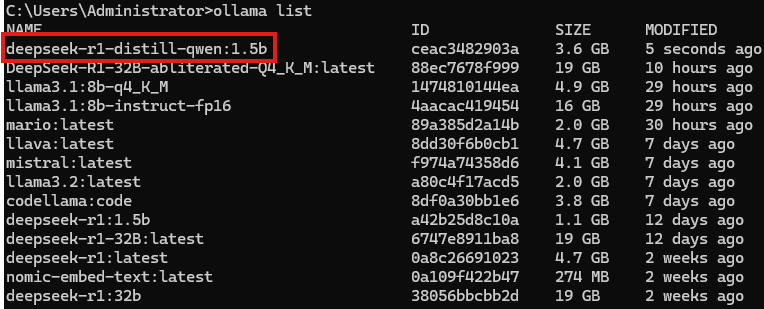
curl http://localhost:11434/api/create -d '{
"model": "deepseek-r1-distill-qwen:1.5b",
"files": {
"config.json": "sha256:91e31a6e6cadfab3b37454eed713f0ba04a560feea71117af7c8b36fba685960",
"generation_config.json": "sha256:7ea7c03a13f41e3343c1427c9286bf69774b766c00be5e991fb759c721b3ba47",
"tokenizer.json": "sha256:b5abcf735404aaa97acc3307bf24116da134a3a33776a60a099af825d329bf7e",
"tokenizer_config.json": "sha256:3f955d042956ab3430de2c344b0804ae5300beec17cb70be1cf35c3d3e499c33",
"model.safetensors": "sha256:58858233513d76b8703e72eed6ce16807b523328188e13329257fb9594462945"
}
}'响应:
{"status":"converting model"}
{"status":"creating new layer sha256:0dc48895db155013d789b285ec2d9888b73be5dfe8ea5621507ab789d36e0b58"}
{"status":"writing manifest"}
{"status":"success"}
查询 Blob(Binary Large Object)是否存在
端口:
HEAD /api/blobs/:digest这个 API 接口可以查询服务器上是否存在相应模型的 blob,使用 GGUF 文件和 Safetensors 目录创建模型前可以用该接口查询一下先。
参数:
- digest:需要查询的 blob 的 SHA256 摘要
示例:
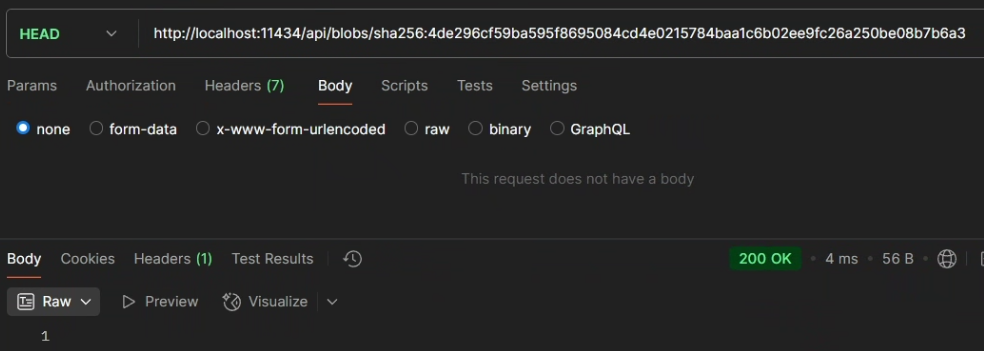
请求:
curl -I http://localhost:11434/api/blobs/sha256:4de296cf59ba595f8695084cd4e0215784baa1c6b02ee9fc26a250be08b7b6a3响应:
如果返回 201 则代表查询成功,blob 存在,如果返回 400(可能是 GGUF 文件的 SHA256 摘要和 digest 不一样导致或者是 blob 根本不存在)则代表查询失败。
推送 Blob 到服务器当中
端口:
POST /api/blobs/:digest这个 API 接口会将一个文件推送到服务器以创建一个 blob。
参数:
- digest:推送文件预生成的 SHA256 摘要,创建模型和查询 blob 是否存在的时候会以该 SHA256 摘要为准
示例:
请求:
在发送请求前我们需要先把 GGUF 文件进行哈希生成 SHA256 的摘要,我们使用下面的 Python 代码来生成
import hashlib
file_path = r'E:\ChatAI\lmstudio\models\DeepSeek-R1-Distill-Qwen-32B-abliterated\DeepSeek-R1-Distill-Qwen-32B-abliterated-Q4_K_M.gguf' # 需要修改为你自己 GGUF 文件的位置
sha256_hash = hashlib.sha256()
try:
# 以二进制模式打开文件
with open(file_path, "rb") as file:
# 分块读取文件内容,避免一次性加载大文件到内存中
for byte_block in iter(lambda: file.read(4096), b""):
# 更新哈希对象
sha256_hash.update(byte_block)
print(sha256_hash.hexdigest())
except FileNotFoundError:
print(f"文件 {file_path} 未找到。")
except Exception as e:
print(f"发生错误: {e}")
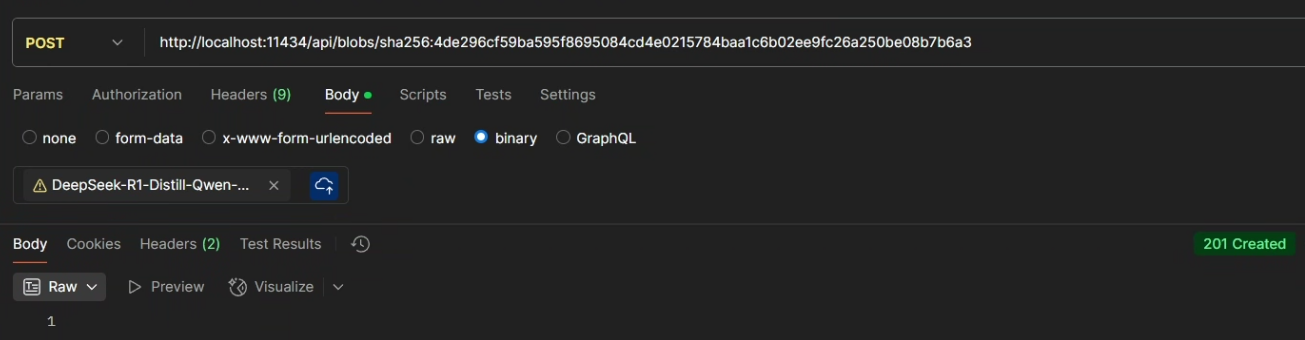
由于文件比较大需要摘要的生成需要一定的时间,生成完成后把 SHA256 摘要复制到 /api/blobs/sha256: 后面
curl -T model.gguf -X POST http://localhost:11434/api/blobs/sha256:4de296cf59ba595f8695084cd4e0215784baa1c6b02ee9fc26a250be08b7b6a3响应:
如果返回 201 则代表创建成功,如果返回 400(很大可能是 GGUF 文件的 SHA256 摘要和 digest 不一样导致的)则代表创建失败。
可以看到在 blobs 目录下已经有该模型的 blob 了



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











