







大数据学习笔记第2课 Zookeeper & Kafka集群搭建
1、环境准备
1、服务器:
个人笔记本电脑:
型号:小米游戏笔记本15.6
处理器:Intel® Core™ i7-7700HQ CPU @ 2.8GHz 2.80 GHz
内存:16.0GB
操作系统:Windows 10 x64
安装vmware workstation pro 12
在vmware中安装三台虚拟机作为服务器(都是1核2线程CPU/2.5G内存)
| 计算机名 | IP地址 | 备注 |
|---|---|---|
| hadoop01 | 172.16.1.153 | zookeeper server & kafka broker |
| hadoop02 | 172.16.1.152 | kafka broker |
| hadoop03 | 172.16.1.154 | kafka broker |
2、虚拟机系统版本:CentOS Linux release 7.5.1804 (Core)
3、修改3台虚拟机服务器的/etc/hosts,内容如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.1.153 hadoop01
172.16.1.152 hadoop02
172.16.1.154 hadoop03
3台虚拟机服务器的/etc/hosts都相同
2、JDK下载与安装
请参考我的另一篇博文《大数据学习笔记第1课 Hadoop基础理论与集群搭建》
3、kafka下载
1、首先进入apache的官网:http://www.apache.org,如下图:

2、选择首页菜单Projects->Project List进入项目列表页面,如下图:
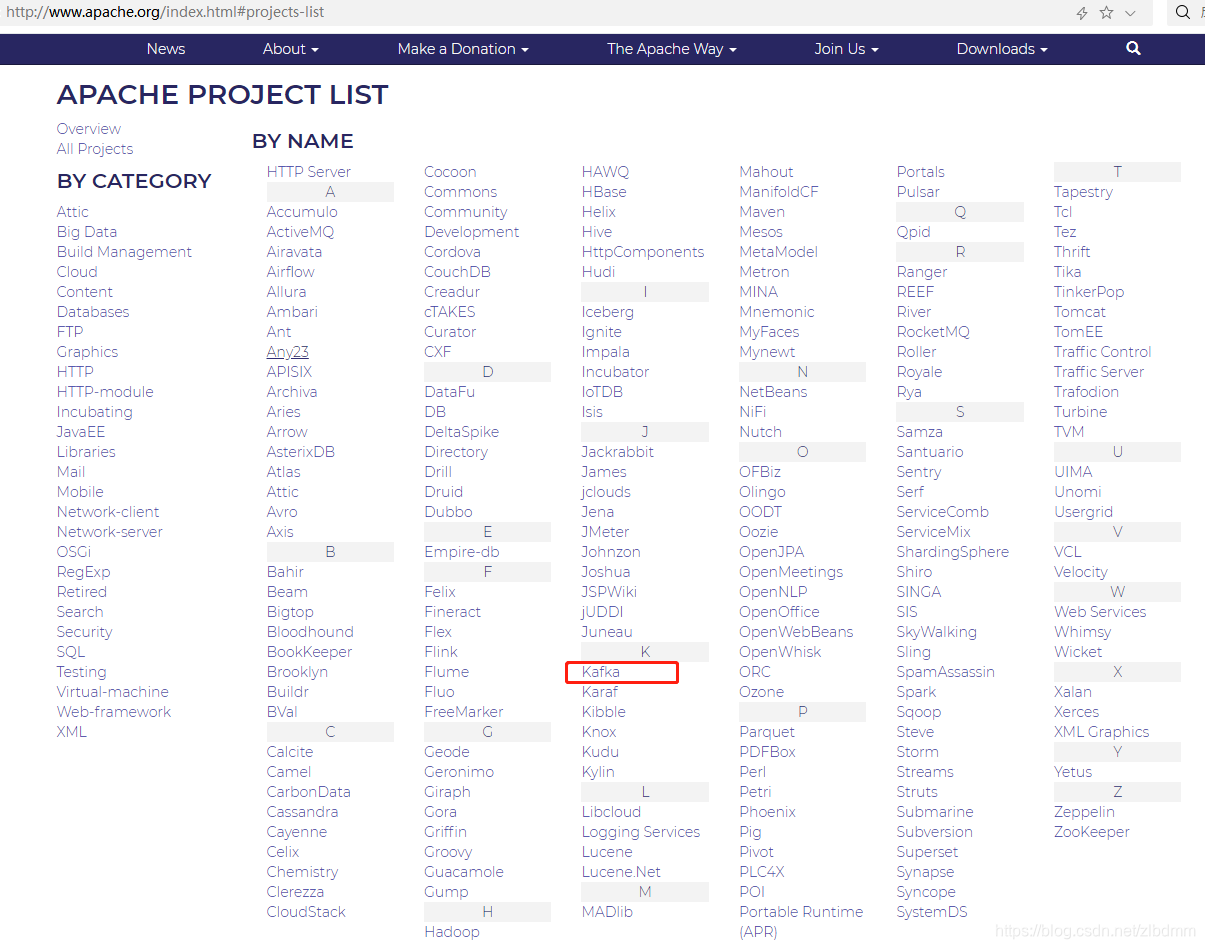
3、在项目列表页面中在K字母开头下找到Kafka,目前就是第一个链接,点击Kafka链接进入Kafka主页,如下图:
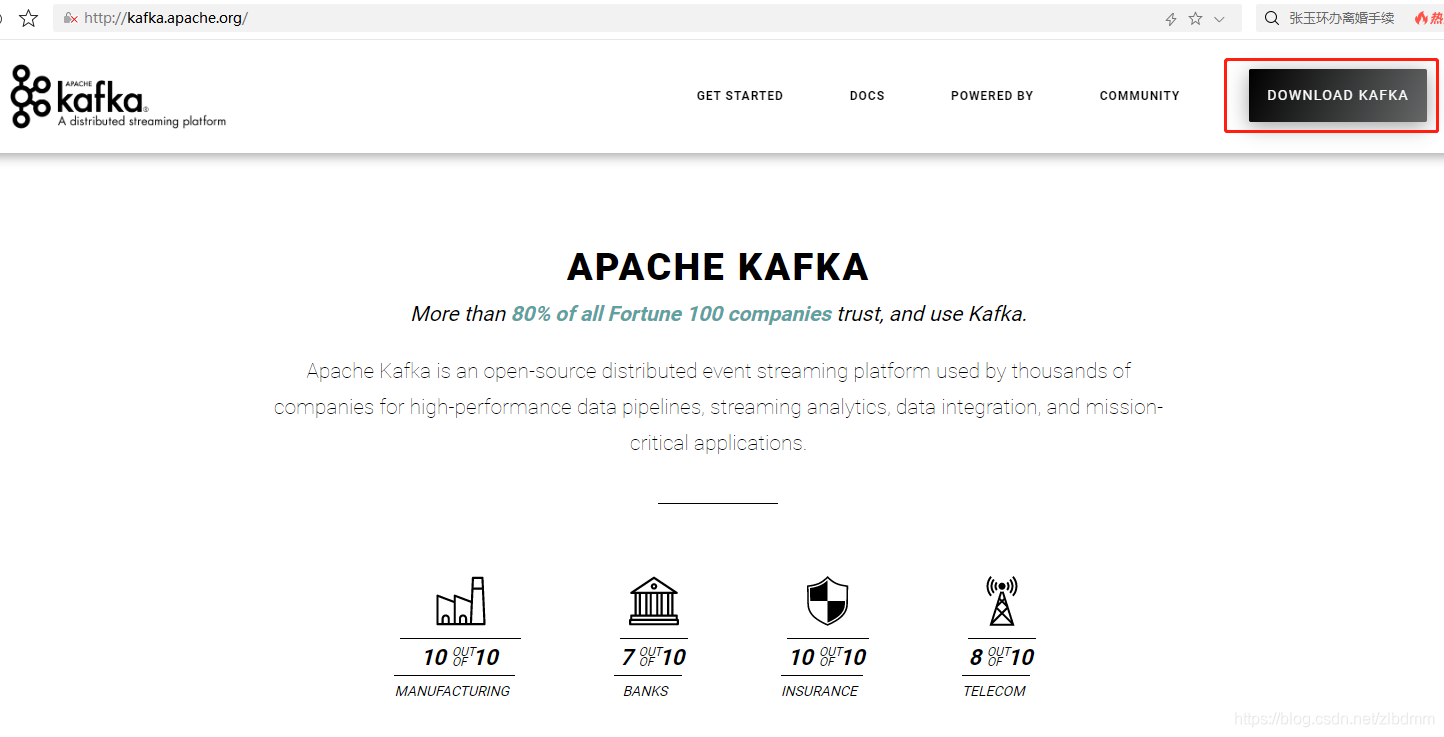
4、点击kafka首页顶部的[DOWNLOAD KAFKA]链接,进入kafka的版本下载页面,如下图:
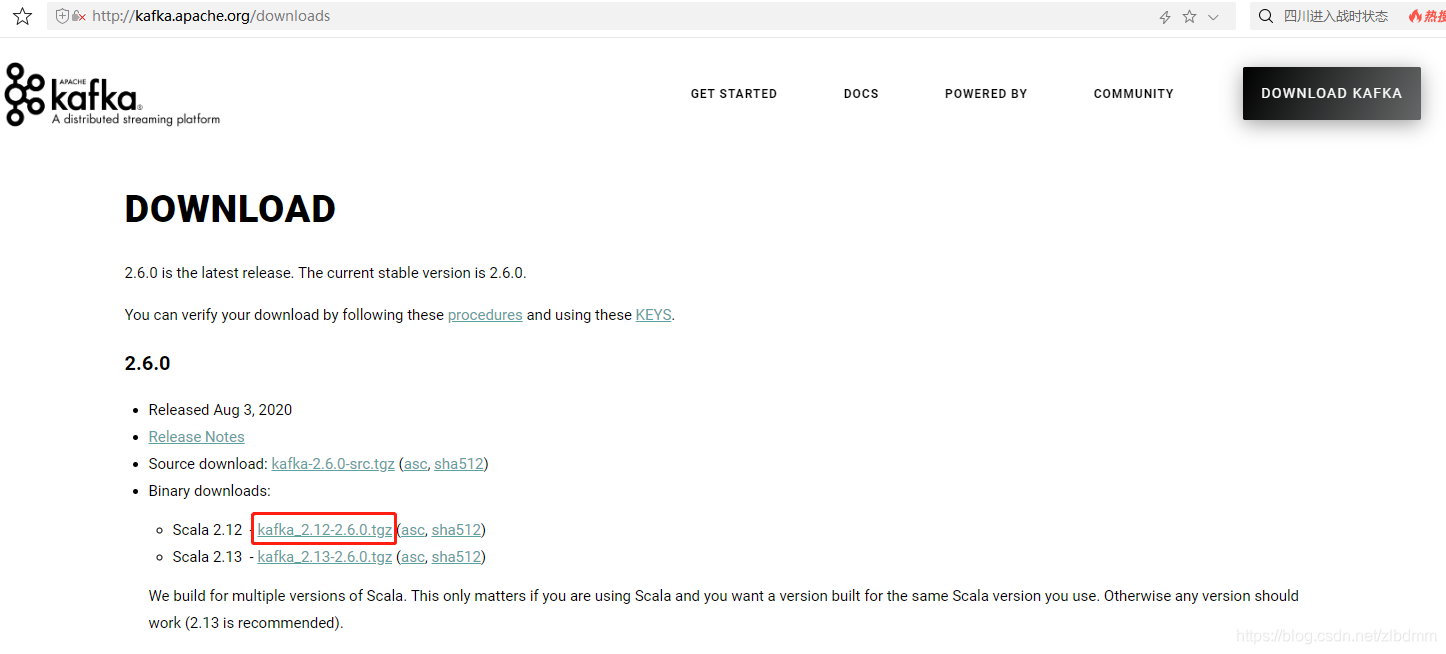
5、点击上图中的二进制下载链接[kafka_2.12-2.6.0.tgz],进入镜像下载地址页面,如下图:
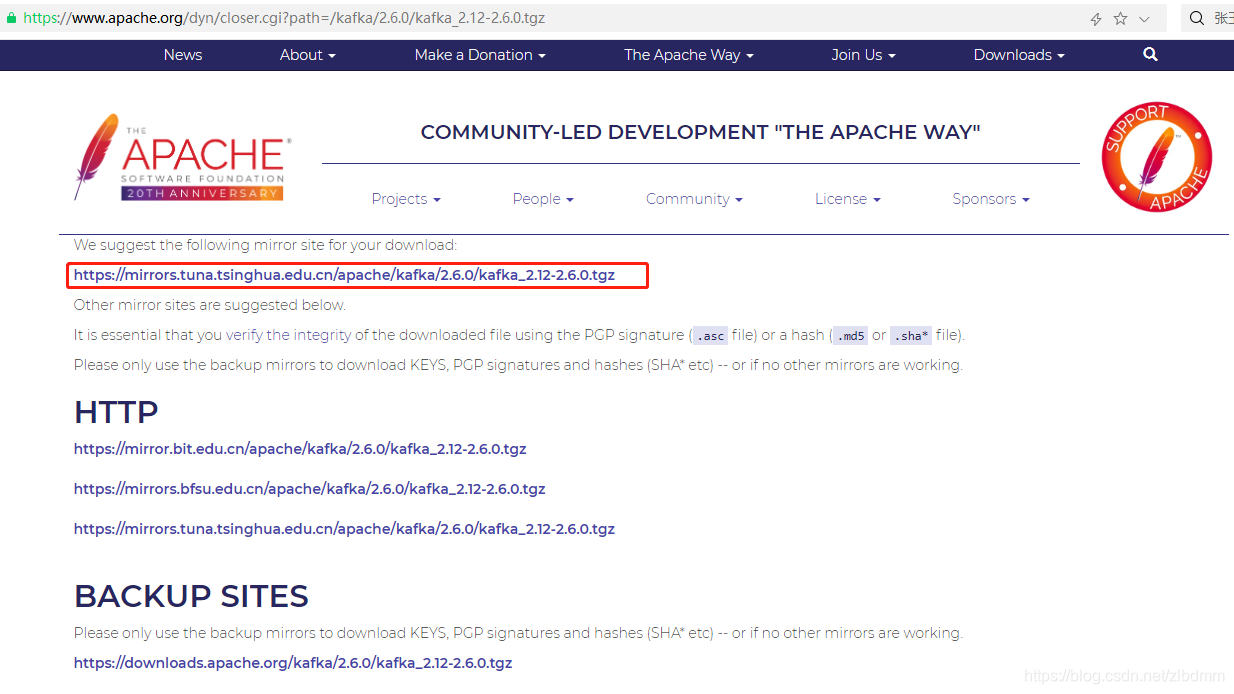
6、复制其中一个下载地址,进入hadoop01的终端界面中,先创建一个目录/opt/soft,并切换当前目录为/opt/soft
mkdir /opt/soft
cd /opt/soft
7、通过wget命令下载kafka至/opt/soft目录下,为了下载速度使用如下链接:
wget https://mirror.bit.edu.cn/apache/kafka/2.6.0/kafka_2.12-2.6.0.tgz
下载过程如下图:

8、通过tar -xzvf命令解压kafka,如下:
tar -xzvf kafka_2.12-2.6.0.tgz
4、zookeeper与kafka安装
1、创建目录/program,如下:
mkdir /program
2、把kafka解压后的/opt/soft/kafka_2.12-2.6.0目录复制到/program/下,如下:
cp -r /opt/soft/kafka_2.12-2.6.0 /program/
3、在hadoop02和hadoop03上也创建/program目录,然后使用scp命令把hadoop01上解压的kafka目录分别复制到hadoop02和hadoop03的/program/目录下,如下:
scp -r /opt/soft/kafka_2.12-2.6.0 root@hadoop02:/program/
scp -r /opt/soft/kafka_2.12-2.6.0 root@hadoop03:/program/
5、在hadoop01上启动zookeeper
1、切换当前目录为/program/kafka_2.12-2.6.0/bin,如下:
cd /program/kafka_2.12-2.6.0/bin
2、执行以下命令已后台方式启动zookeeper服务
nohup ./zookeeper-server-start.sh ../config/zookeeper.properties &
回车后,如下图输出:

命令开头使用nohup,结尾加&是后台执行命令的格式。目的是防止Ctrl+C终止、终端关闭、用户退出导致的服务自动停止。
这里最好记住后台运行服务的进程号方便有问题时直接结束进程,上图中的进程号为:11325
8、通过端口占用分析zookeeper服务是否正常启动,如下:
netstat -antp | grep 2181
输出如下图:

zookeeper服务默认占用2181端口,上图中说明2181端口处于侦听状态,证明zookeeper服务正常启动。
在这个集群案例只需要1台zookeeper服务就行,hadoop02和hadoop03不需要再启动zookeeper服务。
6、在hadoop01、hadoop02、hadoop03上启动kafka
1、启动kafka服务之前首先需要修改/program/kafka_2.12-2.6.0/config/server.properties中的信息。
2、主要是修改/program/kafka_2.12-2.6.0/config/server.properties中的2个信息,一个是broker.id=0的值,hadoop02和hadoop03中这个值要各不相同,且小于1000,另外一个就是3台服务器配置文件中的zookeeper.connect=172.16.1.153:2182值要相同,都指向hadoop01的zookeeper服务地址及端口。如下:
broker.id=0 #小于1000,且hadoop01、hadoop02、hadoop03的配置的值要不同
zookeeper.connect=172.16.1.153:2182 #hadoop01、hadoop02、hadoop03的配置的值相同,都指向hadoop01中zookeeper服务地址和端口号
3、分别进入hadoop01、hadoop02、hadoop03终端的/program/kafka_2.12-2.6.0/bin目录,通过一下命令后台启动kafka服务。
nohup ./kafka-server-start.sh ../config/server.properties &
执行输出如下:



上图是3台服务器启动kafka服务的输出,最好能记录各自的进程ID,方便有问题时终止进程。
4、通过端口占用或jps命令分析kafka服务是否正常启动,如下:
netstat -antp | grep 9092
jps
如下图输出
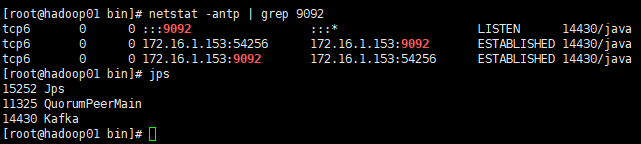


上图中9092端口都处于侦听状态,因此kafka服务正常启动,说明kafka集群搭建成功。
5、通过zookeeper-shell.sh查看运行的broker,如下:
./zookeeper-shell.sh hadoop01:2181
如下输出
在zookeeper-shell命令中通过ls /brokers/ids,查看启动的broker.id的值列表,如下图:
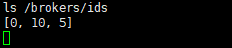
这样也能证明3台kafka服务器启动成功了。Ctrl+C可以退出zookeeper-shell。
7、创建topic
topic是用户隔离消息的,只要通过kafka进行消息操作就需要指定topic,因此创建topic就是使用kafka的第一步操作。
1、通过/program/kafka_2.12-2.6.0/bin/kafka-topics.sh创建topic,如下:
./kafka-topics.sh --create --zookeeper hadoop01:2181 --topic qingdao --partitions 3 --replication-factor 3
执行结果如下图:

上图说明成功创建了一个名为qingdao的topic
- –zookeeper hadoop01:2181 指定zookeeper服务地址
- –topic 主题,隔离消息
- –partitions 消息流分割成几部分(分隔消息流增大吞吐量,应根据消息生产者的生产量调整此值)
- –replication-factor 每个消息的副本数(备份用的,同时只有1个副本在工作)
2、通过zookeeper-shell查看创建的topic,同样先通过以下命令进入zookeeper-shell。
../zookeeper-shell.sh hadoop01:2181
然后使用ls /brokers/topics查看创建的topic,如下图:
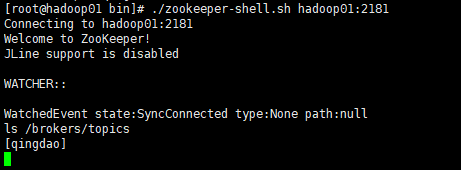
上图中已经列出了qingdao,说明topic创建成功。Ctrl+C退出zookeeper-shell。
3、也可以通过kafka-topic.sh查看已经创建的topic,如下:
./kafka-topics.sh --list --zookeeper hadoop01:2181
输出如下图:

也说明topic创建成功。
8、生产Message
1、通过kafka-console-producer.sh启动消息生产控制台,如下在hadoop01中执行:
./kafka-console-producer.sh --bootstrap-server hadoop01:9092 --topic qingdao
9、消费Message
1、通过kafka-console-consumer.sh启动消费消息控制台,如下在hadoop02中执行:
./kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic qingdao
10、模拟发送消息至kafka
1、在hadoop01启动的消息生产控制台中输入任意消息回车测试。如下图:

2、同时在hadoop02启动的消费消息控制台中就能看到对应的消息,如下图:

结束语
至此一个简单的Kafka集群搭建完毕。希望对初学的朋友能有个参考。最后感谢一下csdn大数据的老师吧,毕竟有个人带着学要快的多。如果觉得有帮助点个赞吧~














 5383
5383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









