









如果数据很庞大的情况,估计没有人会直接使用
select * from table ;
select * from table limit 1000000;之类的SQL语句,这样的操作别说数据库的操作很慢了,在网络IO传输也是一个很大的问题,
把一千万的数据读取出来在网络进行传输,这样性能消耗也会有瓶颈。
所以,读取大批量的数据一般都是采用分批次的读取方式。
(一)通过测试,一万条数据一次性读取出来所花费的时间要比分十次,每次读1千数据的速度要慢很多。
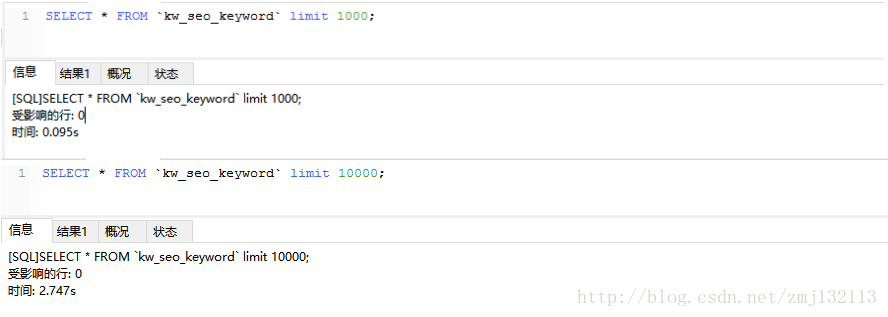
从上面的两张截图可以看出,执行limit1000的时候,所用的时间是0.095s,读十次,顶多也不到1s。
但是,执行limit 10000的时候,所用的时间是2.747s。差不多是3倍的时间。
(二),主键是uuid,可以进行排序,利用排序和比较值的大小来分批读取数据。
SELECT * FROM `kw_seo_keyword` as t
WHERE t.id > '31baf874-0fc5-4bb0-82ff-7bc77c6b63f5'
ORDER BY t.id
LIMIT 1000每一次,读取一千条数据,然后取这一千条数据的有序集合的最后一条数据的id,在进行大小的比较。如此反复,直到数据读取完为止。
(三),安全性的考虑,执行上千万的数据,有时候程序出现异常,结果修改异常后再重新这上千万的数据,那就太蛋疼了。所以我们分批次处理数据的时候。
比如说,我们每次读取一千条数据,等集合的数据超过100万的时候,就处理数据,然后通过一个redis的key来保存最后一次的id。
while (!isFinish) {
try {
while (true) {
queryMap.put("id", id);
tempSeoKeywordList = seoKeywordMapper.getUnAggregateCharactWords(queryMap);
if (tempSeoKeywordList == null || tempSeoKeywordList.size() == 0) {
isFinish = true;
break;
}
for (SeoKeyword seoKeyword : tempSeoKeywordList) {
crawlerKeyword = new CrawlerKeyword();
crawlerKeyword.setKeywordId(seoKeyword.getId());
crawlerKeyword.setKeyword(seoKeyword.getKeyword());
crawlerKeyword.setPageNumber(1);
seoKeywordList.add(crawlerKeyword);
}
id = tempSeoKeywordList.get(tempSeoKeywordList.size() - 1).getId();
if (seoKeywordList.size() == 1000000) break;
}
if (seoKeywordList.size() != 0) {
CrawlingTask crawlingTask = new CrawlingTask().setTaskId(StringUtil.uuid()).setProtos(seoKeywordList);
TaskDirector.submitTask(QueueClientHelper.queue_kw_wapbaidu_agg, crawlingTask);
redisUtil.set(RedisKey.Prefix.LAST_COMPLETE_AGG_ID, ((CrawlerKeyword) seoKeywordList.get(seoKeywordList.size() - 1)).getKeywordId());
seoKeywordList.clear();
}
} catch (Exception e) {
isFinish = true;
logger.info("聚合特征词扔到爬虫队列任务执行失败------");
e.printStackTrace();
}
}附上,最近做的项目的代码作为例子。














 3746
3746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









