









为什么要异步I/O
在跨网络结构下,I/O具体到实处可以从用户体验和资源分配两方面说起。
用户体验
- 采用异步请求,在下载资源期间,JavaScript和UI的执行都不会处于等待状态,可以继续响应用户的交互行为。
- 同步与异步时间消耗对比,前者时间为M+N,后者为max(M+N)
同步代码如下:
// 消耗时间为M getData('from_db'); // 消耗时间为N getData('from_remote_api');异步代码如下:
getData('from_db', function(result) { // 消费时间为M }); getData('from_remote_api', function(result) { // 消费时间为N });__随着应用复杂性的增加,情景将会变成M+N+…
用图表对比看看CPU一级缓存到网络的数据访问所需要的开销,I/O是昂贵的,分布式I/O是更加昂贵
CPU时钟周期:通常为节拍脉冲或T周期,既主频的倒数,它是处理操作的最基本单位
I/O类型 花费的CPU时钟周期 CPU一级缓存 3 CPU二级缓存 14 内存 250 硬盘 41000000 网络 240000000 资源分配
假设业务场景中有一组互不相关的任务需要完成,现行的主流方法有以下两种:
- 单线程串行依次执行;
- 多线程并行完成。
多线程的代价在于创建线程和执行期线程上下文切换的开销较大,在复杂的业务中,多线程编程经常面临锁、状态同步问题
单线程顺序执行任务的方式比较符合编程人员按顺序思考的思维方式,缺点在于性能,任意一个略慢的任务都会导致后续执行代码被阻塞
添加硬件资源是一种提升服务质量的方式,消耗物理资源大
node在以上问题给了一套解决方案:利用单线程,远离多线程死锁、状态同步等问题;利用异步I/O,让单线程原理阻塞,更好地使用CPU
为了弥补单线程无法利用多核CPU的缺点,Node提供了类似前端浏览器中Web Workers的子进程,该子进程可以通过工作进程高效地利用CPU和I/O。
异步I/O的提出是期望I/O调用不再阻塞后续运算,将原有等待I/O完成的这段时间分配给其余需要的业务去执行。
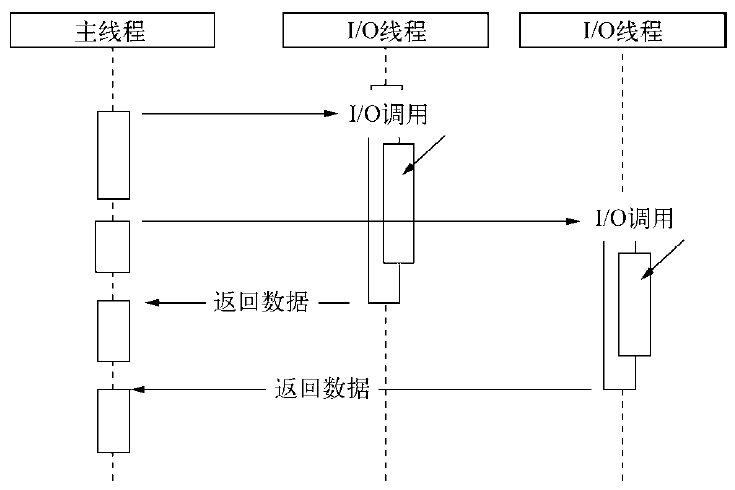
图3-1为异步I/O的调用示意图
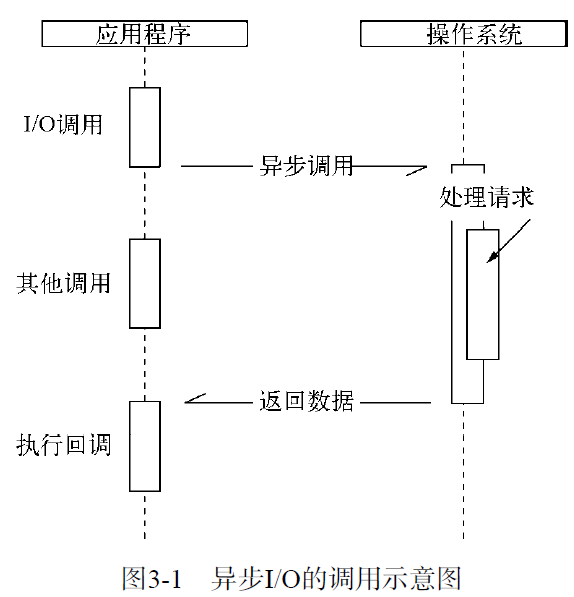
异步I/O实现现状
异步I/O在Node中应用最为广泛,但是它并非Node原创。
异步I/O与非阻塞I/O
操作系统内核对于I/O只有两种方式:阻塞与非阻塞。在调用阻塞I/O时,应用程序需要等待I/O完成才返回结果。如下图:
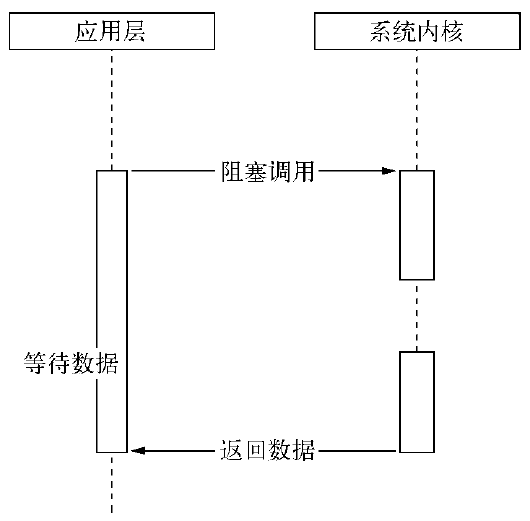
阻塞I/O一个特点:调用之后一定要等到系统内核层面完成所有操作后,调用才结束。比如磁盘I/O,系统内核在完成磁盘寻道、读取数据、复制数据到内存中之后,这个调用才结束。
阻塞I/O造成CPU等待I/O,浪费等待时间,CPU的处理能力不能得到充分利用。为了提高性能,内核提供了非阻塞I/O。非阻塞I/O跟阻塞I/O的差别为调用之后会立即返回,如下图:
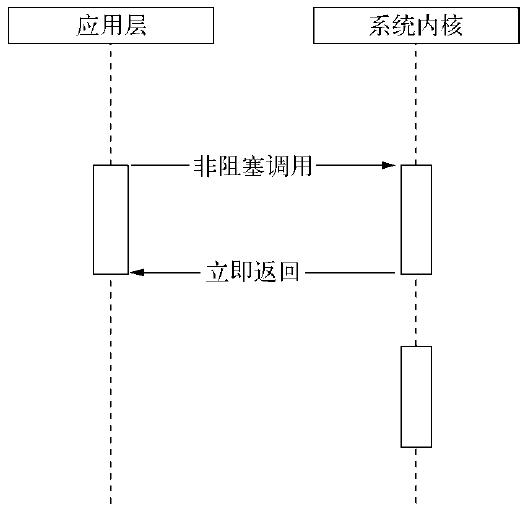
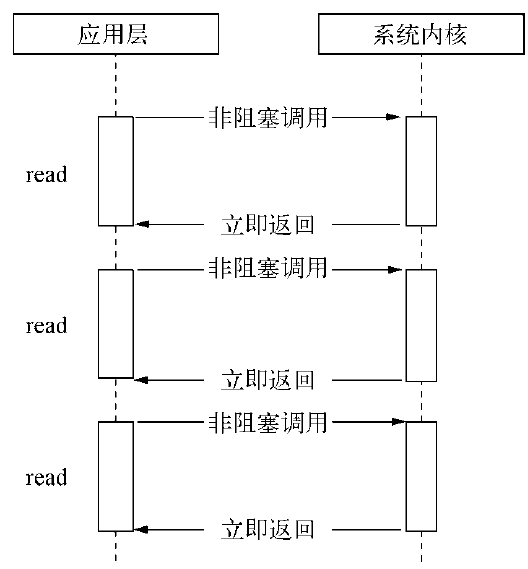
非阻塞I/O为了获取完整的数据,应用程序需要重复调用I/O操作来确认是否完成。这种重复调用判断操作是否完成的技术叫做轮询。轮询技术演进以减少I/O状态判断的CPU损耗。
read。它是最原始、性能最低的一种,通过重复调用来检查I/O的状态来完成完整数据的读取。在得到最终数据前,CPU一直耗用在等待上。
select。它是在read的基础上改进的一种方案,通过对文件描述符上的事件状态来进行判断。(最多同时检查1024个文件描述符)
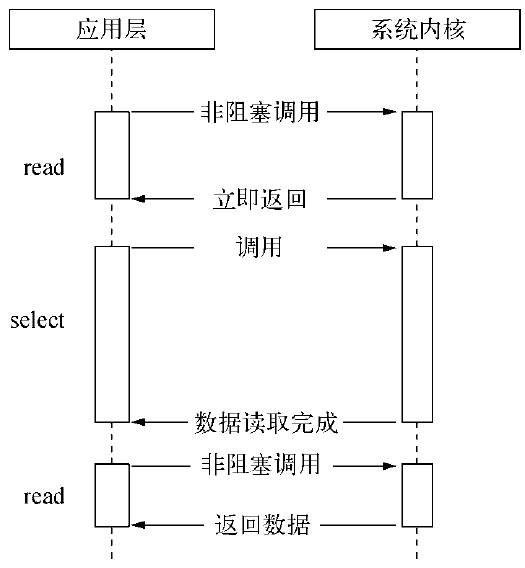
poll。该方案较select有所改进,采用链表的方式避免数组长度的限制,其次它能避免不需要的检查。
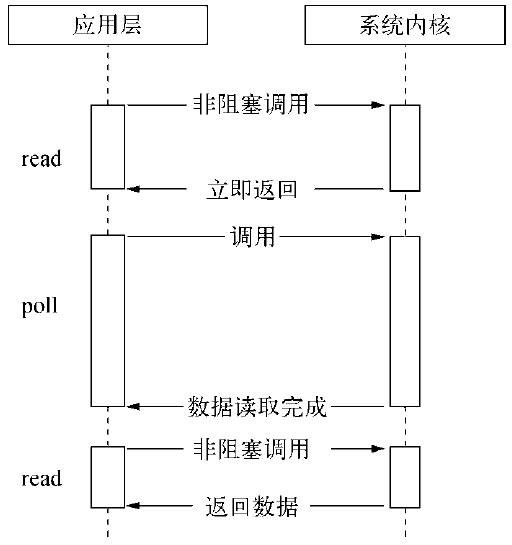
epoll。该方案是Linux下效率最高的I/O事件通知机制,在进入轮询的时候如果没有检查到I/O事件,将会进行休眠,直到事件发生将它唤醒。它是真实利用了事件通知、执行回调的方式,而不是遍历查询,所以不会浪费CPU,执行效率较高。
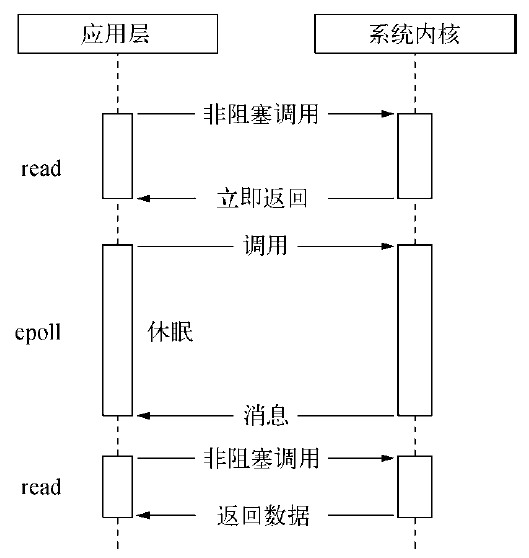
kqueue。和epoll类似,不过仅在FreeBSD系统下存在。
理想的非阻塞异步I/O
尽管epoll已经利用了事件来降低CPU的耗用,但是休眠期间CPU几乎是闲置的,I对于当前线程而言利用率不够。
完美的异步I/O技术是无序通过遍历或者事件唤醒等方式轮询,可以直接处理下一个任务,只需在I/O完成后通过信号或回调将数据传递给应用程序即可
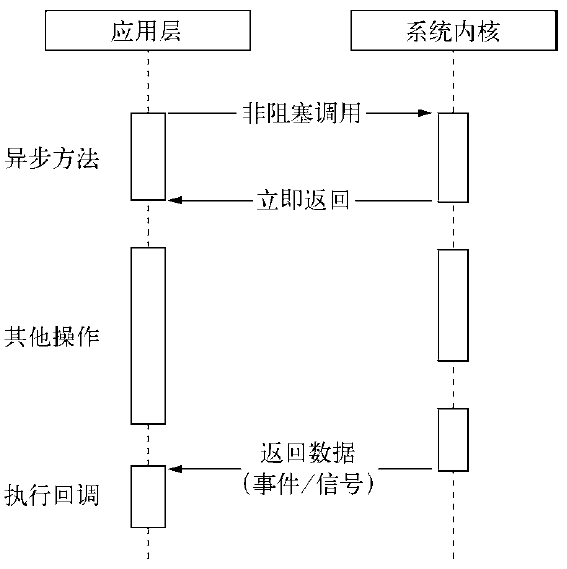
linux原生提供一种异步I/O方式(AIO)通过信号或回调来传递数据,AIO仅支持内核I/O的O_DIRECT方式读取,导致无法利用系统缓存
现实的异步I/O
多线程I/O,部分线程进行阻塞I/O或者非阻塞I/O加轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将I/O得到的数据进行传递。
glibc的AIO便是典型的线程池模拟异步I/O。在Node v0.9.3自行实现了线程池来完成异步I/O。IOCP的异步I/O模型与Node的异步调用模型十分近似。在windows平台下采用了IOCP实现异步I/O。
Node提供了libuv作为抽象封装层,使得所有平台兼容性的判断都由这一层来完成,并保证上层的Node与下层的自定义线程池及IOCP之间各自独立。Node在编译期间会判断平台条件,选择性编译unix目录或是win目录下的源文件到目标程序中,如下图:
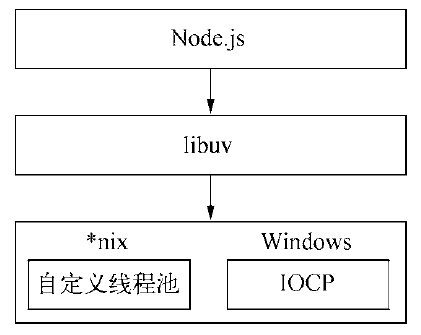
I/O不仅仅限于磁盘文件的读写,*nix经过抽象,磁盘文件、硬件、套接字等几乎都被抽象为文件,Node单线程仅仅只是js执行在单线程,无论在*nix还是windows平台,内部完成I/O任务另有线程池
Node的异步I/O
Node整个异步I/O环节的有事件循环、观察者和请求对象等。
事件循环
- Node自身执行模型——事件循环
进程启动时,node便会创建一个类似于while(true)的循环,每执行一次循环体的过程称为Tick。每个Tick过程就是查看是否有事件待处理,直到不再有事件处理,就退出进程。
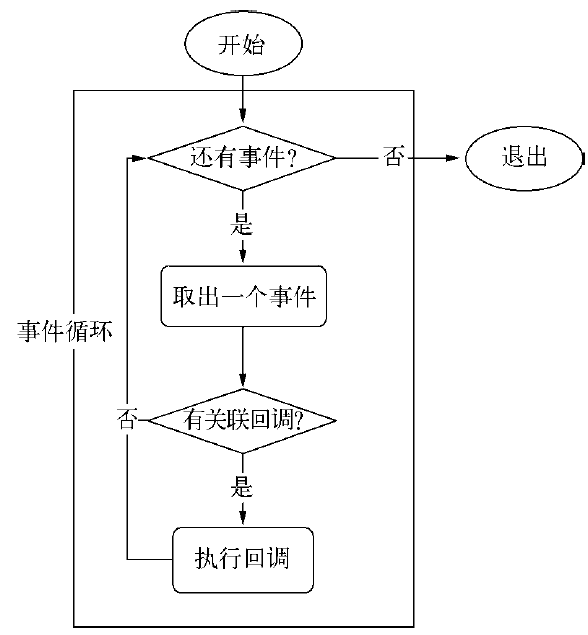
观察者
- 在每个Tick过程中,如何判断是否有事件需要处理呢?这里必须要引入的概念是观察者。
在Node中,事件主要来自网络请求、文件I/O等,这些事件对应的观察者有文件I/O观察者、网络I/O观察者。
事件循环是一个典型的生产者/消费者模型。异步I/O、网络请求等则是事件的生产者,源源不断为Node提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。window下循环基于IOCP创建,在linux下则基于多线程创建。
请求对象
对于Node中异步I/O调用,事实上从JS发起调用到内核执行完I/O操作的过渡过程中,存在一种中间产物,叫请求对象。
- 以fs.open()来做例子,分析Node与底层之间是如何执行异步I/O调用以及如何执行回调函数
fs.open = function(path, flags, mode, callback) { // ... binding.open(pathModule._makeLong(path), stringToFlags(flags), mode, callback); }fs.open根据指定路径和参数去打开一个文件,从而得到一个文件描述符,这是后续所有I/O的初始操作。JS调用C++核心模块进行下层操作。调用示意图如下:
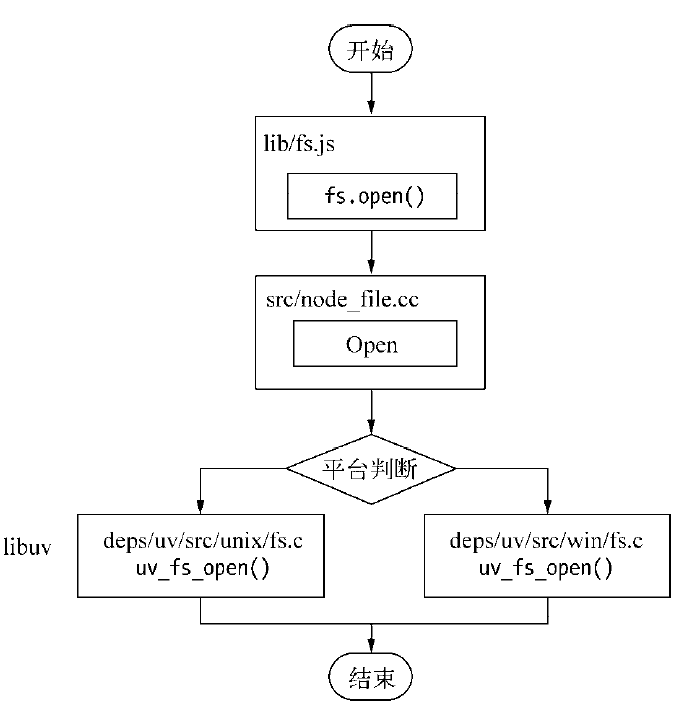
Node经典调用js->调用Node核心模块->调用C++内建模块->通过libuv进行系统调用
libuv作为封装层,实质上调用uv_fs_open方法,在uv_fs_open调用过程中,创建一个FSReqWrap请求对象,js传入的参数和当前方法都被封装在这个请求对象中,回调函数在oncomplete_sym属性上:
req_wrap->object_->Set(oncomplete_sym, callback);- 对象包装完毕后,在window下调用QueueUserWorkItem()方法将FSReqWrap对象推入线程池中等待执行
QueueUserWorkItem(&uv_fs_thread_proc, req, WT_EXECUTEDEFAULT);第一个参数是将要执行的方法的引用,这里引用的是uv_fs_thread_proc,第二个参数是uv_fs_thread_proc运行所需要的参数,第三个参数是执行的标志。当线程池中有可用线程时,我们会调用uv_fs_thread_proc()方法。uv_fs_thread_proc()方法会根据传入参数的类型调用相应的底层函数。以uv_fs_open()为例,实际上调用fs__open()方法
至此,js调用立即返回,js层面发起的异步调用的第一阶段就此结束。js线程可以继续执行当前任务的后续操作。当前的I/O操作在线程池中等待执行,不管它是否阻塞I/O,都不会影响到js线程的后续执行
- 请求对象是异步I/O过程中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程池等待执行以及I/O操作完毕后的回调处理。
执行回调
- 组装好请求对象,送入I/O线程池等待执行,实际上完成了异步I/O的第一步,回调通知为第二步。
- 线程池中的I/O操作调用完毕之后,会将获取的结果储存在req->result属性上,然后调用PostQueuedCompletionStatus()通知IOCP
- PostQueuedCompletionStatus()方法的作用是向IOCP提交执行状态,通过GetQueuedCompletionStatus()提取,并将线程归还线程池。
- 过程中,还动用了事件循环的I/O观察者。在每次Tick的执行中,它会调用IOCP相关的GetQueuedCompletionStatus()方法检查线程池中是否有执行完的请求,如果存在,会将请求对象加入到I/O观察者的队列中,然后将其当作事件处理。
整个异步I/O流程图
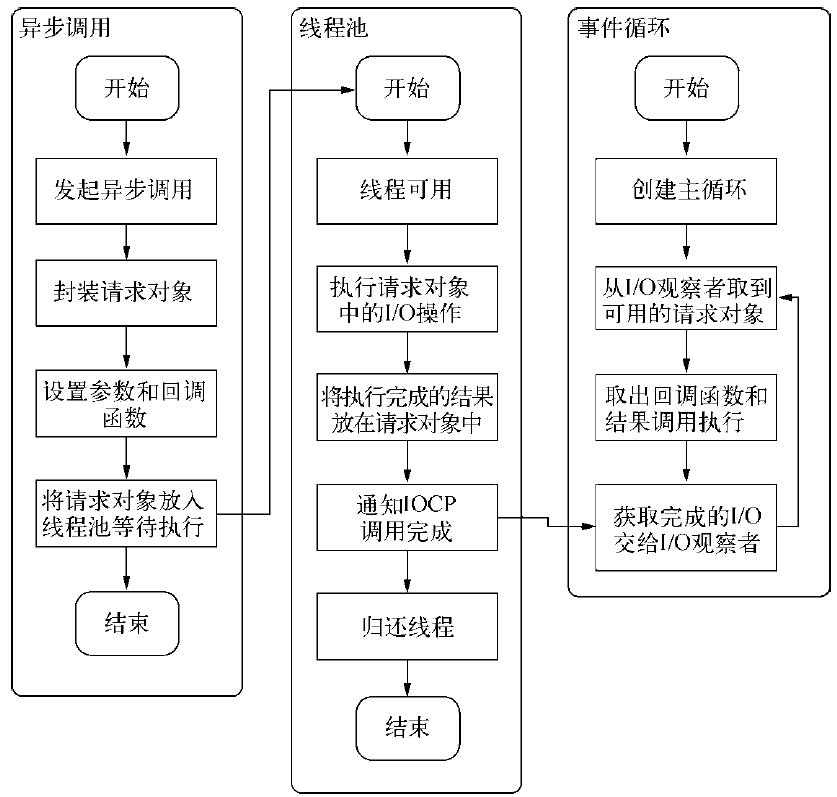
- 事件循环、观察者、请求对象、I/O线程池这四者共同构成了Node异步I/O模型的基本要素。
小结
- JS是单线程的,很容易理解为它不能充分利用多核CPU。事实上,在Node中,Node自身其实是多线程的,只是I/O线程使用的CPU较少。另一个需要重视观点,除用户代码无法并行执行外,所有的I/O(磁盘I/O和网络I/O等)则是可以并行起来。
非I/O的异步API
Node存在一些与I/O无关的异步API,分别是setTimeout()、setInterval()、setImmediate()和process.nextTick()。
定时器
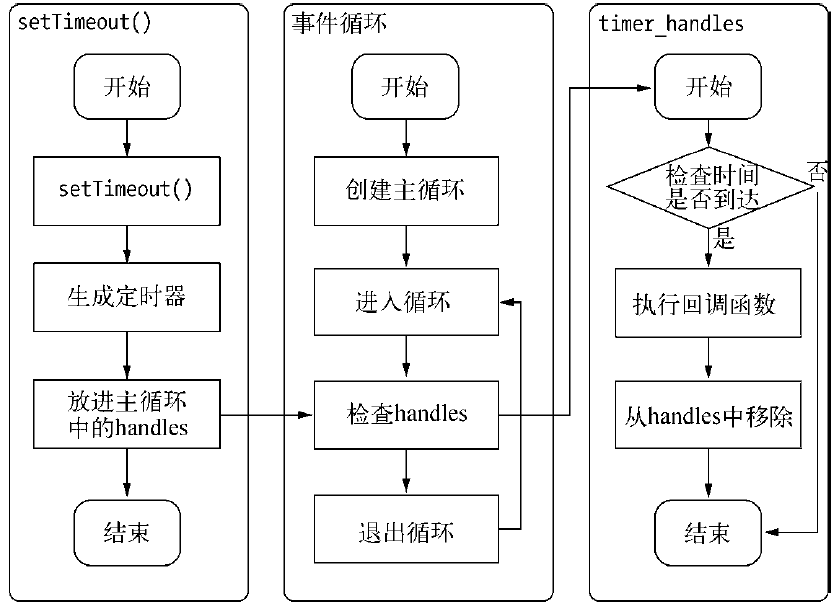
- setTimeout()和setInterval()与浏览器中的API是一致的,分别用于单次和多次定时执行任务。与异步I/O比较类似,只是不需要I/O线程池的参与。调用setTimeout()或setInterval()创建的定时器会被插入到定时器观察者内部的一个红黑树中。每次Tick执行时,会从该红黑树中迭代取出定时器对象,检查是否超过定时时间,如果超过,就形成一个事件,它的回调函数将立即执行。
定时器的问题在于,它并非精确的(在容忍范围内)。如果某次循环占用时间较多,下次循环时,就已经超时很久了。
setTimeout()执行流程图如下:
process.nextTick()
- 相比seTimeout操作相对较为轻量,具体代码如下:
process.nextTick = function(callback) { if (process._exiting) { return; } if (tickDepth >= process.maxTickDepth) { maxTickWarn(); } var tock = { callback: callback }; if (process.domain) { tock.domain = process.domain; } nextTickQueue.push(tock); if (nextTickQueue.length) { process._needTickCallback(); } }每次调用process.nextTick()方法,只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器中采用红黑树的操作时间复杂度为O(lg(n)),nextTick()的时间复杂度为O(1)。相较之下,process.nextTick()更高效
setImmediate()
setImmediate()方法与process.nextTick()方法十分类似,都是将回调函数延迟执行。不过之间有细微差别。
process.nextTick(function() { console.log('nextTick延迟执行'); }); setImmediate(function() { console.log('setImmediate延迟执行'); }); console.log('正常执行');执行结果
正常执行 nextTick延迟执行 setImmediate延迟执行process.nextTick()属于idle观察者,setImmediate()属于check观察者,在每一个轮询检查中,idle观察者先于I/O观察者,I/O观察者先于check观察者。
process.nextTick()回调函数保存在一个数组中,setImmediate()的结果则是保存在链表中。在行为上,process.nextTick()在每轮循环中会将数组中的回调函数全部执行完。而setImmediate()在每轮循环中执行链表中的一个回调函数。
当第一个setImmediate()的回调函数执行后,并没有立即执行第二个,主要是为了保证每轮循环能够较快地执行结束,防止CPU占用过多而阻塞后续I/O调用的情况。
事件驱动与高性能服务器
尽管本章只用了fs.open()方法作为例子来阐述Node如何实现异步I/O,而实质上,异步I/O不仅仅应用在文件操作中。对于网络套接字的处理,Node也应用到了异步I/O,网络套接字上侦听到的请求都会形成事件交给I/O观察者。事件循环会不停地处理这些网络I/O事件。
Node构建Web服务器,其流程图所示:
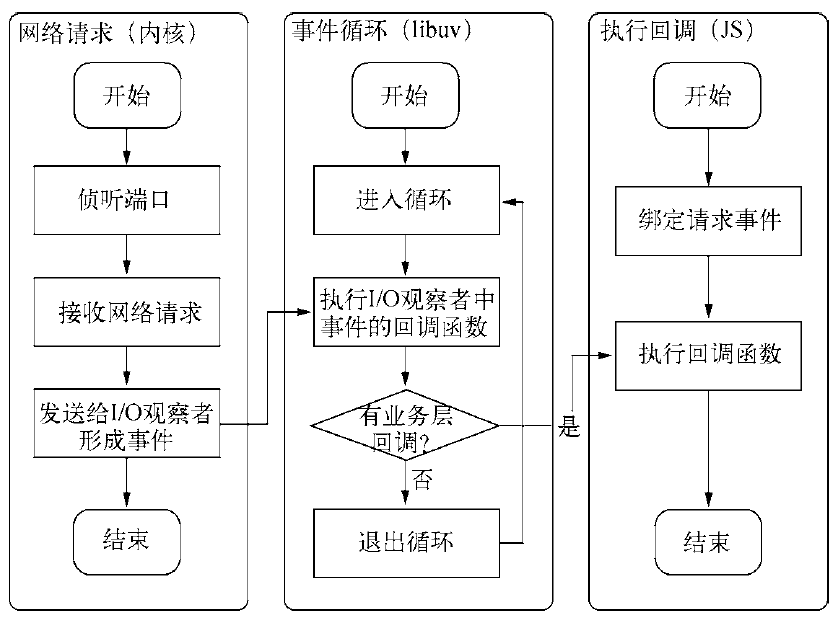
列举几种经典的服务器模型
- 同步式:一次只能处理一个请求,其余请求处于等待状态;
- 每进程/每请求:每个请求启动一个进程,虽可以处理多个请求,但不具备扩展性,系统资源有限;
- 每线程/每请求:每个请求启动一个线程,但是线程占用内存,当大并发请求时,内存会很快用光,导致服务器缓慢。
相比之下,每线程/每请求扩展性比每进程/每请求的方式要好一些
Apache采用的是每线程/每请求的方式,Node和Nginx则通过事件驱动的方式处理请求,无须为每个请求创建额外的对应线程,省掉创建和销毁线程的开销,同时操作系统在调度任务时,线程少上下文切换代价比较低。Nginx采用纯C写成,常用在反向代理或负载均衡
附一些其他知名的基于事件驱动的实现
Ruby的Event Machine
- Perl的AnyEvent
- Python的Twisted
总结
事件循环是异步实现的核心,与浏览器中的执行模型基本一致,Node自身实现一套完善的高性能异步I/O框架,打破了js在服务端止步不前的局面。
参考资源
- http://cnodejs.org/blog/?p=244
- http://cnodejs.org/blog/?p=2426
- http://cnodejs.org/blog/?p=2489
- http://nodejs.org/nodeconf.pdf
- http://blog.dccmx.com/2011/04/select-poll-epoll-in-kernel/
- http://www.ibm.com/developerworks/cn/linux/l-async/
- http://twistedmatrix.com/trac/
- http://luvit.io/
- http://forum.nginx.org/read.php?2,113524,113587#msg-113587














 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









