







主要内容转载自http://www.cnblogs.com/subconscious/p/4107357.html
1.一个故事说明什么是机器学习
机器学习这个词是让人疑惑的,首先它是英文名称Machine Learning(简称ML)的直译,在计算界Machine一般指计算机。这个名字使用了拟人的手法,说明了这门技术是让机器“学习”的技术。但是计算机是死的,怎么可能像人类一样“学习”呢?
传统上如果我们想让计算机工作,我们给它一串指令,然后它遵照这个指令一步步执行下去。有因有果,非常明确。但这样的方式在机器学习中行不通。机器学习根本不接受你输入的指令,相反,它接受你输入的数据! 也就是说,机器学习是一种让计算机利用数据而不是指令来进行各种工作的方法。这听起来非常不可思议,但结果上却是非常可行的。“统计”思想将在你学习“机器学习”相关理念时无时无刻不伴随,相关而不是因果的概念将是支撑机器学习能够工作的核心概念。你会颠覆对你以前所有程序中建立的因果无处不在的根本理念。
下面我通过一个故事来简单地阐明什么是机器学习。这个例子来源于我真实的生活经验,我在思考这个问题的时候突然发现它的过程可以被扩充化为一个完整的机器学习的过程,因此我决定使用这个例子作为所有介绍的开始。这个故事称为“等人问题”。
我相信大家都有跟别人相约,然后等人的经历。现实中不是每个人都那么守时的,于是当你碰到一些爱迟到的人,你的时间不可避免的要浪费。我就碰到过这样的一个例子。
对我的一个朋友小Y而言,他就不是那么守时,最常见的表现是他经常迟到。当有一次我跟他约好3点钟在某个麦当劳见面时,在我出门的那一刻我突然想到一个问题:我现在出发合适么?我会不会又到了地点后,花上30分钟去等他?我决定采取一个策略解决这个问题。
要想解决这个问题,有好几种方法。第一种方法是采用知识:我搜寻能够解决这个问题的知识。但很遗憾,没有人会把如何等人这个问题作为知识传授,因此我不可能找到已有的知识能够解决这个问题。第二种方法是问他人:我去询问他人获得解决这个问题的能力。但是同样的,这个问题没有人能够解答,因为可能没人碰上跟我一样的情况。第三种方法是准则法:我问自己的内心,我有否设立过什么准则去面对这个问题?例如,无论别人如何,我都会守时到达。但我不是个死板的人,我没有设立过这样的规则。
事实上,我相信有种方法比以上三种都合适。我把过往跟小Y相约的经历在脑海中重现一下,看看跟他相约的次数中,迟到占了多大的比例。而我利用这来预测他这次迟到的可能性。如果这个值超出了我心里的某个界限,那我选择等一会再出发。假设我跟小Y约过5次,他迟到的次数是1次,那么他按时到的比例为80%,我心中的阈值为70%,我认为这次小Y应该不会迟到,因此我按时出门。如果小Y在5次迟到的次数中占了4次,也就是他按时到达的比例为20%,由于这个值低于我的阈值,因此我选择推迟出门的时间。这个方法从它的利用层面来看,又称为经验法。在经验法的思考过程中,我事实上利用了以往所有相约的数据。因此也可以称之为依据数据做的判断,其与机器学习的思想根本上是一致的。
刚才的思考过程我只考虑“频次”这种属性。在真实的机器学习中,这可能都不算是一个应用。一般的机器学习模型至少考虑两个量:一个是因变量,也就是我们希望预测的结果,在这个例子里就是小Y迟到与否的判断。另一个是自变量,也就是用来预测小Y是否迟到的量。假设我把时间作为自变量,譬如我发现小Y所有迟到的日子基本都是星期五,而在非星期五情况下他基本不迟到。于是我可以建立一个模型,来模拟小Y迟到与否跟日子是否是星期五的概率。见下图:

这样的图就是一个最简单的机器学习模型,称之为决策树。
当我们考虑的自变量只有一个时,情况较为简单。如果把我们的自变量再增加一个。例如小Y迟到的部分情况时是在他开车过来的时候(你可以理解为他开车水平较臭,或者路较堵)。于是我可以关联考虑这些信息。建立一个更复杂的模型,这个模型包含两个自变量与一个因变量。再更复杂一点,小Y的迟到跟天气也有一定的原因,例如下雨的时候,这时候我需要考虑三个自变量。
如果我希望能够预测小Y迟到的具体时间,我可以把他每次迟到的时间跟雨量的大小以及前面考虑的自变量统一建立一个模型。于是我的模型可以预测值,例如他大概会迟到几分钟。这样可以帮助我更好的规划我出门的时间。在这样的情况下,决策树就无法很好地支撑了,因为决策树只能预测离散值。我们可以用线型回归方法建立这个模型。
如果我把这些建立模型的过程交给计算机。比如把所有的自变量和因变量输入,然后让计算机帮我生成一个模型,同时让计算机根据我当前的情况,给出我是否需要迟出门,需要迟几分钟的建议。那么计算机执行这些辅助决策的过程就是机器学习的过程。
机器学习方法是计算机利用已有的数据(经验),得出了某种模型(迟到的规律),并利用此模型预测未来(是否迟到)的一种方法。
通过上面的分析,可以看出机器学习与人类思考的经验过程是类似的,不过它能考虑更多的情况,执行更加复杂的计算。事实上,机器学习的一个主要目的就是把人类思考归纳经验的过程转化为计算机通过对数据的处理计算得出模型的过程。经过计算机得出的模型能够以近似于人的方式解决很多灵活复杂的问题。
下面,我会开始对机器学习的正式介绍,包括定义、范围,方法、应用等等,都有所包含。
2.机器学习的定义
从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
让我们把机器学习的过程与人类对历史经验归纳的过程做个比对。人类在成长、生活过程中积累了很多的历史与经验。人类定期地对这些经验进行“归纳”,获得了生活的“规律”。当人类遇到未知的问题或者需要对未来进行“推测”的时候,人类使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作。
机器学习中的“训练”与“预测”过程可以对应到人类的“归纳”和“推测”过程。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。由于机器学习不是基于编程形成的结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关性结论。
这也可以联想到人类为什么要学习历史,历史实际上是人类过往经验的总结。有句话说得很好,“历史往往不一样,但历史总是惊人的相似”。通过学习历史,我们从历史中归纳出人生与国家的规律,从而指导我们的下一步工作,这是具有莫大价值的。当代一些人忽视了历史的本来价值,而是把其作为一种宣扬功绩的手段,这其实是对历史真实价值的一种误用。
3.机器学习的范围
机器学习跟模式识别,统计学习,数据挖掘,计算机视觉,语音识别,自然语言处理等领域有着很深的联系。
从范围上来说,机器学习跟模式识别,统计学习,数据挖掘是类似的,同时,机器学习与其他领域的处理技术的结合,形成了计算机视觉、语音识别、自然语言处理等交叉学科。因此,一般说数据挖掘时,可以等同于说机器学习。同时,我们平常所说的机器学习应用,应该是通用的,不仅仅局限在结构化数据,还有图像,音频等应用。
在这节对机器学习这些相关领域的介绍有助于我们理清机器学习的应用场景与研究范围,更好的理解后面的算法与应用层次。
模式识别。模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。在著名的《Pattern Recognition And Machine Learning》这本书中,Christopher M. Bishop在开头是这样说的“模式识别源自工业界,而机器学习来自于计算机学科。不过,它们中的活动可以被视为同一个领域的两个方面,同时在过去的10年间,它们都有了长足的发展”。
数据挖掘。数据挖掘=机器学习+数据库。这几年数据挖掘的概念实在是太耳熟能详。几乎等同于炒作。但凡说数据挖掘都会吹嘘数据挖掘如何如何,例如从数据中挖出金子,以及将废弃的数据转化为价值等等。但是,我尽管可能会挖出金子,但我也可能挖的是“石头”啊。这个说法的意思是,数据挖掘仅仅是一种思考方式,告诉我们应该尝试从数据中挖掘出知识,但不是每个数据都能挖掘出金子的,所以不要神话它。一个系统绝对不会因为上了一个数据挖掘模块就变得无所不能(这是IBM最喜欢吹嘘的),恰恰相反,一个拥有数据挖掘思维的人员才是关键,而且他还必须对数据有深刻的认识,这样才可能从数据中导出模式指引业务的改善。大部分数据挖掘算法是机器学习的算法在数据库中的优化。
统计学习。统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。例如著名的支持向量机算法,就是源自统计学科。但是在某种程度上两者是有分别的,这个分别在于:统计学习者重点关注的是统计模型的发展与优化,偏数学,而机器学习者更关注的是能够解决问题,偏实践,因此机器学习研究者会重点研究学习算法在计算机上执行的效率与准确性的提升。
计算机视觉。计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。随着机器学习的新领域深度学习的发展,大大促进了计算机图像识别的效果,因此未来计算机视觉界的发展前景不可估量。
语音识别。语音识别=语音处理+机器学习。语音识别就是音频处理技术与机器学习的结合。语音识别技术一般不会单独使用,一般会结合自然语言处理的相关技术。目前的相关应用有苹果的语音助手siri等。
自然语言处理。自然语言处理=文本处理+机器学习。自然语言处理技术主要是让机器理解人类的语言的一门领域。在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法分析等等,除此之外,在理解这个层面,则使用了语义理解,机器学习等技术。作为唯一由人类自身创造的符号,自然语言处理一直是机器学习界不断研究的方向。按照百度机器学习专家余凯的说法“听与看,说白了就是阿猫和阿狗都会的,而只有语言才是人类独有的”。如何利用机器学习技术进行自然语言的的深度理解,一直是工业和学术界关注的焦点。
可以看出机器学习在众多领域的外延和应用。机器学习技术的发展促使了很多智能领域的进步,改善着我们的生活。
4.机器学习的方法
通过上节的介绍我们知晓了机器学习的大致范围,那么机器学习里面究竟有多少经典的算法呢?在这个部分我会简要介绍一下机器学习中的经典代表方法。这部分介绍的重点是这些方法内涵的思想,数学与实践细节不会在这讨论。
(1)回归算法
在大部分机器学习课程中,回归算法都是介绍的第一个算法。原因有两个:一.回归算法比较简单,介绍它可以让人平滑地从统计学迁移到机器学习中。二.回归算法是后面若干强大算法的基石,如果不理解回归算法,无法学习那些强大的算法。回归算法有两个重要的子类:即线性回归和逻辑回归。
线性回归就是我们前面说过的房价求解问题。如何拟合出一条直线最佳匹配我所有的数据?一般使用“最小二乘法”来求解。“最小二乘法”的思想是这样的,假设我们拟合出的直线代表数据的真实值,而观测到的数据代表拥有误差的值。为了尽可能减小误差的影响,需要求解一条直线使所有误差的平方和最小。最小二乘法将最优问题转化为求函数极值问题。函数极值在数学上我们一般会采用求导数为0的方法。但这种做法并不适合计算机,可能求解不出来,也可能计算量太大。
计算机科学界专门有一个学科叫“数值计算”,专门用来提升计算机进行各类计算时的准确性和效率问题。例如,著名的“梯度下降”以及“牛顿法”就是数值计算中的经典算法,也非常适合来处理求解函数极值的问题。梯度下降法是解决回归模型中最简单且有效的方法之一。从严格意义上来说,由于后文中的神经网络和推荐算法中都有线性回归的因子,因此梯度下降法在后面的算法实现中也有应用。
逻辑回归是一种与线性回归非常类似的算法,但是,从本质上讲,线型回归处理的问题类型与逻辑回归不一致。线性回归处理的是数值问题,也就是最后预测出的结果是数字,例如房价。而逻辑回归属于分类算法,也就是说,逻辑回归预测结果是离散的分类,例如判断这封邮件是否是垃圾邮件,以及用户是否会点击此广告等等。
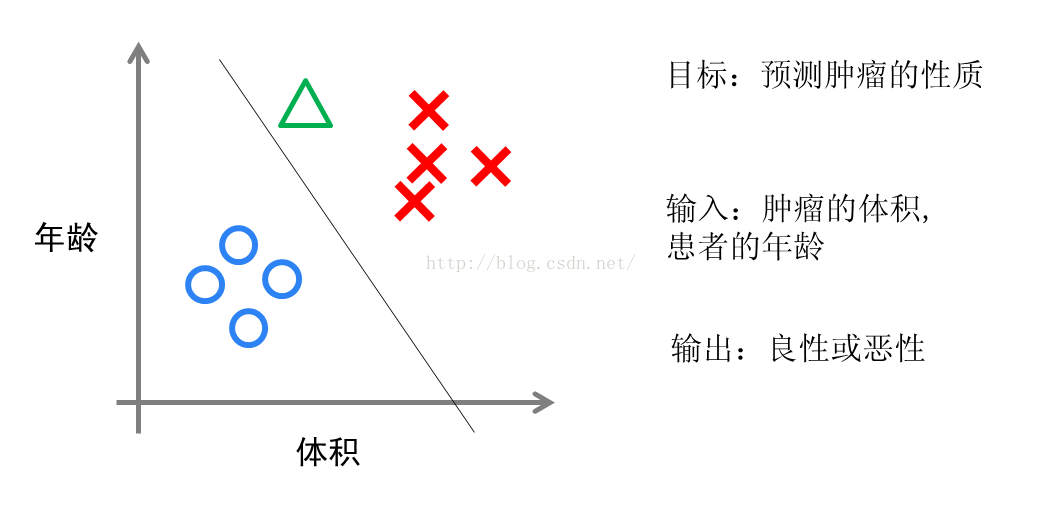
实现方面的话,逻辑回归只是对对线性回归的计算结果加上了一个Sigmoid函数,将数值结果转化为了0到1之间的概率(Sigmoid函数的图像一般来说并不直观,你只需要理解对数值越大,函数越逼近1,数值越小,函数越逼近0),接着我们根据这个概率可以做预测,例如概率大于0.5,则这封邮件就是垃圾邮件,或者肿瘤是否是恶性的等等。从直观上来说,逻辑回归是画出了一条分类线,见下图。
(5)降维算法
降维算法也是一种无监督学习算法,其主要特征是将数据从高维降低到低维层次。在这里,维度其实表示的是数据的特征量的大小,例如,房价包含房子的长、宽、面积与房间数量四个特征,也就是维度为4维的数据。可以看出来,长与宽事实上与面积表示的信息重叠了,例如面积=长 × 宽。通过降维算法我们就可以去除冗余信息,将特征减少为面积与房间数量两个特征,即从4维的数据压缩到2维。于是我们将数据从高维降低到低维,不仅利于表示,同时在计算上也能带来加速。
刚才说的降维过程中减少的维度属于肉眼可视的层次,同时压缩也不会带来信息的损失(因为信息冗余了)。如果肉眼不可视,或者没有冗余的特征,降维算法也能工作,不过这样会带来一些信息的损失。但是,降维算法可以从数学上证明,从高维压缩到的低维中最大程度地保留了数据的信息。因此,使用降维算法仍然有很多的好处。
降维算法的主要作用是压缩数据与提升机器学习其他算法的效率。通过降维算法,可以将具有几千个特征的数据压缩至若干个特征。另外,降维算法的另一个好处是数据的可视化,例如将5维的数据压缩至2维,然后可以用二维平面来可视。降维算法的主要代表是PCA算法(即主成分分析算法)。
(6)推荐算法
推荐算法是目前业界非常火的一种算法,在电商界,如亚马逊,天猫,京东等得到了广泛的运用。推荐算法的主要特征就是可以自动向用户推荐他们最感兴趣的东西,从而增加购买率,提升效益。推荐算法有两个主要的类别:
一类是基于物品内容的推荐,是将与用户购买的内容近似的物品推荐给用户,这样的前提是每个物品都得有若干个标签,因此才可以找出与用户购买物品类似的物品,这样推荐的好处是关联程度较大,但是由于每个物品都需要贴标签,因此工作量较大。
另一类是基于用户相似度的推荐,则是将与目标用户兴趣相同的其他用户购买的东西推荐给目标用户,例如小A历史上买了物品B和C,经过算法分析,发现另一个与小A近似的用户小D购买了物品E,于是将物品E推荐给小A。
两类推荐都有各自的优缺点,在一般的电商应用中,一般是两类混合使用。推荐算法中最有名的算法就是协同过滤算法。
(7)其他算法
除了以上算法之外,机器学习界还有其他的如高斯判别,朴素贝叶斯,决策树等等算法。但是上面列的六个算法是使用最多,影响最广,种类最全的典型。机器学习界的一个特色就是算法众多,发展百花齐放。
下面做一个总结,按照训练的数据有无标签,可以将上面算法分为监督学习算法和无监督学习算法,但推荐算法较为特殊,既不属于监督学习,也不属于非监督学习,是单独的一类。
监督学习算法:线性回归,逻辑回归,神经网络,SVM
无监督学习算法:聚类算法,降维算法
特殊算法:推荐算法
除了这些算法以外,有一些算法的名字在机器学习领域中也经常出现。但他们本身并不算是一个机器学习算法,而是为了解决某个子问题而诞生的。你可以理解他们为以上算法的子算法,用于大幅度提高训练过程。其中的代表有:梯度下降法,主要运用在线型回归,逻辑回归,神经网络,推荐算法中;牛顿法,主要运用在线型回归中;BP算法,主要运用在神经网络中;SMO算法,主要运用在SVM中。
5.机器学习的子类——深度学习
近来,机器学习的发展产生了一个新的方向,即“深度学习”。虽然深度学习这四字听起来颇为高大上,但其理念却非常简单,就是传统的神经网络发展到了多隐藏层的情况。
在上文介绍过,自从90年代以后,神经网络已经消寂了一段时间。但是BP算法的发明人Geoffrey Hinton一直没有放弃对神经网络的研究。由于神经网络在隐藏层扩大到两个以上,其训练速度就会非常慢,因此实用性一直低于支持向量机。2006年,Geoffrey Hinton在科学杂志《Science》上发表了一篇文章,论证了两个观点:1.多隐层的神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类;2.深度神经网络在训练上的难度,可以通过“逐层初始化” 来有效克服。
通过这样的发现,不仅解决了神经网络在计算上的难度,同时也说明了深层神经网络在学习上的优异性。从此,神经网络重新成为了机器学习界中的主流强大学习技术。同时,具有多个隐藏层的神经网络被称为深度神经网络,基于深度神经网络的学习研究称之为深度学习。
由于深度学习的重要性质,在各方面都取得极大的关注,按照时间轴排序,有以下四个标志性事件值得一说:
2012年6月,《纽约时报》披露了Google Brain项目,这个项目是由Andrew Ng和Map-Reduce发明人Jeff Dean共同主导,用16000个CPU Core的并行计算平台训练一种称为“深层神经网络”的机器学习模型,在语音识别和图像识别等领域获得了巨大的成功。Andrew Ng就是文章开始所介绍的机器学习的大牛。
2012年11月,微软在中国天津的一次活动上公开演示了一个全自动的同声传译系统,讲演者用英文演讲,后台的计算机一气呵成自动完成语音识别、英中机器翻译,以及中文语音合成,效果非常流畅,其中支撑的关键技术是深度学习;
2013年1月,在百度的年会上,创始人兼CEO李彦宏高调宣布要成立百度研究院,其中第一个重点方向就是深度学习,并为此而成立深度学习研究院(IDL)。
2013年4月,《麻省理工学院技术评论》杂志将深度学习列为2013年十大突破性技术(Breakthrough Technology)之首。
深度学习属于机器学习的子类。基于深度学习的发展极大的促进了机器学习的地位提高,更进一步地,推动了业界对机器学习父类人工智能梦想的再次重视。














 5387
5387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









