






// AppInventor2开发的App上架步骤 //
apk不报病毒,通过腾讯管家检测是App上架的第一步。当然,上架的App是需要申请软件著作权(软著)证书,如何申请这个后续会介绍,本文暂时略过。
AppInventor2中文网.apk已通过腾讯管家检测,不再报病毒
其次包名也很重要,是整个应用市场唯一的标识符,工信部备案也需要:
其次上架必须准备一个《隐私政策》在线网页url,告知用户你如何访问及访问隐私权限的用途,包括相机、存储、定位等权限。App中用到的权限都需要在网页中有明确的说明,如果App有消息推送功能,也需要说明,并且必须在App的设置中有关闭推送的开关选项,否则无法通过审核!
这个隐私政策网页可以参考其他app的,可以使用AI来写,然后自己细化一下,App权限说明相关的地方一定要详细说明,其他的倒是比较常规,大家都大同小异。
// AppInventor2隐私政策拓展 //
弹窗效果
比如我们的隐私政策网页url:https://www.fun123.cn/static/privacy_policy.html,一个代码块搞定:

效果如下:

用户点击“同意”才能正常进入App,否则直接退出App。
用户同意之后,会记住这个状态,后续就不再弹窗提醒。App升级不会重置这个状态,只有在App卸载后重新安装,才能重新提醒。
如果用户点“不同意”则48小时内(工信部规定)不允许再请求任何权限,弹窗提醒用户手动在设置中开启权限。这个逻辑我们也做进了拓展中。
隐私政策网页
如果有自己的网站那是最好,没有的话一般采用托管的方式:
| 托管平台 | 特点 | 推荐指数 |
| Notion | 免费 | ★★★★☆ |
| github.io | 免费,但国内访问可能不太稳定 | ★★★★ |
| 国内云厂商OSS | 存储白菜价,流量费约 0.5元/GB,各家价格都大差不差,访问速度非常快 | ★★★★ |
| coding.net | 静态页0.06元/月 | ★★ |
| 各App上架平台的云托管 | 收费 | ★ |
| gitee.io | 免费,但已停止服务 | ☆ |
不仅如此,还需要在App界面上显式提供“隐私政策”的链接,用户可以随时点击查看,参考如下:
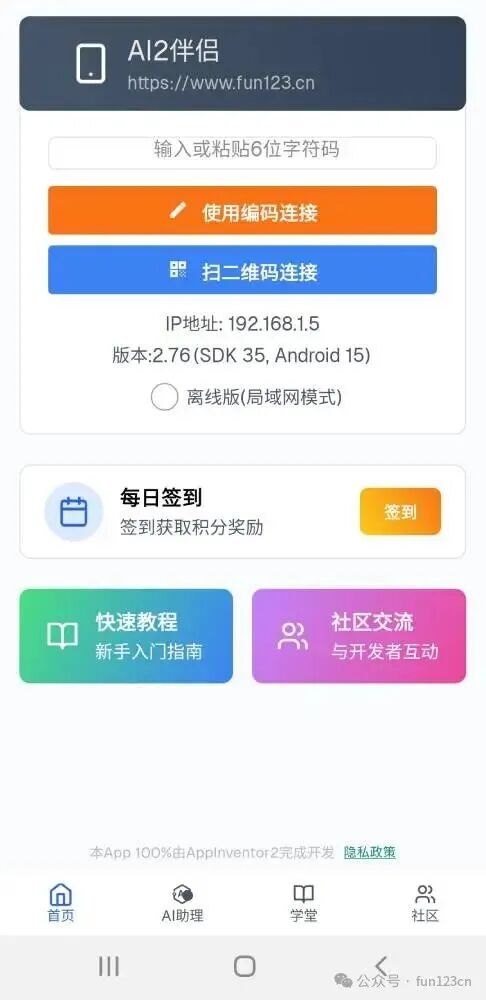
以上介绍了App上架时“隐私政策”相关的审核点,为了保护用户的隐私,可以说是相当的严格,不过这些复杂的审核点我们都已经封装到拓展中了,一个代码块就能搞定!
除此之外,后续还有其他的步骤及审核卡点,持续更新中~
原文:https://www.fun123.cn/reference/extensions/PrivacyPolicyAI2Ext.html


















 9678
9678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











