




 本文探讨了深度学习中常见的过拟合问题及其解决方案,详细介绍了Dropout正则化技术如何通过创建网络的子集来改善模型泛化能力,同时讨论了随机梯度下降和Mini-batch梯度下降在训练过程中的作用。
本文探讨了深度学习中常见的过拟合问题及其解决方案,详细介绍了Dropout正则化技术如何通过创建网络的子集来改善模型泛化能力,同时讨论了随机梯度下降和Mini-batch梯度下降在训练过程中的作用。
1.增加数据量 成千上万的数据
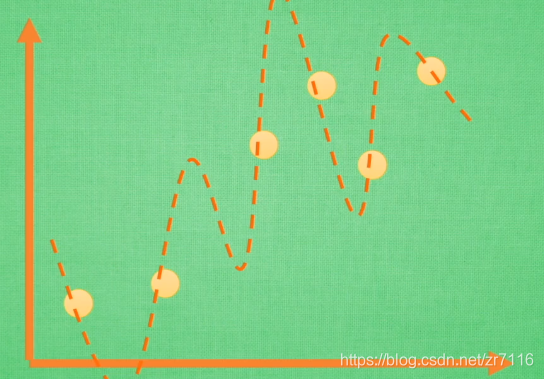

2.正规化 =》适用大多数机器学习 包括神经网络


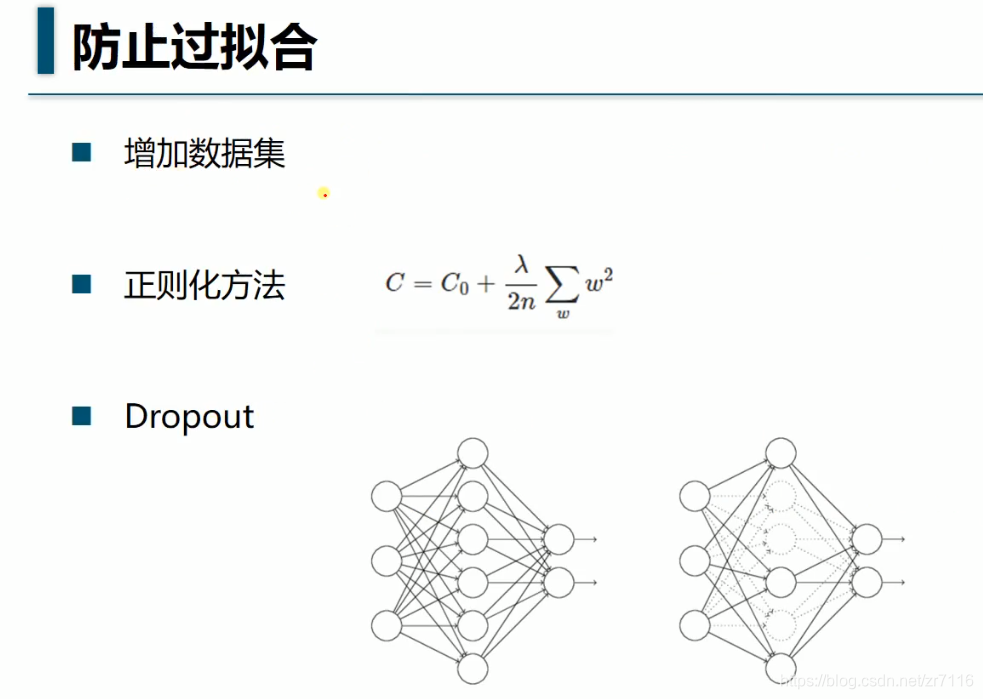
==》神经网络中的正规化Dropout regularization 暂时随机忽略神经元与神经的连接==》使神经网络变的不完整
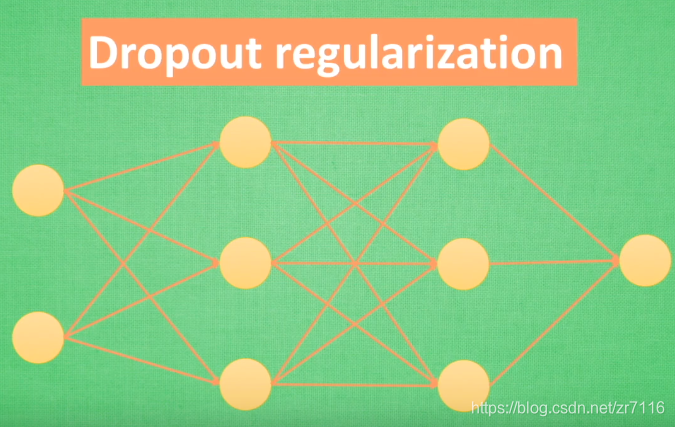
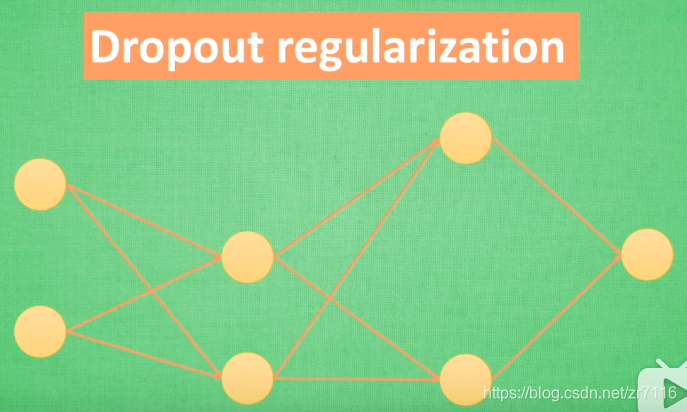
过拟合是很多机器学习的通病,过拟合了,得到的模型基本就废了。==》而为了解决过拟合问题,一般会采用ensemble方法,即训练多个模型做组合==》此时,费时就成为一个大问题,不仅训练起来费时,测试起来多个模型也很费时。
怎么解决=》,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,hit不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
怎么解决=》Dropout的出现很好的可以解决这个问题,每次做完dropout,相当于从原始的网络中找到一个更
瘦的网络,对于一个有N个节点的神经网络,有了dropout后,就可以看做是2n次方个模型的集合了,但此时要训练的参数数目却是不变的,这就解脱了费时的问题
就是下面的完整介绍:
Mini-batch 和batch的区别==>https://blog.csdn.net/weixin_39502247/article/details/80032487
深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。
第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算量开销大,计算速度慢,不支持在线学习,这称为Batch gradient descent,批梯度下降。
另一种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,hit不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
理解dropout=> https://blog.csdn.net/stdcoutzyx/article/details/49022443
另一种dropoutMaxout网络学习==> https://blog.csdn.net/hjimce/article/details/50414467


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









