







环境安装可以查看这个blog https://blog.csdn.net/zhuyiquan/article/details/79537623
首先我们要爬取的网站是:https://www.qimai.cn/rank/release
而需要的数据是
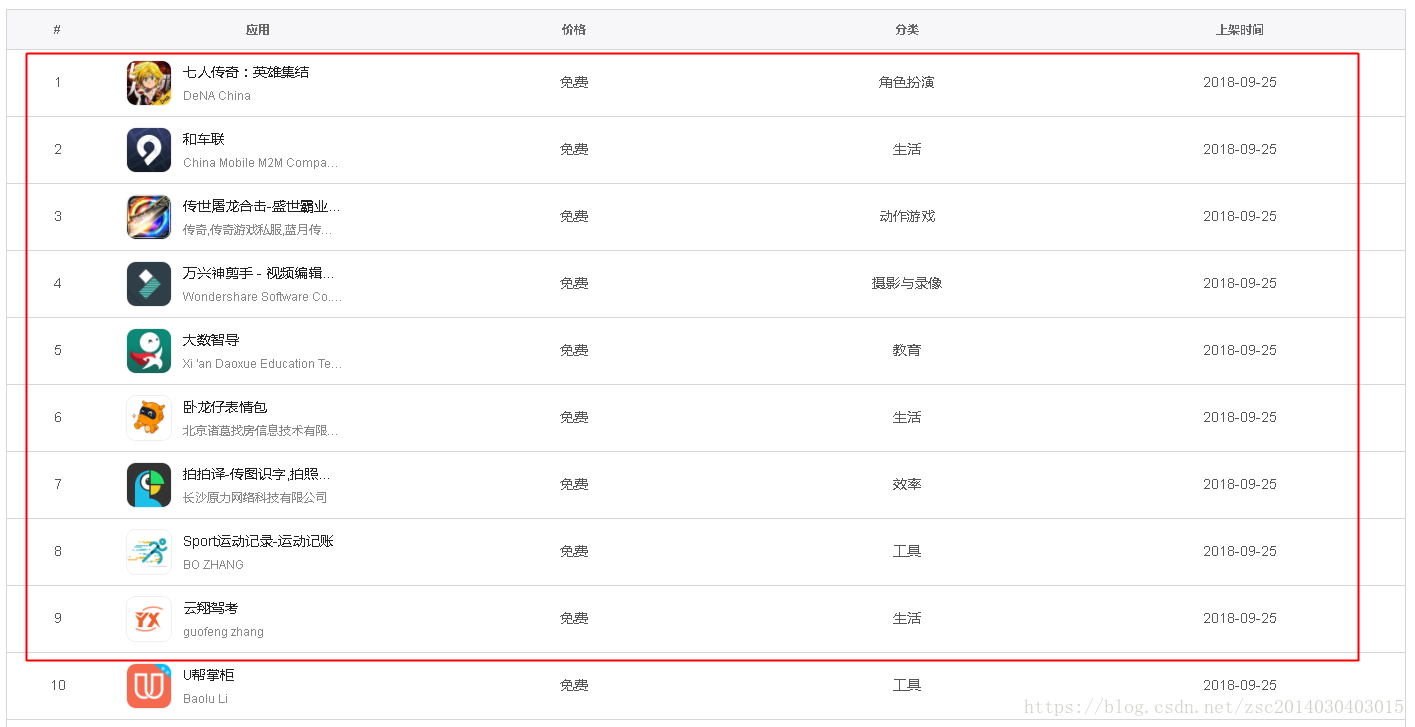
然而当你不断向下滑动的时候,你会发现它还会有异步请求数据(这个要在你登录之后才有,没登录只能看见200条数据)。
所以现在的问题已经浮现出来了
- 要模拟登录这个网站
- 模拟浏览器滚动到底部,然后等待ajax返回数据并且判断是否已经无数据更新
- 数据保存到数据库
- 第一步我们首先将登录做好先
#cookie路径
cookiePath = './cookie/qimai.ck'
#网站登录url
loginUrl = 'https://www.qimai.cn/account/signin/r/%2Faccount%2F'
#这里是账号和密码的input输入框xpath路径
xpath = {
0:['//*[@id="app"]/div[2]/div/div/form/div[1]/div/div[1]/input','账号'],
1:['//*[@id="app"]/div[2]/div/div/form/div[2]/div/div/input','密码']
}
#这个是提交按钮的xpath路径
xbutton = ['//*[@id="app"]/div[2]/div/div/form/div[4]/div/button']
#标记是否要重新请求cookie
flag = 0
#这里做一个死循环,直到登录成功后才跳出,不然就重新请求登录获取新cookie
while True:
cookies = Cookie.get_cookie(flag=flag,driver=driver,path=cookiePath,loginUrl=loginUrl,xpath=xpath,xbutton=xbutton)
print(cookies)
time.sleep(3)
driver.get 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1938
1938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









